

Языкипрограммирования иметоды трансляции (2 часть)
1. Формальные языки и грамматики
1.1. Основные понятия
Для общения с компьютерами разрабатываются специальные языки, которые называются искусственными в отличие от естественных языков общения людей. Искусственные языки должны быть, с одной стороны, удобными и понятными для человека, а с другой - должны восприниматься устройствами. Совмещение этих требований в одном языке является трудной задачей, поэтому применяются средства для преобразования текстов с языка, понятного человеку, на язык устройства. Такие средства называются транслято-
рами.
1.1.1. Трансляторы, интерпретаторы и компиляторы
Транслятор может быть интерпретирующего или компилирующего типа. В первом случае его называют интерпретатором входного языка, а во втором - компилятором.
Интерпретатор последовательно читает предложения входного языка, анализирует их и сразу выполняет. Компилятор не выполняет предложения языка, а строит программу, которая может в дальнейшем быть запущена для получения результата.
На вход компилятора подается текст, написанный на языке понятном человеку, а результате работы компилятора создается текст на языке, удобном для устройства.
1.1.2. Стадии работы компилятора
Работа компилятора состоит из нескольких стадий, которые могут выполняться последовательно, либо совмещаться по времени. Эти стадии представлены в виде следующей схемы.
1
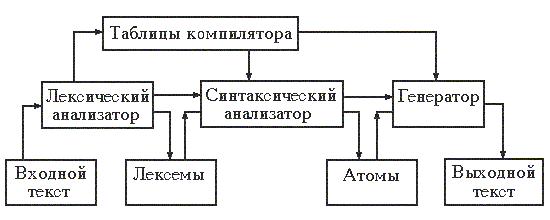
Первая стадия работы компилятора называется лексическим анализом, а программа, её реализующая, - лексическим анализатором (ЛА). На вход лексического анализатора подаётся последовательность символов входного языка. ЛА выделяет в этой последовательности простейшие конструкции, которые называются лексическими единицами. Примерами лексических единиц являются идентификаторы, числа, символы операций, служебные слова и т.д. ЛА преобразует исходный текст, заменяя лексические единицы их внутренним представлением - лексемами. Лексема может включать информацию о классе лексической единицы и её значении. Кроме того, для некоторых классов лексических единиц ЛА строит таблицы, например, таблицу идентификаторов, констант, которые используются на последующих стадиях компиляции.
Вторую стадию работы компилятора называют синтаксическим анализом, а соответствующую программу - синтаксическим анализатором (СА). На вход СА подается последовательность лексем, которая преобразуется в промежуточный код, представляющий собой последовательность символов действия или атомов. Каждый атом включает описание операции, которую нужно выполнить, с указанием используемых операндов. При этом последовательность расположения атомов, в отличие от лексем, соответствует порядку выполнения операций, необходимому для получения результата.
На третьей стадии работы компилятора осуществляется построение выходного текста. Программа, реализующая эту стадию, называется генератором выходного текста (Г). Генератор каждому символу действия, поступающему на его вход, ставит в соответствие одну или несколько команд выходного языка. В качестве выходного языка могут быть использованы команды устройства, команды ассемблера, либо операторы какого-либо
другого языка.
2