

Глава 4. Кластерный и дискриминантный анализ
4.1. Классификация семей по анализируемой структуре расходов
По данным, представленным в табл. 4.1, провести классификацию n=5 семей по двум показателям: уровень расходов (млн.руб.) за летние месяцы на культурные нужды, спорт и отдых -х(1)и питаниех(2):
Таблица 4.1.
|
№ семьи (i) |
1 |
2 |
3 |
4 |
5 |
|
хi(1) |
2 |
4 |
8 |
12 |
13 |
|
xi(2) |
10 |
7 |
6 |
11 |
9 |
Классификацию провести по иерархическому агломеративному алгоритму с использованием обычного и взвешенного (w1=0,05;w2=0,95) евклидова расстояния, а также принципов: “ближайшего” и “дальнего” соседа, центра тяжести и средней связи.
Сравнить полученные результаты и обосновать выбор окончательного варианта классификации.
Примечание:На основании предварительного качественного анализа было выдвинуто предположение, что по потребительскому поведению три первые семьи принадлежат одной типологической группе, а две последние (4 и 5) - другой, что согласуется с расположением пяти наблюдений на плоскости, представленных на рис.4.1.
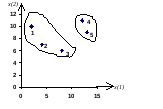
Рис.4.1. Исходные данные для классификации
Решение. 1. Проведем классификацию, выбрав при обычном евклидовом расстоянии принцип “ближайшего соседа”.
Согласно обычной евклидовой метрике расстояние между наблюдениями 1 и 2 равно
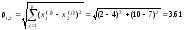 , (4.1)
, (4.1)
очевидно, что 1,1=0.
Аналогично находим расстояния между всеми пятью наблюдениями и строим матрицу расстояний
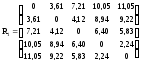 .
.
Из матрицы расстояний следует, что объекты 4 и 5 наиболее близки 4,5=2,24 и поэтому объединим их в один кластер. После объединения объектов имеем четыре кластера: S1, S2, S3, S(4,5).
Расстояние между кластерами будем находить по принципу “ближайшего соседа”, воспользовавшись формулой пересчета. Так расстояние между кластером S1и кластером S(4,5)равно:
 (4.2)
(4.2)
Мы видим, что расстояние 1,(4,5)равно расстоянию от объекта 1 до ближайшего к нему объекта, входящего в кластер S(4,5), т.е.1,(4,5)=1,4=10,05. Проводя аналогичные расчеты, получим матрицу расстояний
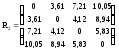 .
.
Объединим наблюдения 1 и 2, имеющие наименьшее расстояние 1,2=3,61. После объединения имеем три кластера S(1,2), S3и S(4,5).
Вновь строим матрицу расстояний. Для этого необходимо рассчитать расстояние до кластера S(1,2). Воспользуемся матрицей расстояний R2.
Например, расстояние между кластерами S(4,5)и S(1,2)равно:
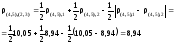
Как видим, оно равно расстоянию от кластера S(4,5)до ближайшего объекта, входящего в кластер S(1,2), то есть(4,5),(1,2)=(4,5),2=8,94.
Проведя аналогичные расчеты, получим матрицу расстояний
 .
.
Объединим кластеры S(1,2)и S(3), расстояние между которыми, согласно матрице R3, минимально(1,2),3=4,12. В результате этого получим два кластера: S(1,2,3)и S(4,5). Матрица расстояний будет иметь вид:
 .
.
Из матрицы R4следует, что на расстоянии(1,2,3),(4,5)=5,83 все пять наблюдений объединяются в один кластер. Результаты кластерного анализа представим графически в виде дендрограммы (рис.4.2).

Рис. 4.2. Дендрограмма (обычное евклидово расстояние, ближайший сосед)
На основании графического представления результатов кластерного анализа (рис.4.2) можно сделать вывод, что наилучшим является разбиение пяти регионов на два кластера: S(1,2,3)и S(4,5), когда пороговое расстояние находится в интервале 4,12<пор<5,83.
Напомним, что выводы нами сделаны для случая, когда для измерения расстояния выбрано “обычное евклидово расстояние” и принцип “ближайшего соседа”.
2. Проведем классификацию, выбрав при обычном евклидовом расстоянии принцип “дальнего соседа”.
Как и в случае (1), мы используем обычное евклидово расстояние, поэтому матрица R1остается без изменения. Согласно агломеративному алгоритму объединяются в один кластер объекты 4 и 5, как наиболее близкие4,5=2,24. После объединения имеем четыре кластера: S1, S2, S3и S(4,5).
В виду того, что расстояние между кластерами измеряем по принципу “дальнего соседа”, то воспользуемся формулой пересчета, приняв =1/2, а не ‑1/2, как в случае (1). Тогда, например, расстояние между кластером S1и кластером S(4,5)определяется по формуле:
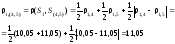 ,
,
Таким образом, расстояние 1,(4,5)равно расстоянию от объекта 1 до наиболее отдаленного от него объекта, входящего в кластер S(4,5), то есть1,(4,5)=1,5=11,05.
Аналогично рассматриваются все остальные элементы матрицы расстояния
 .
.
Объединим объекты 1 и 2 в один кластер, как наиболее близкие (согласно матрице R2),1,2=3,61.
После объединения имеем три кластера: S(1,2), S3и S(4,5).
Строим матрицу расстояний R3, воспользовавшись принципом “дальнего соседа”.
 .
.
Объединим
кластеры S3 и S(4,5), расстояние
между которыми3,(4,5)=6,40
минимально, и получим два кластера:
S(1,2)и S(3,4,5), расстояние между
которыми определяется по матрице и равно(1,2),(3,4,5)=11,05.
и равно(1,2),(3,4,5)=11,05.
Графические результаты классификации представлены на рис.4.3.

Рис.4.3 Дендрограмма (обычное евклидово расстояние, дальний сосед)
Как и в предыдущем случае наилучшим является разбиение регионов на два кластера (рис. 4.3): S(1,2) и S(3,4,5), после предпоследнего шага классификации, когда интервал измерения расстояния объединения наибольший 6,40пор11,05.
Таким образом, используя принцип “дальнего соседа” мы получили разбиение регионов на два кластера S(1,2) и S(3,4,5), которое отличается от разбиения по принципу “ближайшего соседа”: S(1,2,3) и S(4,5).
3. Классификация на основе обычного евклидова расстояния и принципа “ центра тяжести”.
Так как мы используем обычное евклидово расстояние, то матрица R1остается без изменения. Согласно агломеративному алгоритму объединяются в кластер S(4,5)объекты 4 и 5, как наиболее близкие4,5=2,24.
Кластер
S(4,5)характеризуется в дальнейшем
его центром тяжести, определяемым
вектором средних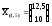 .
.
Расстояние от этого кластера до первого наблюдения равно:
 .
.
Тогда матрица расстояний примет вид:
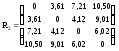
Объединим
объекты 1 и 2, расстояние между которыми
1,2=3,61
минимальное. Кластер характеризуется
центром тяжести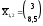 ,
расстояния от которого до кластера
S(4,5)равно:
,
расстояния от которого до кластера
S(4,5)равно:
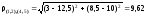
Тогда матрица расстояний примет вид:
 .
.
В
матрице R3минимальное
расстояние(1,2),3=5,59,
поэтому образуем кластер S(1,2,3)и определим его вектор средних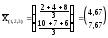 .
.
Найдем расстояние между S(1,2,3)и S(4,5)
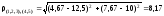
на котором все пять объектов объединяются в один кластер. Графически результаты классификации представлены на рис. 4.4

Рис.4.4 Дендрограмма (обычное евклидово расстояние, принцип “центра тяжести”)
Из рис. 4.4 видно, что наибольший скачок в расстояниях объединения имеет место на последнем шаге, поэтому целесообразно выбрать разбиение на два кластера S(1,2,3)и S(4,5), что совпадает со случаем (1).
4.Классификация на основе обычного евклидова расстояния и принципа “средней связи”.
Используя матрицу R1, согласно агломеративному алгоритму объединим кластеры S4и S5в один S(4,5), так как расстояние между ними4,5=2,24‑минимально.
Расстояние от кластера S(4,5)до остальных кластеров определим по принципу “средней связи” на основе матрицыR1. Например:
 .
.
Тогда матрица расстояний имеет вид:
 .
.
Объединим, как наиболее близкие 1,2=3,61, кластеры S1и S2. Тогда расстояния от S(1,2)до остальных кластеров S(4,5) равна:
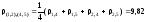 ,
,
а матрица расстояний имеет вид:

Объединим, как наиболее близкие (1,2),3=5,41, кластеры S(1,2)и S3 и определим расстояния от S(1,2,3)до S(4,5)
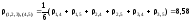
на котором все пять объектов объединились в один кластер. Графически результаты классификации представлены на рис. 4.5

Рис.4.5 Дендрограмма (обычное евклидово расстояние, принцип средней связи)
Из рис. 4.5 следует, что целесообразным является разбиение на два кластера S(1,2,3)и S(4,5).
Таким образом, сравнивая результаты 4-х разбиений пяти регионов на однородные группы, можно отметить, что наиболее устойчивым, а отсюда и предпочтительным, является разбиение на два кластера S(1,2,3)и S(4,5), что согласуется с рис. 4.1. Только в одном случае из четырех, при использовании принципа “дальнего соседа” получено разбиение S(1,2)и S(3,4,5).
Во всех предыдущих алгоритмах классификации мы предполагали, что оба показателя х(1)их(2)одинаково значимы (использовалось обычное евклидово расстояние). Теперь откажемся от этого предположения.
5. Классификация на основе “взвешенного евклидова расстояния” и принципа “ближайшего соседа”.
Предположим, что показатель х(1)менее важен для классификации, чемх(2). В этой связи припишем им “веса”1=0,05 и2=0,9. Напомним, что взвешенное евклидово расстояние междуi-м иl-м наблюдениями определяется по формуле:
 . (4.3)
. (4.3)
Тогда расстояние между объектами 1 и 2 равно:
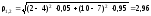 .
.
Аналогично находим все остальные расстояния и строим матрицу расстояний:
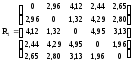 .
.
Объединив S2и S3, имеющих минимальное расстояние2,3=1,32 в кластер S2,3, и применив принцип “ближайшего соседа”, получим матрицу расстояний:
 .
.
Образовав на расстоянии 4,5=1,96 кластер S4,5вновь построим матрицу расстояний:

Объединим S1и S4,5, имеющих минимальное расстояние(4,5)1=2,43,в кластер S(1,4,5)и получим матрицу расстояний
 .
.
Следовательно, на расстоянии (1,4,5),(2,3)=2,80 объединяются кластеры S(1,4,5)и S(2,3)и все пять объектов образуют один кластер.
Результаты классификации представлены графически на рис.4.6
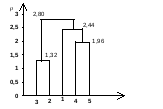
Рис.4.6 Дендрограмма (взвешенное евклидово расстояние, принцип ближайшего соседа)
Как и прежде, отдадим предпочтение разбиению на два кластера; мы получаем третий вариант разбиения, а именно S(2,3)и S(1,4,5).
Таким образом, используя пять алгоритмов кластерного анализа, мы получили три варианта разбиения пяти семей на две статистически однородные группы. С одной стороны это свидетельствует о гибкости (возможностях) методов кластерного анализа, а с другой- о необходимости использования экономических (содержательных) и статистических критериев для выбора наилучшего варианта классификации. При этом часто бывает полезной априорная информация об исследуемом явлении. В нашем примере, окончательно следует остановиться на разбиении S(1,2,3)и S(4,5), как наиболее устойчивом. Это разбиение получено по трем алгоритмам из пяти. Кроме того, оно согласуется с данными априорного, качественного анализа.