

Методы тестирования программ
Статистическое тестирование – формальный анализ текста программы на языке программирования. Операторы и операнды анализируются в символьном виде, поэтому метод иногда называют символическим тестированием.
Детерминированное тестирование – требует многократного выполнения программы на ЭВМ с использованием специальных тестовых наборов данных. Контролируется каждая комбинация исходных данных, результаты и каждое утверждение из спецификации программы. Трудоемко, поэтому применяется для отдельных модулей или небольших ПП.
Стохастическое тестирование – перебрать все варианты невозможно, поэтому используется множество случайных величин с соответствующими распределениями, для сравнения результатов также используются распределения случайных величин. Применяется для обнаружения ошибок перед детерминированным тестированием. Стохастическое тестирование лучше всего подвержено автоматизации (применяются генераторы случайных чисел).
Тестирование в реальном масштабе времени – применяется для систем реального времени: проверяются результаты обработки исходных данных с учетом времени их поступления динамики, использования памяти, длительности и приоритетности обработки, взаимодействия с другими программами. При обнаружении отклонений переходят к детерминированному тестированию.
Каждый метод не исключает (предполагает) использование других методов.
Статическое тестирование - производят с использованием ручных методов (по данным IBM определяются 30 – 80% ошибок). Собирается собрание, цель которого ‑ обнаружение ошибок, но не их устранение. Процедура статистического тестирования включает инспекцию исходного текста с применением набора правил и приемов обнаружения ошибок. Обычно группа состоит из 4-х человек: руководитель группы (не автор), автор, проектировщик и специалист по тестированию.
Текст раздается заранее – листинг программы и внешние спецификации.
Методы проектирования тестовых наборов данных
Наиболее эффективным является детерминированное тестирование, при котором известны и контролируются каждая комбинация исходных данных и соответствующие ей результаты исполнения программы.
Структурное тестирование – на основе детального изучения текстов программы (логики) подбираются такие входные данные, которые позволяют при многократном повторении выполнения программы на ЭВМ обеспечить выполнение максимально возможного количества маршрутов, ветвлений, т. е. вариантов выполнения.
Функциональное тестирование – тестирование по “входу-выходу”, абстрагируется от логики программы. Исходная информация для тестирования – функциональные спецификации.
Понятие “эффективного” тестового набора данных связано с невозможностью полного перебора вариантов. Пример: имеем графическое изображение передачи управления на участке программы (рисунок 9), который выполняется в цикле 20 раз.
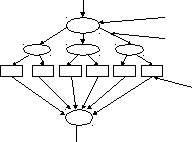
Линейный участок программы, заканчивается ветвлением.
Дуги – варианты передачи управления.
Шесть блоков.
Рисунок 9 - Передача управления на участке программы
Всего количество тестов для участка N=6*20=120, если выполнение каждой ветви исключает выполнение других ветвей.
Исчерпывающее тестирование для сложных программ при ограничениях на время, стоимость, машинное время невозможно. Подмножество всех возможных текстов, которое имеет наивысшую вероятность обнаружения большинства ошибок, называется эффективным.
Рассмотрим узел ветвления, в котором заданы два условия (рисунок 10).
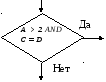
Рисунок
10 – Узел ветвления
с двумя условиями
Для прохода по ветвям «Да» и «Нет» достаточно реализовать два варианта данных, например:
а) A > 2 ; C = D; Значения переменных: A = 3; C =0; D=0;
б) A <= 2; C D; Значения переменных: A = 2; C= 0; D=1.
Рассмотрены не все возможные варианты, поэтому возможны ошибки при контроле логики.
Структурное тестирование (“белый ящик”) – при разработке тестовых наборов данных руководствуются следующими критериями:
Покрытие операторов – тестовый набор вызывает выполнение каждого оператора в программе хотя бы один раз. Критерий слабый, недостаточное условие тестирования.
Покрытие узлов ветвления- (покрытие ветвлений) – разработка такого тестового набора, который обеспечивает переход по веткам “истина” и “ложь” в каждом узле ветвления хотя бы один раз (пример приведен выше).
Покрытие условий - если узел ветвления содержит более одного условия, то каждое условие должно быть выполнено хотя бы один раз в каждой точке входа в программу.
Комбинаторное покрытие условий– аналогично предыдущему, но используются все возможные варианты:
а) А > 2; C = D; Значения переменных: A = 3; C = 0; D = 0;
б) А > 2; C D; A = 3; C = 0; D = 1;
в) A 2; C = D; A = 2; C = 1; D = 1;
г) A 2; C D; A = 2; C = 1; D = 0.
Функциональное тестирование («черный ящик»). К стратегии функционального тестирования относятся следующие три метода.
1 Метод эквивалентного разбиения – построение тестов производят в два этапа:
а) выделение классов эквивалентности (КЭ);
б) построение тестов.
Класс эквивалентности – множество входных значений, имеющих равную вероятность обнаружения конкретного типа ошибок. Выделяются путем анализа входных условий (данных) и разбиения их на две и более групп, которые сводятся в таблицу (табл. 4). Одна группа – правильный КЭ, другие – неправильные КЭ. При этом возможны следующие варианты:
а) если входное условие описывает область значений от … до …, то определяется один правильный КЭ и два неправильных КЭ (больше и меньше предельных значений);
б) если входное условие описывает множество возможных значений, то КЭ определяется по одному для каждого возможного значения (правильный и неправильный КЭ);
в) если входное условие описывает ситуацию «должно быть», то определяется один правильный КЭ и один неправильный КЭ.
Таблица используется для построения тестовых наборов. Для правильных КЭ выбирается минимальное количество тестовых наборов данных. Для каждого неправильного КЭ строится хотя бы один тестовый набор.
Таблица 4 - Входные условия (данные) и классы эквивалентности (КЭ)
|
Входные условия (данные) |
Правильные КЭ |
Неправильные КЭ |
|
Идентификатор (Ид): должен быть < = 8 символов. Пример: AB, ABSTRACIN 1. |
1 < Ид <= 8 |
|
|
Способ передачи информации: Почтовый – 1; Телеграфный – 2. |
|
Телеграфный – 3. |
|
Первый символ – буква: А1, _А, 1А, &Б. |
Первый символ:
|
Первый символ:
|
2 Анализ граничных значений – предполагает исследование граничных ситуаций применительно к правильным областям значений. Например, если область значений от –1.0 до +1.0, то нужны тесты –1.0; +1.0 ; - 1.001; +1.001.
3 Метод функциональных диаграмм – входная спецификация программы с помощью простейших булевских отношений преобразуется в диаграмму причинно-следственных связей, производится построение таблицы решений (методом обратной трассировки). Таким образом, создается основа для составления эффективных тестовых наборов данных.