

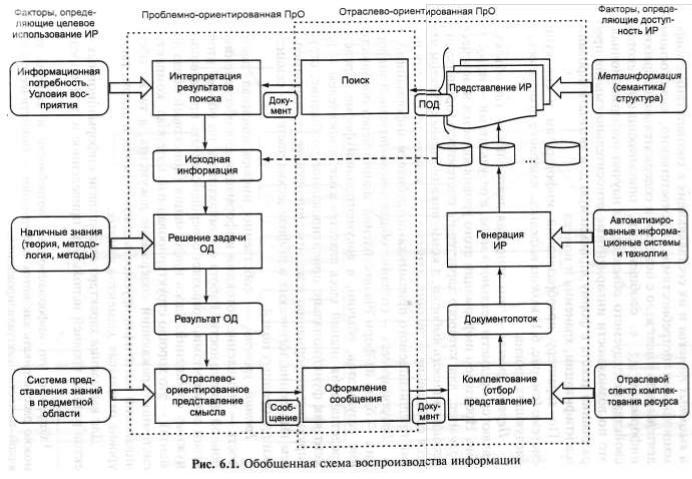
17. Обобщенная схема воспроизводства информации. Характеристика информационных компонент.
В основу схемы положено представление информационной системы (генераторпотребитель информации), связывающее объекты и процессы основной и собственно информационной деятельности. С точки зрения задач управления потоками здесь можно различить две совокупности процессов: формирование потока информации и распределение входных и выходных потоков и их составляющих в соответствии с информационными потребностями. По характеру преобразования информации можно выделить 3 уровня:
Первыйосновная деятельность, где объектами являются предметы реального мира, а результатаминовое знание. Носитель: человеческое сознание, для которого характерны системность организации и ассоциативность выборки., а коммуникационным объектом является сообщение.
Второй-создание общественно-полезной информации. Средство представления знаний: язык. Носительдокумент как функционально-ориентированное сообщение, структурирующее информацию и идентифицирующее ее.
Третийинформационная деятельностьуправление потоками информации для обеспечения основной деятельности. Работа с компактными по объемы вторичными документами позволяет совершенствовать процесс поиска нужных сообщений. Информацияхорошо структурированный материал, компактно и системно отражающий содержание документа.
Использование абстракций различного порядка дает возможность представлять объекты с помощью с помощью конечного числа терминов. Соотношений и характер взаимосвязей информационных объектов, форм их представления показаны на схеме.
18.Типология информационных потребностей (когнитивная модель)
Информационная потребность имеет несколько форм, соответствующих разным стадиям процесса познания. Определяют следующие типы информационной потребности.
Реальная информационная потребность. Это потребность в информации, еще не вполне осознанная, но отражающая проблемную ситуацию пользователя, характерная для начальной стадии ОД.
Осознанная ИПП. В процессе понимания проблемной ситуации реальная ИП преобразуется в осознанную ИПП, представленную в виде вопроса или задачи,
которую пользователь выражает на привычном ему языке, формируя запрос на естественном языке и затем переводя его в поисковый запрос, представленный в терминах ИПЯ. Преобразование вопроса в запрос происходит в сознании человека и имеет качественный характер. Переход от реальной к осознанной ИП тем сложнее, чем менее определена задача ОД. Наиболее адекватной формой представления осознанной ИП как поискового запроса может быть семантическая сеть — граф понятий, характерных для объекта поиска.
19.Типология неопределенностей информационного поиска. Уровневая модель представления информации и информационных потребностей.
Семантическая неопределенность связана с формализацией запроса. пользователь синтезирует ту информацию, которая, возможно, есть в отыскиваемом тексте. происходит реконструкция пользователем гипотетического текста, предположительно совпадающего в известной части проблемы с возможно уже существующим текстом, и обозначающего связи известного знания с выявленным неизвестным.
Лингвистическая (лексическая) неопределенность связана с формулировкой ПОЗа.
Формулируя запрос, пользователь должен учитывать, что его представление об информативности термина необ-но совпадает с представл-ми индексатора. Для ИПЯ дескрипторного типа это в значительной степени лексическая неопределенность.
Метаинформационная неопределенность пользователь должен иметь адекватное представление о системе и способе представл информации в ней.
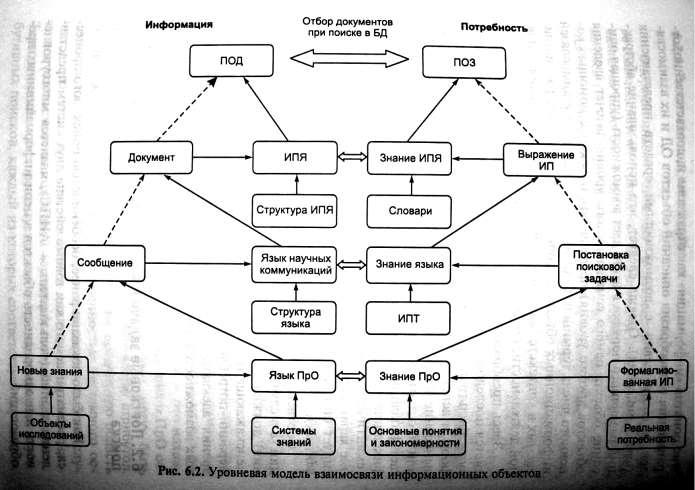
Соотношение и характер взаимосвязей информационных объектов, форм их представления, рассматриваемых в контексте задач информационного обеспечения основной деятельности, приведены на рис. 6.2.
Здесь преобразование форм представления информации является последовательным отражением содержания, а по существу — фильтрацией информации путем снижения разнообразия форм и аспектов представления смыслового содержания через вынесение части смысла в метаинформационную составляющую или простым отбрасыванием. Например, сообщение предполагает фиксацию (ограничение) предметной области; документ — фиксацию вариантов способа представления через выделение семантически однородных полей и, соответственно, определение характера и способа их наполнения; поисковый образ фиксирует способы указания значения отдельного элемента (типа данных).
Соответственно, адекватность средств отражения информации (а в случае ИПС — это средства лингвистического обеспечения) должна рассматриваться как с точки зрения возможности неискажающего преобразования самой информации в цепи генерациипотребления информационного ресурса, так и с точки зрения адекватности восприятия пользователем функциональных возможностей этих средств.
20.Типология задач информационного поиска. Характер неопределенности объекта поиска и требования к поисковому процессу для разных типов поисковых задач.
По характеру и степени соотношения в предмете поиска известного и неизвестного (как степени семантической неопределенности) можно выделить три типа поисковых задач.
1.Предметный (или атрибутивный ) вид поиска – поиск объекта, когда известно, что этот объект существует (например, поиск фактографии или трудов конкретного автора). Поисковая модель (логическая идентификация объекта поиска) может быть представлена как поиск по атрибутам. Для документального поиска – это отбор по логическому выражению над именами понятий, задаваемыми терминами или их комбинациями.
2.Тематический вид поиска – подбор информации по некоторой теме, например, для поиска метода решения практической задачи. Тематический поиск – это нахождение в среде ИС (информационной системы) описаний актуально существующих в ПрО (?предметной области?) основной деятельности объектов, свойства которых могут быть полностью определены на уже известном множестве атрибутов. Поисковая модель в этом случае – это поиск по части известного понятия или связям, частично задаваемым комбинацией характеристических признаков. Тематический поиск реализуется как последовательность атрибутивных поисков.
3.Вид проблемного поиска – нахождение в ИСр (информационное среде) описаний объектов или их составляющих, потенциально существующих в ПрО ОД (основной деятельности) и в совокупности, возможно, образующих целое, свойства которого будут больше суммы свойств частей. Т.е. этим свойствам в явной форме не соответствуют «собственные» атрибуты, а новое свойство, например, может быть задано комбинацией уже известных атрибутов. Логическая поисковая модель для этого случая – поиск «похожих» документов, содержание которых некоторым образом ассоциируется с задачей пользователя.
21.Понятие стратегии и технологии поиска. Связь стратегии и типа поисковой задачи.
Стратегия поиска - общий план (концепция, предпочтение, предрасположенность, установка) поведения пользователя для выражения и удовлетворения информационной потребности, обусловленный характером цели и типом поиска, архитектурой БД, а также методами и средствами поиска конкретной АИПС.
По способам организации доступа к информации, представленной в документальной форме, и отдавая должное истории развития ИС, можно говорить о двух типах решений, воплощаемых в промышленных АИПС.
Первые - традиционные ИПС, берущие начало от библиотечных систем, информационный вход в которых реализуется через дополнительные (вторичные по отношению к текстам документы) справочные структуры различного типа.
Вторые - гипертекстовые ИС, в которых переход к потенциально полезному документу реализуется через контекстную ссылку, размещенную в тексте самого документа. В зависимости от формы представления информационной потребности (вида запроса), можно выделить два вида поисковых стратегий.
Большинство промышленных АИПС обеспечивает поддержку традиционной вербальной стратегии, отличительной чертой которой является обязательное построение завершенного, логически и синтаксически правильного выражения, посредством которого может быть получена выдача формально релевантных запросу документов.
Другим видом стратегии является кластерная, обобщающая понятие "документ" или "совокупность документов" до уровня запроса. Подход основывается на предположении, что документ, его фрагмент или группа документов могут рассматриваться не только как результат поиска, но и как средство навигации, т.е. некоторый поисковый образ. Технологии, поддерживающие кластерные стратегии, в значительной мере позволяют сократить объем просматриваемой при поиске информации за счет определения на основе знаний пользователя групп документов для эффективной идентификации его потребностей.
Технология поиска – оптимизированная в рамках конкретной АИПС последовательность эффективного использования в процессе взаимодействия пользователя с системой отдельных средств поиска для получения устойчивого конечного и, возможно, промежуточных результатов. Технологии поиска (и как итог
-получения выдачи) объединяют два процесса:
процесс объявления (выражения, обозначения) пользователем информационной потребности;
процесс построения системой информационного массива - множества документов, выдаваемых пользователю в ответ на поисковое требование. Оптимизационная задача АИС – это минимизация совокупных временных
затрат за счет снижения суммарного объема выдач, просматриваемых потребителем. Методы сокращения пространства перебора (просматриваемого подмножества) образуют методологическую основу стратегии поиска и могут быть разделены на следующие классы:
Методы поиска в одном пространстве
Методы поиска в иерархически упорядоченном пространстве
Методы поиска в альтернативных пространствах
Методы поиска в динамическом пространстве (изменяющемся в процессе поиска)
Для случая документальных ретроспективных БД наиболее актуальными являются два первых случая, где в свою очередь можно выделить следующие подклассы:
Поиск методом уточнения/расширения области
Поиск с использованием абстрактных пространств (динамически выделяемых в соответствии с некоторым фиксированным набором признаков)
Поиск с использованием метапространства (динамическое определение набора признаков для выделения подпространств), т.е. с переопределением метода поиска
Учитывая опосредованность процесса извлечения информации из БД, можно сказать, что практически всегда процесс выполняется в два этапа. Первый этап – автоматизированный отбор документов по формальному критерию, в той или иной степени полно и точно соответствующих информационной потребности (предпочтительно более полно, хотя и менее точно), и второй – «ручной» отбор с непосредственным просмотром.
22.Логика поиска. Критерий смыслового соответствия. Теоретико-множественное представление.
Технология обработки информации – упорядоченная последовательность взаимосвязанных действий, выполняемых с момента восприятия информации до момента получения заданных результатов.
Информационная технология – это система методов, способов и средств для сбора, регистрации, хранения, поиска, накопления, обработки [..] информации.
Поиск информации – одна из основных функций ИТ.
Поиск – это процесс, в ходе которого в той или иной последовательности производится соотнесение отыскиваемого с каждым объектом, хранящимся в массиве.
Особенности поиска:
сравниваются не сами объекты, а поисковые образы
сам процесс поиска является неодноактным и многоитерационным Алгоритм поиска:
выборка очередного объекта из массива для выполнения сравнения с запрашиваемым
процесс сравнения
принятие решения о соответствии
переход к следующему объекту или завершение процесса Выделяют два вида поиска:
поиск целостного объекта (выдается весь документ)
поиск информации по содержанию (некоторой части содержания) Технология поиска может осуществляться по массиву двух видов:
с прямой организацией – документы расположены в произвольном порядке (по мере занесения)
с инвертированной организацией – имеется дополнительное разбиение на категории, обозначенные идентификаторами (с инвертированным
справочником)
Критерий смыслового соответствия – это формула, в соответствии с которой производится логическое и лингвистическое преобразование (развертывание) ПП с тем, чтобы найти ПОД, содержащий релевантную информацию, независимо от ее лексического представления.
Теоретико-множественная модель(??)
|
релевантные |
нерелевантные |
выданные |
a |
b |
не выданные |
c |
d |
Частные критерии оценки:
полнота – доля выданных релевантных документов: r = a/(a+c)
точность – доля релевантных среди выданных: р=а/(а+b)
специфичность – доля невыданных и нерелевантных среди невыданных: σ = d/(b+d)
относительный объем выдачи: ν = (a+b)/(a+b+c+d)
общность – доля релевантных документов среди всего информационного массива
23.Информация в системе воспроизводства знаний (системный подход). Информационные компоненты в системах управления.
Информационные системы - комплекс, состоящий из информ-го фонда и процедур: управляющей, обновления, информ-го поиска и завершающей обработки, - позволяющего накапливать, хранить, корректировать и выдавать информацию. Система (целое, составленное из частей соединение) – совокупность элементов, взаимодействующих друг с другом и образующих определенную целостность. Элемент системы – часть системы, имеющая определенное функциональное назначение. Сложные элементы систем, в свою очередь состоящие из более простых взаимосвязанных элементов, часто называют подсистемами.
Организация системы – внутренняя упорядоч-ть, соглас-ть взаимодействия элементов системы (проявляющаяся, в частности, в ограничении разнообразия состояний элементов системы)
Структура системы – состав, порядок и принципы взаимодействия элементов системы, определяющие основные свойства системы.
Архитектура системы – совокупность свойств системы, существенных для организации взаимодействия ее составляющих.
Целостность системы – принципиальная несводимость свойств системы к сумме св- в отдельных ее элементов и зависимость св-в каждого эл-та от его места и функции внутри системы. С точки зрения формы существования системы выделяют абстрактные и материальные системы.
Абстрактные системы – это системы, которые имеют в качестве операционных объектов преимущественно идеализированные, например, знания, теории, гипотезы. Материальные системы подразделяются на технические, эргатические и эргатехнические (смешанного типа).
Информационные системы (ИС) – материальная сист, организующая, хранящая и преобраз-я информ. Это сист, основным предметом и продуктом труда в кот-й явл информация.
Управление – это процесс обработки информации, направленный на достижение определенной цели. Управление – это функция системы, обеспечивающая либо сохранение ее основных свойств, либо ее развитие в заданном направлении.
Для исследования характера взаимодействия управляемого процесса и информационной системы через определенные структуры и характера информационных потоков между ними будем рассматривать эти элементы с позиции системного подхода, т.е. «…система представляет собой отражение материального образования с точки зрения единства его поведения и строения, обусловленность поведения этого целого определяется спецификой внутреннего строения, спецификой его элементов и особенностями взаимодействия между ними. Т.е., система – это такое строение, которое осуществляет преобразование причинных воздействий из окружающей среды и изнутри системы в соответствующие изменения объекта как целого». Понятие «поведение» отражает связь изменений в окружающей среде и/или самой системе с внешними или внутренними причинными воздействиями, вызвавшими эти изменения, а «строение» системы, как противоположное свойство, определяется единством множества элементов и структуры, осуществляющей их интеграцию в целостное образование.
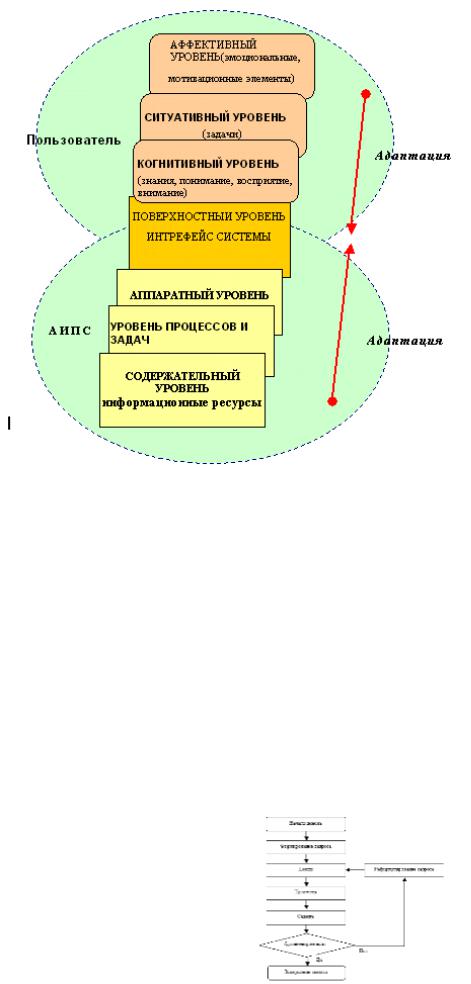
24.Уровневая модель информационного взаимодействия "Пользователь - АИПС". Основные этапы (общая схема) поиска информации.
Уровневая модель взаимодействия пользователя и системы На поверхностном уровне определяется характер процесса общения - применение различных тактик поиска, формулирование
иреформулирование запроса, добавление, удаление терминов, работа с документами; Аффективный уровень определяет эмоциональность – удовлетворенность или неудовлетворенность пользователя результатом; На когнитивном и
ситуативном уровне происходят изменения, связанные с интерпретацией полученной информации, осмыслением и переработкой, а также изменение локальных задач, возникших при достижении общей цели удовлетворения ИПП. Когнитивный уровень наиболее значимый для понимания особенностей восприятия
ииспользования информации
Первый уровень взаимодействия - это взаимодействие когнитивного уровня человека-оператора и поверхностного уровня компьютерной системы (интерфейса). Второй уровень - взаимодействие когнитивного уровня человека-оператора и уровня процессов и задач.
Третий - взаимодействие пользователя с предоставляемой системой информацией; является самым сложным и практически не формализуемым уровнем общения.
Если для процесса в целом (с точки зрения конечного пользователя) имеем всего два типа основных операционных объектов – запрос (как пользовательское представление информационной потребности) и документ ( как семантически целостный ответ или его часть, сформированный системой – отображение запроса в пространство документов), то с точки зрения организации процесса взаимодействия интерфейс системы должен иметь разнообразные объекты. К ним относятся:
Тезаурусы, обеспечивающие ориентацию пользователя в предметной области Словари поисковой системы, используемые для
формирования поискового выражения
Тематические словники, представляющие информативную лексику предметной области Основные этапы (общая схема) поиска информации:
25.Типология простых (фактографических) запросов и организация поисковых массивов для различных типов запросов.
1). А(Е) = ? Каково значение атрибута А для объекта Е?
2). А(?) = V Какие объекты имеют значение атрибута равное V? 3). ?(Е) = V Какие атрибуты объекта Е имеют значение равное V? 4). ?(Е) = ? Какие значения атрибутов имеет объект Е?
5). А(?) = ? Какие значения имеет атрибут А в наборе?
6). ?(?) = V Какие атрибуты объектов набора имеют значение равное V?
В запросах типов 2, 3, 6 вместо = могут быть использованы другие операторы сравнения (>,<, не равно или другие).
Запросы типа 1 выполняются поиском по «прямому» массиву: доступ к записи производится по первичному ключу. Запросы типа 2 выполняются поиском по инвертированному списку: доступ к записи(ям) производится по указателю, выбираемому из списка по значению вторичного ключа. Ответом в этих случаях будет значение атрибута или идентиф. Запросы типа 3 имеют ответом имя атрибута.
Запросы типа 2, 5, 6 относятся к нескольким атрибутам, и в этом случае могут быть построены несколько индексов, облегчающих поиск по этим ключам.
26.Расширенное логическое выражение запроса (обобщенная форма). Основные виды операторов и операндов.
Логическое выражение поискового условия – это синтаксическая конструкция языка, задающая порядок и способ вычисления величины, принимающей значение «0» или «1» В соответствии с правилами выражение представляет собой последовательность операндов, соединённых друг с другом знаками операций. Некоторые фрагменты выражения м.б. заключены в скобки.
Нотация Бэкуса для такого выражения следующая: <Выражение>::=<Операнд>?<Выражение><Операция> <Операнд>?<Операнд><Операция><Выражение>? (<Выражение>)<Операция><Операнд>? <Операнд><Операция>(<Выражение>)
В качестве операнда в поисковом выражении выступают термины (дескрипторы), а в качестве операции – одна из логических операций AND, OR, XOR и NOT. Оператор критерия задаёт условие включения или сравнения дескрипторов запроса и терминов, содержащихся в указанных полях документов.
«=» EQ – позволяет найти документы, для которых указанная область поиска равна результату вычисления выражения условия.
«<>» NE – позволяет найти документы, которые не содержат в указанной области поиска результат вычисления выражения условия
«>» GT – позволяет найти документы, которые содержат в указанной области поиска значения большие, чем результат вычисления выражения условия
«>=» GE - …. Значения большие или равные результату вычисления выражения условия
«<» LT - ….. значения меньшие, чем результат вычисления выражения условия «<=» LE - …. Значения меньшие или равные результату вычисления выражения условия.
Контекстные операторы
<дескриптор1>оператор<дескриптор2>
CTR[N] - позволяет найти документы, в заданной области поиска которых в одном предложении присутствуют поисковые дескрипторы, расположенные в указанном порядке на расстоянии не более N слов друг от друга
NEAR[N] – …… на расстоянии не более N слов друг от друга SENT[N] - …. Находящиеся в одном предложении
CON[N] - … в ИПС IRBIS включён оператор пересечения полей, служащий для отбора документов, в заданных полях которых имеется не менее N одинаковых поисковых терминов
<имя поля1> CON[N] <имя поля2>
N от 1 до 255!
27.Назначение и организация инвертированной формы представления документальной информации. Примерная организация поисковых массивов документальной ИПС дескрипторного типа.
Технология поиска основывается на 2 типах организации массивов объектов – прямой и инвертированной.
Прямая организация - когда документы размещаются последовательно (не алфавит и не классификация), например, в порядке их поступления.
Инвертированная технология - документы разбиваются на подмножества, которые могут быть классифицированы и имеют индексы, в которых отображается содержание документов. Упорядоченные документы составляют инвертированный справочник. Проводится поиск в инвертированном справочнике. Запрос сравнивается с классом, потом с содержанием документов этого класса. Благодаря этому уходит меньше времени на поиск, т.к. легче просмотреть индекс документа, чем весь документ.
Запрос обычно представляется как набор атрибутов. Атрибуты могут быть представлены в ключевой или позиционной форме.
Позиционная форма - табличный способ: каждому атрибуту соответствует колонка, каждая ячейка которой содержит значение атрибута.
Ключевая форма – имя атрибута = значение. В документальных системах, в которых поисковые образы представлены набором дескрипторов, атрибут задается предикатом «поисковый образ имеет в составе дескриптор». Сам дескриптор является значением атрибута.
Дескрипторы – это ключевые слова, которые по определенным правилам отобраны из основного словарного состава языка и у которых искусственно устранены синонимия, полисемия и омонимия.

28.Типы обратной связи в технологии информационного поиска.
Обратная связь по релевантности на уровне отдельных терминов должна обеспечить пользователю возможность целенаправленно изменять поисковой запрос путём повышения роли одних и повышения роли других терминов, не вникая в тонкости составления запроса, определяемые особенностями документального массива и ИПС.
В рамках модели (в соответствии с которой определяется обратная связь) существуют различные стратегии изменения весовых коэффициентов терминов, предлагаемых системой для расширения запроса, на основании информации о релевантности/нерелевантности выданных документов.
Диалоговая модель поиска «по обратной связи» с ИПС IRBIS отличается от модели эвристического поиска тем, что после выполнения системой очередного шага пользователю предоставляется возможность управлять дальнейшим процессом формирования результата, т.е. последовательность шагов в диалоговой модели дискретна и реализуется в зависимости от предпочтений пользователя.
Шаг 1. Построение и ранжирование словника релевантных документов.
W=(wi,i=(l,k)), где k – количество терминов релевантных документов, а wi – значение весового коэффициента для i-го термина, удовлетворяющее неравенству wi≥wi+1. пользователь в данном случае получает оценку всех терминов релевантных документов, которые находятся в частотном словаре, т.е. в ПОТ (поисковой образ темы) попадают все термины без исключения. По завершении первого шага пользователь самостоятельно отмечает термины, способные улучшить поисковой запрос. Отмеченные термины он далее может самостоятельно добавить в поисковой запрос для реализации моделей поиска по совпадению терминов или по логическому выражению или инициировать второй шал поиска по обратной связи.
Шаг 2. Формирование матрицы поисковых результатов. Термины, отобранные пользователем на предыдущем шаге, рассматриваются как исходные для проведения поиска по совпадению терминов. Модель этого механизма поиска реализуется в данном случае построением подматрицы запроса Lq, в которой отдельные строки могут быть нулевыми.
|
|
|
Lq = |
|
bi11 |
|
|
|
|
|
bi12 |
|
|
|
|
|
|
b – термин.
Для каждого ненулевого столбца матрицы построим вектор Qi – результат поиска аналогов с максимальным порогом близости. Полученные векторы рассмотрим как строки матрицы поисковых результатов:
Q Theme=(qij, i=l,n, j=l,n0), где n – количество ненулевых
столбцов матрицы.
Каждая строка сформированной таким образом матрицы снабжается контекстом – перечислением конкретных терминов, присутствующих в документах конкретного результата. Удалив из матрицы строки с одинаковым контекстом, получим кластеризованное пространство документов, где каждый кластер задаётся не только количеством терминов запроса, но и составом самих терминов. Матрица поисковых результатов Q Theme даёт возможность обеспечить доступ к каждому отдельному результату для его просмотра и последовательного формирования нового множества релевантных документов.
29.Линейная модель механизма поиска по совпадению терминов.
При поиске по совпадению терминов задается требование полного или частичного совпадения. Частичное совпадение осуществляется с помощью маскирования. Формирование поискового образа запроса (ПОЗ): выбираем из матрицы L0 строки, которые соответствуют терминам, указанным в запросе. Если термин не найден, ему ставится в соответствие строка, состоящая из нулей. Для k терминов получаем подматрицу запроса (Lq):
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
bi 1bi 2 |
bi n |
|
|
|
||
|
|
1 |
1 |
1 |
0 |
|
|
|
|
|
Q |
||||
L |
b |
b |
b |
|
|
Построим результирующий вектор запроса: |
|
q |
|
i2 |
1 i2 2 |
i2n0 |
|
||
|
|
|
|
|
|
||
|
|
|
|
||||
|
b |
b |
b |
|
|
|
|
|
|
ik |
1 ik 2 |
ik n0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
k |
k |
k |
|
bil 1 |
bil 2 bil n0 |
|
|
l 1 |
l 1 |
l 1 |
|
Окончательный поисковый результат м.б. сформирован по двум правилам: документ считается формально релевантным запросу, если содержит все k терминов, или если содержит хотя бы часть (один, два, три и т.д.) из k терминов. При реализацииполучаем:
|
|
|
|
|
|
|
|
|
k |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1, если |
b |
k |
|
Q |
q q q |
|
, где q |
|
|
|
i i |
|
||
|
|
|
|
|
|
|
|
|
l |
|
k |
1 |
2 |
n |
|
i |
|
|
l 1 |
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 - в противномслучае |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k |
|
|
|
|
|
|
|
1, если |
b |
m |
|
qi |
|
i i |
|
|
|
|
l 1 |
|
|
|
|
|
l |
|
|
|
|
|
|
|
0 - в противномслучае |
|||
|
|
|
|
|
Для реализации 2-го правила зададим границу m, определяющую min-е количество терминов, необходимое для отнесения документа к релевантным документам.
30.Линейная модель механизма поиска по логическому выражению.
Логическое выражение-это последовательность терминов, объединенных знаками логических операций; синтаксическая конструкция языка, вычисляющая величины, которые принимают значение «0» или «1».
Логические операции: AND, OR, XOR, NOT.
Первый этап вычисления логического выражения может состоять в построении двоичного дерева операций. Все логические операции (кроме операции НЕ) являются бинарными, могут представить любое логическое выражение запроса в виде несбалансированного двоичного дерева, прохождение по которому снизу вверх приводит к получению результата. В узлах такого дерева, включая корневую вершину, расположены логические
операции (oi), а листья (конечные |
|
узлы) |
представляют собой строки матрицы L0, |
|||||
соответствующие терминам запроса ( |
t |
|
b |
, j 1, n |
|
|
). |
|
|
i |
ij |
|
|
0 |
|
||
|
|
|
|
|
|
|||
Будем называть операндом запроса отдельно вычисляемое выражение, соответствующее поддереву запроса.
Рассмотрим расширенную матрицу «термин-документ» L’0, строки которой могут представлять собой не только показатели встречаемости терминов в документах информационного массива, но и результирующие векторы запросов (Qi)
|
b b |
b |
|
|
|
|
|||
|
|
11 |
12 |
|
1n |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
b b |
b |
|
|
|
|
|||
|
21 |
22 |
|
2n |
0 |
|
|
|
|
L0 |
|
|
|
|
|
|
|||
|
|
|
|
|
|||||
|
b |
b |
|
b |
|
|
D |
||
|
|
D 1 |
D 2 |
|
D n0 |
|
, где |
||
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
K – количество включенных
D
в
K , D- словарь.
матрицу результирующих векторов запросов,
|
|
b |
|
, если строка принадлежи т матрице L |
|
b |
|
|
ij |
0 |
|
|
|
|
|
||
ij |
|
|
|
|
|
|
|
|
q |
|
, если строка представля ет собой результат запроса |
|
|
|
ij |
||
|
|
|
|
||
Поставим |
в соответствие каждой |
логической |
операции правило |
ее выполнения с |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
o |
b |
|
, j |
1,n |
, |
|
o |
|
|
|
||
использованием расширенной матрицы: |
b o b |
|
b |
|
где |
k |
из |
множества |
||||||||||||||
i |
|
k |
m |
|
ij |
|
k mj |
|
|
0 |
|
|
||||||||||
|
o1 , o2 ,..., os Для |
|
|
|
|
|
||||||||||||||||
бинарных |
логических операций: ok |
O, O |
|
унарной операции |
NOT это |
|||||||||||||||||
|
|
|
b |
b |
|
|
|
|
|
|
|
|
|
|
||||||||
правило реализуется следующим образом: |
, j 1, n |
|
|
|
|
|
|
|
||||||||||||||
|
|
|
i |
|
|
ij |
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Тогда алгоритм разрешения двоичного дерева поискового запроса состоит в последовательном выполнении снизу вверх логических операций и в пополнении на
каждом шаге матрицы L0 |
очередной строкой-результатом. |
|
|||||
Условием выполнения k-той операции служит наличие в матрице |
L |
||||||
0 строк, соотв-щих |
|||||||
правому и левому операнду. |
После выполнения |
k-той операции формируется |
|||||
результирующий вектор |
q |
|
b o |
b |
D 1)-й строкой матрицы. |
||
|
k |
i k |
|
m , который становится ( |
|||

31.Линейная модель механизма поиска документов-аналогов.
Аналоги документадокументы, имеющие заданное количество общих терминов с исходными документами.
Выделим в матрице L0 |
столбец |
l |
|
b |
,i 1, D |
, соответствующий поисковому образу |
|
k |
ik |
|
|||
|
|
|
|
|
документа (ПОД) рассматриваемого документа, и построим подматрицу Ldoc, оставив в
матрице L0 |
те строки, в которых |
b |
0 |
. По матрице Ldoc строится результирующий вектор |
ik |
|
|||
|
|
|
|
запроса на поиск аналогов (Qdoc ) и м.б. получен поисковый результат с учетом (или без) некоторого заданного порога «близости» (m).
Когда универсальный словарь представляет собой набор отдельных словарей Di, построенных по лексике отдельных структурных единиц документов (например, полей), процедура поиска аналогов м.б. усложнена заданием пороговых значений для структурных единиц и построением логического выражения над множеством критериев отбора, связывающих поле и соответствующее пороговое значение.
Рассмотрим реализацию процедуры поиска аналогов для случая:
DDi
i 1n
,
|
|
b |
i |
b |
i |
|
b |
i |
|
|
|
|||
|
|
|
11 |
12 |
|
1n |
|
|
|
|||||
|
|
b |
|
b |
|
|
b |
0 |
|
|
|
|||
|
|
i |
i |
|
i |
|
|
|||||||
L |
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
21 |
|
22 |
|
|
2n |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
D |
|
|
|
||||||||||
|
i |
|
||||||||||||
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
b |
i |
|
b |
i |
|
b |
i |
|
|
||
|
|
|
|
i |
|
i |
i |
0 |
|
|||||
|
|
|
|
D 1 |
|
|
D 2 |
|
|
D n |
|
|
||
Тогда ПОД заданного документа представляет собой
n
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
l |
|
|
|
l |
D |
, |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k |
|
|
|
|
||
объединение ПОДов, построенных для различных структурных единиц: |
|
k |
|
|
|
|
|
|
||||||||||||||||||||||||||
|
|
|
|
i 1 |
|
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
b , l |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
l |
D |
|
1, D |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D |
|
|
|
|
D |
|
|
||||
i |
|
|
|
|
|
|
|
|
|
|
L |
|
|
|
|
|
L |
|
|
L |
n |
|
||||||||||||
|
k |
|
|
lk |
i |
|
, а подматрица аналогов - соединение подматриц: |
|
|
|
|
( |
|
1 |
,…, |
|
)’ |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
Doc |
|
|
|
Doc |
|
|
Doc |
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Построим матрицу результирующих векторов |
Q |
Doc |
q |
ij |
,i 1,n, j 1,n |
0 |
|
, где каждая строка |
||||||||||||||||||||||||||
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
представляет собой результирующий вектор одной из подматриц с учетом заданного |
||||||||||||||||||||||||||||||||||
порога близости: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
D |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Q qi |
|
|
, где qi |
|
|
i |
bi |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
qi |
qi |
|
1, если |
m |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
lj |
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
i |
1 |
2 |
n0 |
l |
|
|
l 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 - в противномслучае |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Используя матрицу |
Q |
Doc |
вместо матрицы L0 в модели поиска по логическому выражению, |
|||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
можно выполнять процедуры построения дерева запроса с последовательным вычислением результата.

32.Линейная модель механизма эвристического поиска.
Эвристический поиск работает по принципу отыскания документов, «похожих» на усредненный «тематический» образ некоторого множества релевантных
документов, |
|
указанных |
пользователем, |
и |
реализуется |
следующей |
|||||
последовательностью шагов: |
|
|
|
|
|
|
|
|
|||
Шаг 1. Построение словника по массиву релевантных документов. |
Результатом |
||||||||||
является подматрица Lrel |
матрицы L0, построенная путем выбора столбцов, |
||||||||||
характеризующих |
|
|
заданные |
|
пользователем |
||||||
документы: |
L |
|
b ,i 1,D,k 1,n,1 j |
|
n |
|
, |
|
|
|
|
|
Rel |
ij |
|
k |
|
0 |
|
|
|
|
|
|
|
|
k |
|
|
|
|
|
|
|
|
n – количество документов, отмеченных пользователем как релевантные.
Шаг 2. Оценка терминов словника и построение Поискового Образа Темы (ПОТ). Результатом оценивания должно быть выделение тех терминов, которые могут быть включены в ПОТ. Желательно, чтобы в основе формальной оценки лежали
частотные характеристики, которые могут быть получены из матриц L0 и Lrel:
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
F |
b |
|
|
|
|
|
|
|
|
L L |
|
||
i |
ij |
(или i-тый элемент главной диагонали матрицы |
T |
||||||||||
|
|
||||||||||||
|
j 1 |
0 |
0 |
), |
|||||||||
|
|
|
|
|
|
|
|
|
|
||||
F |
|
|
b |
|
|
|
|
|
|
|
|
|
|
i Rel |
|
ij |
|
L |
Q |
|
|
|
|
|
|||
|
j j |
, j |
, , j |
|
(или i-тый элемент вектора |
|
), |
|
|
|
|||
|
k |
0 |
|
Rel |
|
|
|
||||||
|
1 |
2 |
|
|
|
|
|
|
|
||||
где Fi – частота термина в информационном массиве, FiRel – частота термина в множестве релевантных документов, Qrel – вектор релевантных документов (строка
расширенной матрицы L ).
0
Для оценки степени соответствия термина ПОТ может быть использована мера точности термина - отношение частоты термина в множестве релевантных документов к частоте термина в информационном массиве, в качестве порога для отбора в ПОТ – относит коэффициент CR, вычисляемый в зависимости от эвристического параметра ns, характеризующего количество ожидаемых документов. Эвристический параметр характеризует минимальную (ненулевую)
точность термина, возможную в ожидаемой выдаче:
C |
|
|
1 |
|
R |
n |
|||
|
|
|||
|
|
|
||
|
|
|
s |
. В ПОТ отбираются
|
Fi Rel |
CR |
|
|
|
термины, для кот выполняется неравенство: |
Fi |
|
|
|
|
Шаг 3. Построение матрицы «термин-документ» для функции поиска аналогов. На этом шаге из матрицы Lrel должны быть удалены строки, для кот не выполняется
неравенство. В результате получаем матрицу LПОТ:
LПОТ bijk ,i 1,M ,k 1,n , где M – количество терминов в ПОТ, определяющее порог «близости» для следующего шага.
Шаг 4. Выполнение функции поиска аналогов с пороговым значением M. По матрице LПОТ строится результирующий вектор запроса на отбор документованалогов (QПОТ ) и формируется поисковый результат с учетом порога близости M. Если число документов полученного результата меньше, чем заданное в системе ns, то пороговое значение M уменьшается на 1, и повторяется процедура поиска аналогов с новым пороговым значением. Таким образом, на каждой i-ой итерации пороговое значение равно M–i.

Цикл заканчивается: либо после выполнения очередной итерации число документов результата стало равно или превысило значение ns, либо пороговое значение стало равно 0.
33.Линейная модель механизма поиска по технологии обратной связи по релевантности терминов.
Обратная связь по релевантности терминов должна обеспечить пользователю возможность целенаправленно изменять поисковый запрос путем повышения роли одних и понижения роли других терминов, не вникая в тонкости составления запроса, определяемые особенностями документального массива и ИПС. При этом процесс поиска разбивается на последовательность несложных шагов, ведущих к поставленной цели.
В модели (в соответствии с которой определяется обратная связь) существуют различные стратегии изменения весовых коэффициентов терминов, предлагаемых системой для расширения запроса, на основании информации о релевантности/нерелевантности выданных документов.
Рассмотрим диалоговую модель механизма поиска по обратной связи, предлагаемую в ИПС IRBIS. Она отличается от модели эвристического поиска тем, что после выполнения системой очередного шага пользователю предоставляется возможность управлять дальнейшим процессом формирования результата, т.е. последовательность шагов в диалоговой модели дискретна и реализуется (с точки
зрения продолжительности) в зависимости от предпочтений пользователя. |
|||
Шаг 1. Построение и ранжирование словника релевантных документов. |
|||
Рез-том этого шага является вектор |
W w |
,i 1,k , |
где k – количество терминов |
i |
|
||
|
|
|
|
релевантных документов, а wi - значение весового коэффициента для i-го термина,
удовлетворяющее неравенству |
w w |
. Расчеты весовых коэффициентов могут |
||
i |
i 1 |
|||
|
|
|||
основываться на различных мерах близости и на этом шаге не влияют на количество выдаваемых пользователю терминов (пользователь получает оценку всех терминов релевантных документов, которые находятся в частотном словаре).
По завершении первого шага система передает управление пользователю, который самостоятельно отмечает термины, способные улучшить поисковый запрос.
Отмеченные термины пользователь могут самостоятельно добавить в поисковый запрос (для реализации моделей поиска по совпадению терминов или по логическому выражению) или инициировать второй шаг поиска по обратной связи.
Шаг 2. Формирование матрицы поисковых результатов.
Термины, отобранные пользователем на предыдущем шаге, рассматриваются как исходные для проведения поиска по совпадению терминов. Модель этого механизма поиска реализована построением подматрицы запроса (Lq), в которой отдельные строки могут быть нулевыми.
Рассмотрим подматрицу Lq как исходную для проведения процедуры поиска аналогов и последовательно для каждого ненулевого столбца построим вектор Qi – результат поиска аналогов с max-ым порогом близости (задается количеством единиц в столбце, а контекст результата задается перечислением самих терминов). Полученные векторы рассмотрим как строки матрицы поисковых результатов:
QTheme qij ,i 1,n, j 1,n0 ,где n – количество ненулевых столбцов подматрицы Lq. Каждая строка матрицы снабжается контекстом-перечислением конкретных

терминов, присутствующих в документах конкретного результата. Матрица результатов дает возможность просматривать каждый отдельный результат, что позволяет формировать новое множество релевантных документов.
34.Матрицы ассоциации документов, терминов и их свойства.
Используем понятие универсального словаря D (прообразом которого может быть, например, тезаурус, рубрикатор), содержавшего множество лексических единиц всего потока документов.
li – совокупность лексических единиц некоторого документа (сообщения), который является элементом некоторого потока L:
Аналогично универсальному словарю введём понятие универсально массива L0 (прообразы – поисковый массив ИПС, отраслевой справочно-информационный фонд, массив библиотеки), подмножеством которого являются все документы:
Где n0 – мощность множества L0.
Линейное представление теоретико-множественного образа документа:
Универсальный массив в линейном представлении есть матрица размерности D*n0:
Подобные матрицы – матрицы «термин-документ». Каждый столбец соответствует документу и описывает множество терминов, содержащихся в нём.
Строка соответствует отдельному термину и является перечнем документов, содержащих данный термин.
35.Типология и показатели оценки эффективности информационного поиска. Определение первичных координат описания выхода ИПС.
При комплексной оценке учитываются два вида критериев:
экономический – денежные и временные затраты, необходимые для выполнения задачи технический – способность обеспечить потребителям требуемый уровень
информационного обслуживания Существует анализ экономической эффективности затрат и анализ соотношения затраты - выигрыш.
Экономическая эффективность затратпоиск недорогих методов выполнения заданного набора операций или получение максимальных результатов при данных затратах. Анализ соотношения затраты-выигрыш – систематическое сравнение стоимости выполнения отдельных операций и выигрыша, получаемого в результате их выполнения. Анализ эффективности затрат должен основываться:
Четко определенные цели
Для достижения целей должны быть предусмотрены альтернативы
Определена стоимость альтернатив
Создание модели для связи целей и альтернатив
Ранжирование альтернатив путем оценки затрат и ожидаемой эффективности Когда задан объем работы, основные альтернативы и выбор вариантов относятся к операциям индексирования и ввода документов, а также к процессам поиска и вывода информации.
Каждый критерий качества может достигаться многими различными способами, каждый из которых требует своего уровня затрат (например, точность можно повысить использованием специфичного языка индексирования).
Техническая эффективность. В этом вопросе существует 2 точки зрения-пользователя и администратора.
Оценки технической эффективности, интересующие пользователей:
полнота поиска – способность выдавать все релевантные документы
точность поиска – способность отбрасывать все нерелевантые документы
усилия – на формулирование запросов и просмотр выданной информации
время поиска
форма представления выдачи (вопросы интерфейса)
полнота информационного массивастепень охвата всех релевантных документов Методика измерения показателей эффективности:
затраты труда пользователей выражается через время, необходимое на формулирвоание запроса и тд
время реакции системы
форму представления выдачи оценивают в процентном отношении к полному тексту Оценку степени соответствия (охвата) документов БД информационной потребности делать сложно, т.к. чаще всего заранее неизвестно общее количество материалов, представляющих интерес в данной предметной области. По этой же причине показатели полноты и точности отражают реальное положение условно, это затрудняет их практическое использование при проведении поиска.
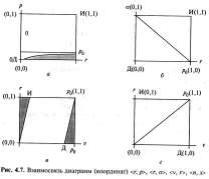
Первичные координаты описания выхода ИПС, представляющие соотношение множеств выданных и невыданных документов:
Диаграмма <L> - соотношение множеств L0-всего информационного потока, Lи- множество истинно релевантных документов и Lc- множество документов, выданных системой в ответ на поисковый запрос.
Таблица сопряженности <a,b,c,d> отображает количественное соотношение выданных системой множеств релевантных и нерелевантных документов и невыданных множеств релевантных и нерелевантных документов.
Диаграмма <n,x> -сочетание числа выданных релевантных (х) и всего выданных (n) документов.
36.Основные частные и интегральные критерии оценки АИПС.
На основе первичных координат построены частные показатели оценки технической эффективности:
Полнотадоля выданных релевантных документов по сравнению с их общим количеством в информационном массиве: r=a/(a+c)= x/x0=|LИ ∩LC|/|LИ|
Точность – доля релевантных документов во множестве выданных: p=a/(a+b)=x/n=|LИ ∩LC|/|LC|
Специфичностьдоля невыданных документов по сравнению с невыданными и выданными нерелевантными: σ=d/(b+d)=1- (n-x)/(n0 – x0)=|L0\ (LИ ULC)| / |L0\LИ|
Общностьхарактеризует качество комплектования поискового массива ( доля релевантных документов в информационном массиве): p0=(a+c)/(a+b+c+d)=n/n0=|LИ|/|L0|
Относительный объем выдачи: v=(a+b)/(a+b+c+d)=n/n0=|LC|/|L0|
Отдельно взятое значение одного из частных показателей не отражает качество выдачи, поэтому обычно их используют парами <r,p>, <v,r> и тд. Пары показателей могут быть интерпретированы как прямоугольные координаты, тогда выдача системы отображается точкой на соответствующей плоскости.
Координаты <v,r> получаются путем нормирования к единице координат <n,x>, при этом заштрихованные области диаграммы соответственно сжимаются до треугольника с меньшей стороной, равной р0. Т.к. р0 очень
мало, этими областями можно пренебречь и в дальнейшем координаты <v,r> могут изображаться в форме квадрата без указания областей.
Интегральные показатели оценки технической эффективности.
Использование частных показателей неудобно, т.к. невозможно определить какая из выдач будет предпочтительнее- с координатами <r1,p1> или <r2,p2>, если p1<p2 и r1>r2. Это вызывает необходимость построения интегральных показателей. Если частные показатели p,r, σ включают только часть переменных <a,b,c,d> (как правило 3), то интегральные охватывают все переменные и вполне однозначны.
Интегральные показатели: коэффициент линейной корреляции и показатель полезной работы.
Показатель полезной работы базируется на предположении о том, что качество поиска АИПС тем выше, чем в большей степени потребитель освобождается от необходимости полного просмотра массива документов.

37.Понятие рабочей характеристики АИПС.
Вывод показателя полезной работы АИПС базируется на предположении о том, что качество поиска АИПС тем выше, чем в большей степени потребитель освобождается от необходимости полного просмотра массива документов. Пусть потребителю требуются релевантные документы в количестве х. При непосредственном просмотре L0 трудозатраты (количество просмотренных документов) в среднем составляет:
В то время как при просмотре массива Lc, имеющего точность р, затраты
Работа АИПС равна разности данных величин или высвобожденной информационной деятельности потребителя:
(1)
С учётом других координат и переменных выражение примет вид:
Пусть прямые |
параллельны 0р0 и проходят через различные точки прямой 0И. |
Общее уравнение прямой, проходящей через  и имеющей наклон р0, есть:
и имеющей наклон р0, есть:
Подставим в формулу (1), имеем:
Тем самым, на прямых вида величина Сис остаётся постоянной. По мере приближения точки пересечения прямой с 0И к точке И данная константа увеличивается. Она приобретает значение, если линия проходит ниже прямой 0р0.
Таким образом, Сис удовлетворяет условиям:
Или в координатах <n,x>:
Установление пределов измерения Сис позволяет нормировать эту величину:
Мера полезной работы ИС изменяется от +1 до -1, причём:
в точке И ή=+1 (идеальная система, выдающая все релевантные и только релевантные сообщения)
в точке Д ή=-1 (система, выдающая все нерелевантные и только нерелевантные сообщения - дизинформирующая)
|
38.Матрицы "термин-документ", "термин-термин" и их свойства. |
|
D-словарь, содержащий множество лексических единиц всего потока документов. Тогда |
||
li |
D |
для всех i, где liсовокупность лексических единиц некоторого документа, который |
|
||
является элементом некоторого потока L: L={l1,…,li,…,ln}, li L.
Существует универсальный массив L0, подмножеством которого являются все документы: L0={ l1,…,li,…,ln}, li L0 для всех i, причем |L0|=n0, где n0- мощность множества L0. Линейное представление теоретико-множественного образа документа:
lk=
b |
|
||
|
1k |
|
|
|
|
||
|
|
||
|
b |
|
|
|
|
||
ik |
|||
|
|
||
|
|
||
|
|
|
|
bDk |
|||
, где b = 1, 1-если i-й термин входит в k-й документ;0- если не входит.
ik
0,
Универсальный массив в линейном представлении есть матрица размерности D*n0:
L0= |
|
b |
b |
|
b |
|
Каждый столбец матрицы соответствует документу и описывает |
11 |
12 |
|
1n0 |
||||
|
|
|
|
|
|
|
множество терминов, содержащихся в нем. Столбец матрицы |
|
|
|
|
|
|||
|
|
b |
b |
|
b |
|
характеризует ПОД. Строка матрицы соответствует отдельному |
|
|
|
|||||
|
i1 |
i 2 |
|
in |
|
||
|
|
|
|
0 |
термину и является перечнем документов, содержащих данный |
||
|
|
|
|
|
|||
|
|
||||||
|
|
b |
b |
|
b |
|
термин. Сумма элементов строки представляет собой частотную |
|
|
|
|
||||
|
D1 |
D 2 |
|
Dn |
характеристику термина Fi, присутствующую обычно в |
||
|
|
|
|
0 |
|||
|
|
|
|
|
|
|
|
частотном словаре информационного массива: Fi=∑bik.
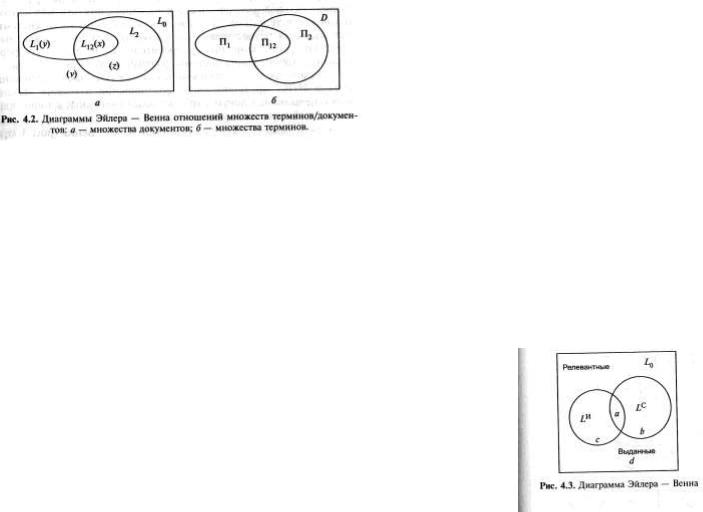
39.Диаграмма Эйлера-Венна (диаграмма <L>). Критерии оценки АИПС в координатах <L>.
Здесь L1 и L2- множества документов, L12-
их пересечение, L0-множество документов информационного массива. П1 и П2- множество терминов (все значимые термины, хотя бы 1 раз встречающиеся во множестве документов);П12- пересечение информационных профилей;D- универсальный словарь.
Данные множества могут трактоваться: L1 и L2- множества документов, связанных по общему термину; П1 и П2- списки терминов каждого из двух документов (термины, хотя бы раз встречающиеся в документах потока или встречающиеся чаще чем некоторый порог ƒmin или имеющие частоты, лежащие в интервале [ƒmin, ƒmax]
Рассмотрим случай когда L1 и L2- множества документов, связанных по общему термину. Выберем 2 произвольных термина T и t, входящие в какие-либо документы из L0.
L1- множество документов, содержащих термин T. L2- множество документов, содержащих термин t.
X=|L12|=|L1∩L2|- количество документов, содержащих оба термина
Y= | L1\L2|- количество документов, содержащих термин T, но не содержащих термин t.
Z= | L2\L1|- количество документов, содержащих термин t
V= |L0\(L1UL2)|- количество документов, не содержащих ни одного из терминов.
X+y+z+v=|L0|=n0
Для измерения эффективности системы используются
разностные меры множеств истинно релевантных LИ и выданных LC документов. Проблема оценки эффективности формальна сходна с задачей сопоставления множеств документов и множеств терминов.
40.Таблица сопряженности. Критерии оценки АИПС в координатах <a,b,c,d>.
Таблица сопряженности <a,b,c,d> отображает количественное соотношение выданных системой множеств релевантных ( с точки зрения потребителя) и нерелевантных документов и невыданных множеств релевантных и нерелевантных документов.
РелеНерелевантные вантные
Выданные |
|
a |
b |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Невыданные |
c |
d |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Взаимосвязь представленных координат: |
|
|
|
|
||||
|
|
|
|
|
и |
с |
|
|
Число выданных релевантных документов: a = x = | L |
∩ L |
| ; |
|
|||||
Общее число релевантных документов: |
|
и |
|
|
||||
a + с = x۪ = |L | ; |
|
|||||||
|
|
|
|
|
|
c |
|
|
Количество выданных документов: |
a + b = n = |L | ; |
|
|
|||||
Общее число документов L0 : |
a + b + x + d = n0 = |L0| ; |
|
||||||
|
|
|
|
|
|
|
c и |
|
Число выданных нерелевантных документов: b = n – x = | L \ L | |
|
|||||||
|
|
|
|
|
|
|
и |
c |
Число невыданных релевантных документов: b = x0 – x = |L |
\ L | ; |
|
||||||
|
|
|
|
|
c |
|
|
|
Число невыданных документов: c + d = n0 – n = |L0 \ L | ; |
|
|
||||||
|
|
|
|
|
и |
|
|
|
Число нерелевантных документов: b + d = n0 – x0 = |L0\L | ; |
|
|||||||
Число невыданных нерелевантных документов: d = n0 – x0 |
- (n - x) = |L0\ (L |
U L )| |
||||||
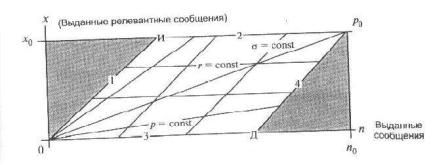
41.Диаграмма <n,x>. Критерии оценки АИПС в координатах <n,x>.
Допустимые выдачи (имеющие смысл сочетания числа выданных релевантных – х и всего выданных документов - n) находятся в незаштрихованной области 0Иp0Д, ограниченной прямыми линиями:
0И: x = n; Ир0: х = х0; p0Д: х = n – (n0 – x0); Д0: х = 0
Взаимосвязь представленных координат: |
|
|
|
и |
с |
Число выданных релевантных документов: a = x = | L ∩иL |
| ; |
|
Общее число релевантных документов: |
a + с = x۪ = |L | ; |
|
|
c |
|
Количество выданных документов: |
a + b = n = |L | ; |
|
Общее число документов L0 : |
a + b + x + d = n0 = |L0| ; |
|
|
|
c и |
Число выданных нерелевантных документов: b = n – x = | L \ L |
и c
Число невыданных релевантных документов: b = x0 – x = |L \ L | ; c
Число невыданных документов: c + d = n0 – n = |L0 \ L | ;
и
Число нерелевантных документов: b + d = n0 – x0 = |L0\L | ;
и с
Число невыданных нерелевантных документов: d = n0 – x0 - (n - x) = |L0\ (L U L )|

42.Коэффициент линейной корреляции множества выданных и истинно релевантных документов.
Коэффициент линейной корреляции R выдачи и релевантности документов представляет собой корреляционный момент двух случайных величин:
С – «быть выданным документом» (формально релевантным с точки зрения системы); И – «быть релевантным» (истинно релевантным с точки зрения пользователя). Каждая из велечин может иметь значения 0 и 1 в зависимости от конкретного документа.
Математические ожидания С и И:
|
a + b |
|
a + c |
|
M [C] = P(C=1) |
|
; |
M[И] = |
|
a + b + с + d |
a + b + с + d |
|||
Дисперсии определяются: |
|
|
||
σ²с = (a + b) · (с + d) ;σ²и = ( a + b + с + d) ²
Окончательно:
R = COVси
√σ²с σ²и
(a + c) · (b + d) |
;covси = M[C x И] – M[C] x M[И]= |
ad – bc |
( a + b + с + d) ² |
( a + b + с + d) ² |
В различных точках координат <n,x> значения (знаки) R следующие:
R(0) = 0, R(p0) = 0, R(И) = +1, R(Д) = -1, R(1) > 0, R(2) > 0, R(3) < 0
R = 0 повсюду на линии 0 – p0
Для этого достаточно показать, что: ad – bc = n0(x - n p0)
На линии 0p0 справедливо: x = n·(X0/ n0) = np0 => ad – bc = 0 Обозначая : |L ∩ L© | = L , |Lи| = Lи, |Lc| = Lc, |L0| = L0
Перепишем R в координатах <L>:
R = |
LL0 – LиLc |
|
√LиLc(L0 – Lи)( L0 – Lc) |
||
|
43.Назначение, состав и структура лингвистического обеспечения ИС.
Лингвистическое обеспечение – это совокупность языковых средств, обеспечивающих гибкость представления и обработки информации с помощью АИС(автоматизированная поисковая система). Обычно ЛО включает языки запросов и отчетов, реализующие человеко-машинное взаимодействие, а также специальные языки определения и управления данными, обеспечивающие адекватность внутреннего представления и согласование внутреннего и внешнего представлений.
Лингвистическое обеспечение ИС – это совокупность языковых средств, позволяющих представить информационную составляющую ИС на различных этапах внутрисистемной обработки и взаимодействия с пользователем.
Такое определение предполагает выделение 2-х взаимообусловливающих аспектов использования ЛО: выражения смыслового содержания ИР и выражения информационной потребности пользователя.
Состав лингвистического обеспечения информационных систем может быть представлен следующей схемой
Лингвистическое обеспечение ИС
|
|
Языки |
|
Языки описания |
|||
|
манипулирования |
||
|
|
||
данных |
|
данными |
|
|
|
|
Терминологические
ИПЯ, структуры языки запросов
Иерархические |
|
Линейные |
|
Сетевые |
|
|
|
|
|
Такая схема представляет собой иллюстрацию, отображающую эволюцию и особенности применения языковых средств в ИС; ИПЯ – как средства выражения
смыслового содержания документов и информационной потребности пользователя. SQLкак средства управления данными. Терминологических структур – как моделей данных, с одной стороны, и понятийных систем, выражаемых средствами искусственного языка с естественной лексикой с другой.
44.Основные методы идентификации объектов.
Объекты – рассматриваемые в контексте понятия «информационная система» элементы реального мира, информацию о которых мы сохраняем и обрабатываем. Объект может быть материальным ()например служащий, изделие) и нематериальным (имя, понятие)
Типология задач идентификации объектов.
Уникальная Сущностная идентификация
Функциональня
Идентификация
объектов
|
|
|
Класификационная |
|
|
|
|
Идентификация |
|
|
Описательная |
|
|
||
Группы объектов |
|
|
|
|
|
|
Смешанная |
|
|
|
|
Задачи уникальной идентификации объекта можно условно разделить на 2 группы:
1.Выделить объект для определения или описания его персональных (индивидуальных) характеристических свойств в рамках конкретной предметной области – сущностная идентификация
2.Выделить объект, выполняющий в данное конкретное время некоторую уникальную функцию – функциональная идентификация
Недостаток любой уникальной идентификации – её неинформативность, т.е. отсутствие каких – либо явных признаков(атрибутов), характеризующих объект с содержательной стороны В основе идентификации групп объектов может использоваться один из следующих методов:
1) Классификационный Классификационная идентификация ориентирована на применение
специализированных условных обозначений для объектов, у которых выделенные свойства имеют одинаковые значения. В основе такой идентификации лежит использование мнемонических или классификационных кодов, однозначно характеризующих объект.
Мнемонический код предполагает однозначную расшифровку значений выделенных свойств объекта. Например, условное обозначение «Электронасос ГНОМ 100-25»:
Г – для грязной воды, Н – насос, О – одноступенчатый, М – многоблочный, 100 – с подачей 100 м³/ч, 25 – с напором 25 м.
Классификационный код устанавливает взаимнооднозначное соответствие характеристики объекта стандартным кодификаторам и классификаторам. Классификационные методы обеспечивают систематизацию объектов в соответствии с некоторой заданной классификационной схемой. Код, присвоенный отдельному классу(как и мнемоническое обозначение), обеспечивает его полную идентификацию в рамках конкретного классификатора.
2) Описательные методы идентификации.
Используются в тех случаях, когда необходимо идентифицировать конкретный объект или группу объектов путем описания произвольного набора его характеристик. Описательный метод предполагает наряду с указанием классификационных характеристик выделение дополнительных наборов свойств, углубляющих характеристику объекта и сужающих область поиска.
В ряде случаев для идентификации объектов используются ссылки на нормативные документы, содержащие описания конкретных характеристик (свойств, показателей, отличительных признаков). Тогда идентификация объекта включает наименование объекта и ссылку на документ, содержащий требования к этому объекту.
Одним из основных преимуществ описательного метода идентификации является возможность осуществления сопоставительного анализа однородных (родственных) объектов путем сравнивания характеристик, вошедших в их идентификацию. Такое сравнение позволяет выбрать объект, обладающий наилучшими характеристиками для заданных условий применения или обеспечивающий полную замену другого. Описательные методы широко используются в медицине, в криминалистике, в геологии.
3) Смешанные методы.
Предполагают использование при характеристике предмета всех возможностей и преимуществ как классификационных, так и описательных методов. Наряду с произвольным многосторонним описанием объекта могут быть заданы его атрибуты, определяющие принадлежность к определенному классу некоторой классификационной схемы, а также ссылки на нормативный документ, где помещены все его характеристики.
Преимущества методов идентификации группы объектов состоят в их большей информативности: идентификация объекта непосредственно содержит информацию, позволяющую, с одной стороны, группировать объекты, обладающие определенным набором признаков, и, с другой, выделить объекты с уникальными свойствами в рамках одной классификационной группы.
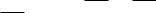
45.Классификация. Определение и формально–логические правила построения.
В основе любой классификации лежит принцип деления объектов рассматриваемой предметной области. Каждый объект с точки зрения решаемых классификацией задач характеризуется фиксированным множеством свойств, совокупность значений которых может говорить об эквивалентности (или близости) данного объекта некоторому множеству объектов. Назовем такие характеристические свойства объекта атрибутоми.
Классификация – выделение из екоторого множества объктов, принадлежащих универсальному классу, всех подклассов на основе значений выделенных в предметной области атрибутов и устонавление между выделенными подклассами отношений порядка.
Атрибуты, учавствующие в делении на классы, называются классификационными или основаниями деления.
Классификация должна подчиняться следующим логическим правилам.
1. очередной шаг классификации проводится только по одному атрибуту Пусть К – некоторый класс, который на основе заданного множества n значений некоторого атрибута разделен на подклассы k1, k2, k3, …, kn.
k1U k2 U k3 U … U kn = K;
ki ∩ kj= ø ; V i ≠ j , i = 1,n j=1,n.
2. получаемые в результате деления подклассы не должны пересекаться (в практике соблюдается редко)
3. деление на подклассы должно быть соразмерным. Классификационная схема характеризуется множеством атрибутов и множеством различных классов, которые могут быть выделены на базе зафиксированных множеств значений атрибутов.
46.Типы классификаций. Иерархические классификации. Примеры.
Типы классификаций:
1.Иерархические классификации
2.Фасетные классификации
3.Булевы классификации.
Иерархические классификации.
Если между классами установлено отношение порядка при пустом попарном пересечении соподчиненных классов, э то означает, что отношение порядка установлено и для классификационных атрибутов. Такие классификации называются древовидными или иерархическими.
В данном случае представлена классификационная структура, построенная для упорядоченного множества атрибутов {A,B,C} со значениями A = {V¹А, V²А, V³А}, B = {V¹B, V²B, V³B}, C = {V¹C, V²C}
Общие принципы построения иерархических классификаций таковы, что они не позволяют иметь в классификации один и только один исчерпывающий класс для каждой группы объектов.
Пример:
Рассмотрим в качестве исходного класса К класс «Преподаватели института», а в качестве оснований деления – соответственно следующие атрибуты: «факультет» (А) со значениями А = {«Экономический факультет», «Факультет управления», «Юридический факультет»}, «возраст» (В) со значениями В = {«до 40», «40-55», «старше 55»} и «ученая степень» (С) со значениями С = {«Имеет», «Не имеет»}. Применение основания деления А к исходному классу дает нам подклассы «Преподаватели экономического факультета» (К1), «Преподаватели факультета управления» (К2) и «Преподаватели юридического факультета» (К3). Применение признака В соответственно к классам К1, К2 и К3 дает нам подклассы «Преподаватели экономического факультета возраста до 40» (К11), «Преподаватели экономического факультета возраста 40-55» (К12), «Преподаватели экономического факультета старше 55» (К13) и т.д. наконец применение признака С соответственно к классам К11, К12, К13, К21, К22, К23, К31, К32 и К33 порождает подклассы «Преподаватели экономического факультета возраста до 40, имеющие ученую степень» (К111), «Преподаватели экономического факультета возраста до 40, не имеющие ученой степени» (К112) и т.д.
При построении этой классификации деление на каждом уровне иерархии, как того требует формально-логические правила, должно проводиться только по одному основанию. Но соблюдение формаьно-логических правил не устраняет ее главного недостатка – невозможность проведения группировки документов и информационного поиска по любому сочетанию характеристик: для построения иерархической классификации используется определенный ряд атрибутов (оснований деления), применяющихся только в одной последовательности.
Если приведенную на схеме классификацию использовать для информационного поиска по любому сочетанию атрибутов, взятых из некоторого данного множества, необходимо построить отдельные классы для всех возможных сочетаний этих атрибутов. Эффективность этого метода зависит от числа классов самого нижнего уровня иерархии (N), которое можно построить путем применения в разной последовательности исходного множества атрибутов. => чем больше N, тем выше трудоемкость процедуры классифицирования документов.
47.Типы классификаций. Фасетные классификации. Примеры.
Типы классификаций:
1.Иерархические классификации
2.Фасетные классификации
3.Булевы классификации.
Фасетные классификации.
При создании классификации возможна ситуация, при которой деление на классы проводится на основе всех возможных комбинаций атрибутов. Значения, которые может принимать отдельный атрибут, объединяются в ФАСЕТ. Каждый фасет дает разбиение всего универсального класса на подклассы первого уровня, число которых определяется мощностью фасета (количеством разных значений в фасете). Попарные пересечения классов первого уровня, принадлежащих разным фасетным разбиениям, дают множество классов второго уровня; тройные пересечения классов первого уровня дают множество классов третьего уровня и т.д. Количество уровней классификации совпадает с количеством классификационных атрибутов, но каждый отдельный класс при этом может быть взаимосвязан с двумя и более классами верхнего уровня. Классификации, построенные по такому принципу, называются фасетными или комбинированными.
Фасетная классификационная структура, построенная для упорядоченного множества атрибутов {A, B, C} со значениями A = {V¹А, V²А, V³А}, B = {V¹B, V²B, V³B}, C = {V¹C, V²C}, представлена в виде
В основе построения фасетных классификаций лежит фасетный анализ. Сущность фасетного анализа состоит:
1.в выделении в рассматриваемой ПрО атрибутов классификации;
2.в описании значений этих атрибутов множеством терминов. Атрибуты называются фасетами, а отдельный термин фасета – фокусом.
Фасетная классификация пользуется не только готовыми классами. Названия классов строятся на базе разных сочетаний фокусов фасетной формулы, при этом ненужные фасеты пропускаются.
Таким образом, Фасетные классификации значительно облегчают многоаспектное описание документов.
Пример: «Преподаватели института» с помощью совокупности фасетов: «факультет»
V¹А Экономический факультет
V²А Факультет управления V³А Юридический факультет «возраст»
V¹B до 40
V²B 40 - 55 V³B старше 55
«ученая степень» V¹с имеет
V²С не имеет
Если расположить термины первого фасета на одной горизонтали, а затем приписать к каждому из этих терминов поочередно все термины второго фасета и после этого повторить описанную процедуруц, используя термины третьего фасета, то получится иерархическая классификация. Таким образом, число всех возможных классов фасетной классификации не меньше числа иерархий, которые можно построить для эквивалентонной ей иерархической классификации. Однако в такой классификации можно построить классы «Преподаватели института, имеющие ученую степень», «Преподаватели в возрасте до 40 лет» и т.п.
48.Сравнительная характеристика иерархических и фасетных классификаций.
В любой иерархической классификации отдельные науки раз и навсегда разорваны разветвлениями жесткого классификационного дерева. Особенно трудно включать в иерархическую классификацию новые межотраслевые предметы и области исследований. требуется периодическое изменение общей структуры той или иной реальной иерархической классификации, новый вариант иерархической классификации устаревает раньше, чем удается завершить работу по переклассифицированию документов. Поэтому выбирается путь соответствующей модификации уже существующих таблиц иерархической классификации, что придает ей все более условный характер.
Критерий, определяющий число возможных группировок для N классификационных атрибутов, характеризует количество подмножеств атрибутов, которые могут быть использованы для формирования класса. В случае иерархической классификации с зафиксированной последовательностью атрибутов значение критерия равно числу уровней классификационного дерева, а в случае фасетной классификации
— сумме сочетаний из N атрибутов по одному, двум, трем и так далее до N.
Критерии |
Иерархическая |
Фасетная |
|
Структура |
Жесткая, задается |
Учитывает все |
|
|
фиксированной |
многообразие сочетаний |
|
|
последовательностью |
классификационных |
|
|
классификационных |
признаков |
|
|
признаков |
|
|
Механизм построения |
Простой, строго |
Сложный |
|
|
фиксированный |
|
|
Число возможных |
N (для зафиксированной |
N |
i |
группировок для N |
последовательности |
Σ С N |
|
классификационных |
классификационных |
i=1 |
|
атрибутов |
атрибутов) |
|
|
Возможность группировать |
Отсутствует |
Присутствует |
|
объекты по заранее не |
|
|
|
предусмотренным |
|
|
|
сочетаниям признаков |
|
|
|
Внесение изменений |
Жесткая структура, которая |
Возможна простая |
|
|
приводит к сложности |
модификация всей системы |
|
|
внесения изменений, так как |
классификации без |
|
|
приходится перераспределят |
изменения структуры |
|
|
все классификационные |
существующих |
|
|
группировки |
группировок |
|
Многоаспектное описание |
Невозможно |
Возможно |
|
документов |
|
|
|
Информационный поиск по |
Не предусмотрен |
Предусмотрен |
|
любому сочетанию |
|
|
|
атрибутов |
|
|
|
Механизм пересмотра |
Требует перестройки всей |
Требует добавления новых |
|
классификации (изменение |
классификации |
классов (ранее построенны |
|
состава атрибутов, |
|
классы не меняются) |
добавление новых значений |
|
|
Пригодность для каталогов |
Пригодна |
Непригодна |
и указателей, имеющих |
|
|
любую физическую форму |
|
|
Расход квалифицированног |
Не требует применения |
Требует применения |
труда |
высококвалифицированного |
высококвалифицированног |
|
труда |
труда |
49.Кодирование объектов. Системы кодирования. Примеры.
Кодирование - обозначение, при котором любой объект или явление однозначно отождествляется кодовым словом.
Код - это символ, посредством которого объекты предметной области могут быть представлены с целью хранения в памяти ЭВМ и вывода информации на любой носитель.
Совокупность методов и правил кодирования объектов классификации называется системой кодирования.
Кодирование предназначено для представления информации в виде, удобном при обработке на ЭВМ, в целях экономии места записи, для однозначного описания объектов.
При разработке кодов должны учитываться следующие требования:
-система кодирования должна соответствовать действующей системе классификации;
-основание кода, то есть количество знаков, должно быть минимальным;
-кодовое обозначение должно иметь резерв для кодирования объектов, вводимых дополнительно Запись формализованной идентификации объекта проводится с помощью условных
обозначений в виде знака или группы знаков по определенным правилам. Условное обозначение объекта при этом называется кодом, а совокупность методов и правил условного обозначения — системой кодирования. Ш Таким образом, кодирование — это процесс присвоения условных обозначений (кодов) объектам и классификационным группам в соответствии с определенной системой кодирования. Код в системе кодирования
задается тройкой: с=(A, L, S),
где А — алфавит (множество символов, используемых при записи кода),
L — длина (число позиций в коде); S — структура кода (порядок расположения в коде символов, используемых для обозначения классификационного атрибута). Различают следующие типы алфавитов: цифровой, буквенный и смешанный. Структура кода представляет собой, как правило, графическое изображение последовательности расположения символов.
Код характеризуется следующими параметрами:
•степенью информативности, рассчитываемой как частное от деления общего количества характеристических атрибутов на длину кода;
•коэффициентом избыточности, который определяется как отношение максимально возможного количества закодированных объектов к фактическому количеству объектов.
Наиболее широкое применение в практике кодирования информации находят цифровые коды.
коды должны удовлетворять следующим основным требованиям:
•однозначно идентифицировать объекты и (или) группы объектов;
•иметь минимальное число знаков (минимальную длину), достаточное для кодирования всех объектов заданного множества в заданной системе кодирования;
•иметь достаточный резерв для кодирования вновь возникающих объектов кодируемого множества;
•быть удобными для использования человеком, а также для компьютерной
обработки закодированной информации;
• обеспечивать возможность автоматического контроля ошибок при вводе в
компьютерные системы.
Ориентируясь на два типа идентификации объектов можно выделить два типа систем кодирования.
регистрационные системы кодирования, поддерживают такие методы методы логического упорядочения объектов с присваиванием отдельному объекту некоторого кода, определяющего место объекта в принятом логическом порядке. Для поддержки уникальной идентификации. I
При использовании классификационных схем для идентификации группы объектов кодирование отдельного объекта состоит в присвоении объекту кода определенного класса классификации. Такие системы кодирования названы классификационными.
С точки зрения длины кода: системы кодирования кодами фиксированной длины и системы кодирования кодами переменной длины.
В кодах фиксированной длины каждый разряд идентифицирует конкретный атрибут классификационной схемы, коды фиксированной длины кодируют только значения характеристических атрибутов.
Коды переменной длины ориентированы на идентификацию значений тех характеристических атрибутов, которые определяют классификационную группу. для произвольной последовательности кодируется не только значение характеристического атрибута, но и сам атрибут.
50.Назначение, структура и использование информационно-поисковых тезаурусов.
Для уменьшения количества терминов в ПО вводят ИПТ (тезаурус - синоним), в котором отражаются устойчивые связи между понятиями данной предметной области.
Тезаурус – семантическая сеть, в которой понятия связаны регулярными и устойчивыми семантическими отношениями: иерархическими (имеет место нарушение правильной структуры дерева), ассоциативными, эквивалентности. Тезаурус является лексическим инструментом ИПС для осуществления поиска.
Информационно-поисковые тезаурусы. (ИПТ) позволяют решить проблему соотнесения:
•авторской терминологии (понятий и слов естественного языка, которые автор использует для обозначения этих понятий);
•терминологии системы (понятий и терминов, которые используются для выражения этих понятий при вводе документов в ИПС);
•терминологии потребителя (понятий и терминов, которые потребитель использует для представления этих понятии при формировании запросов).
тезаурус состоит из контролируемого, но изменяемого словаря терминов, между которыми указаны смысловые связи. представляет собой перечень лексических единиц, упорядоченных по систематическому и алфавитному принципам Лексические единицы обычно делятся на дескрипторы и аскрипторы.
Дескриптор — лексическая единица, предназначенная для использования в поисковых образах документов и/или запросов.
Аскриптор— лексическая единица, которая в поисковых образах документов (запросов) при поиске или обработке информации подлежит замене на дескриптор. ИПТ подразделяют на два типа:
1)тезаурусы, выделяющие среди своих лексических единиц дескрипторы и аскрипторы;
2)тезаурусы, все лексические единицы которых являются дескрипторами. Рассмотрим структуру и виды связей на примере ИПТ по информатике [Информационно-поисковый тезаурус, 1987].
Лексические единицы тезауруса поделены на дескрипторы и ключевые слова — не дескрипторы и нормализованы следующим образом:
•имена существительные, обозначающие исчисляемые объекты, представлены в форме именительного падежа множественного числа;
•существительные, обозначающие неисчисляемые объекты, представлены в форме именительного падежа единственного числа;
•для всех словосочетаний-дескрипторов, включая словосочетания с именем собственным, используется естественный (прямой) порядок слов.
Лексические единицы в тезаурусе организованы в виде словарных статей. Словарная статья дескриптора состоит из собственно дескриптора (заглавного дескриптора) и списка дескрипторов и ключевых слов, связанных с заглавным дескриптором по смыслу.
Общеупотребительные аббревиатуры входят в тезаурус в качестве дескрипторов. Каждая из них снабжена расшифровкой, которая приводится в косых скобках строчными буквами.
В дескрипторной статье лексические единицы располагаются в следующем порядке:
•заглавный дескриптор;
•ключевые слова, условно синонимичные заглавному дескриптору;
•вышестоящие дескрипторы;
•нижестоящие дескрипторы;
•дескрипторы, связанные с заглавным дескриптором одним из ассоциативных отношений.
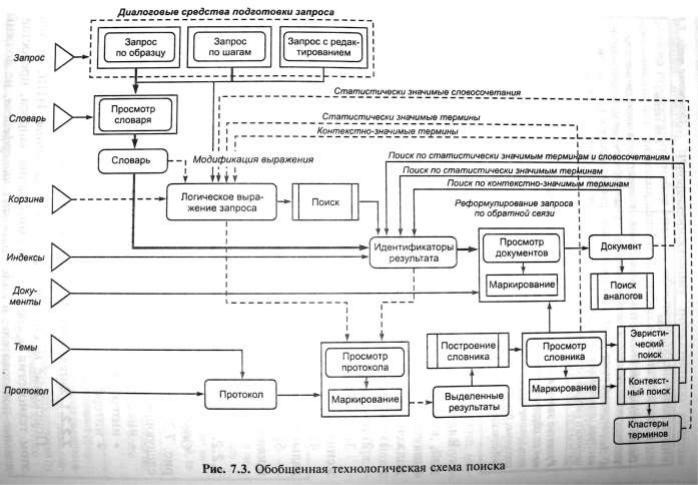
51.Обобщенная технологическая схема и компоненты информационного поиска.
Обобщенная технологическая схема поиска имеет следующие группы интерфейсных средств:
•интерфейс формирования запроса;
•интерфейс поискового модуля;
•интерфейс обработки результата и развития поиска.
52.Типовые реализации интерфейсов подготовки поисковых выражений, их особенности.
Поисковые механизмы построены на основе ИПЯ, но при этом технология и средства формирования запроса, предоставляемые пользователю в виде поисковых интерфейсов. Поисковые интерфейсные средства (в контексте форм выражения запроса) можно разделить на два класса.
-класс интерфейсных средств, реализующих «технологию» типа «укажи и выбери»
— это конструкторы запросов, которые позволяют, используя термины поисковых словарей или других терминологических структур (тезаурусов, рубрикаторов, словников), в режиме диалога построить выражение той или иной сложности, которое на следующем шаге (выполнения поиска) даст результат.
-средства, реализующие «технологию» типа «укажи и получи». пользователь выделяет в отображаемом объекте значимые с его точки зрения и, используя механизмы поиска по сходству (поиск аналогов, эвристический поиск, поиск с использованием обратной связи), получает выдачу, минуя этап составления поискового выражения.
В основу формирования поискового запроса по технологии «укажи и выбери» положено три различных подхода к построению выражений запросов разной степени сложности:
• конструктор запроса «по образцу» Имеет жестко фиксированную модель поискового условия, предполагающую обязательное выполнение частных условий, относимых к полям, выбираемым из предопределенных списков.
• конструктор формирования запроса «по шагам» Поисковые термины также выбираются из словаря, но могут связываться любыми отношениями. позволяет формировать достаточно сложные предложения запроса последовательным наращиванием либо выражения условия, либо всего предложения.
• конструктор формирования логического выражения запроса - реализуется путем непосредственного набора выражения запроса с возможностью обращения в произвольном порядке к словарям, спискам имен полей и т. д.
конструктор формирования логического выражения допускает скобочное выражение любой сложности. конструктор формирования запроса «по образцу» — структура выражения фиксирована шаблоном, а оператор, связывающий выражения операндовзначений, относимые к разным полям, фиксирован (обычно оператором И).
конструктор формирования запроса «по шагам» - структура выражения операнда-
значения ограничена линейной формой выражения без вложенности.