

Работа № 3. Оценки
1. Cpавнение оценок
1.1. Определения
Пусть x1, ..., xn — выборка , т.е. n независимых испытаний случайной величины X , имеющeй функцию распределения F(x / a), зависящую от параметра a, значение которого неизвестно. требуется оценить значение параметра a.
Оценкой â = (x1, ..., xn) называется функция наблюдений, используемая для приближенного определения неизвестного параметра. Значение â оценки является случайной величиной, поскольку (x1, ..., xn) — случайная величина (многомерная).
Свойства оценок
1. Оценка â= (x1, ..., xn) называется состоятельной, если при n â a по вероятности при любом значении a.
2. Оценка â = (x1, ..., xn) называется несмещенной, если при любом a Mâ = M(x1, ..., xn) = a.
состоятельность - обязательное свойство используемых оценок. свойство несмещенности является желательным; многие применяемые оценки свойством несмещенности не обладают.
3. Оценка * называется оптимальной, если для неё средний квадрат ошибки
M(â- a)2= M[*(x1, ..., xn) - a]2= min M[(x1, ..., xn) - a]2
минимален среди всех оценок {}; здесь критерием качества оценки принят квадрат ошибки (â - a)2. В более общей ситуации, если критерием качества служит некоторая величина L(â, a), называемая функцией потерь (или функцией штрафа), то оптимальная оценка та, для которой минимальна величина ML(â, a); последняя есть функциея неизвестного a и называется функцией условного риска. Ясно, что оптимальной оценки может не существовать (так как характеристикой является функция, а не число).
1.2. Постановка конкретной задачи.
Пример. Пусть на заводе имеется большая партия из N (тысячи) транзисторов, используемых для сборки некоторого прибора. Выходные параметры прибора (например, надежность, уровень шума, вероятность выхода из режима и т.д.) зависят от обратных токов транзисторов; обратный ток у разных экземпляров различен, и потому можно считать его случайной величиной, причем, как известно технологам, распределённой равномерно в диапазоне от 0 до Imax, где Imax —порог отбраковки, установленный на заводе - изготовителе транзисторов. Следовательно, выходные параметры прибора определяются величиной Imax. Предположим, что по каким-либо причинам значение Imax производителю приборов неизвестно. Ясно, что в этом случае из партии нужно случайным выбором извлечь n (сравнительно немного: десятки) транзисторов, измерить их ток, и по измерениям оценить Imax (неизвестный параметр а). Таким образом, возникает статистическая задача: по наблюдениям x1, ..., xn над случайной величиной , распределённой равномерно на отрезке [0, a], оценить неизвестный параметр a.
сравним три способа оценивания (три оценки):
оценку, полученную методом моментов,
â1
=
![]() ,
(1)
,
(1)
оценку, полученную методом максимального правдоподобия (после исправления смещённости),
â2
=
![]() max
xi
(2)
max
xi
(2)
и оценку, полученную методом порядковых статистик,
â3
= 2
![]() 0.5
= x(k)
+ x(k+1),
(3)
0.5
= x(k)
+ x(k+1),
(3)
где
![]() 0.5
=
0.5
=![]()
![]() —
выборочная квантиль порядка 0.5, т.е.
выборочная медиана; x(k)
—
член вариационного ряда с номером k;
здесь полагаем n = 2k. Точность этих оценок
можно сравнить теоретически и
экспериментально (статистически).
—
выборочная квантиль порядка 0.5, т.е.
выборочная медиана; x(k)
—
член вариационного ряда с номером k;
здесь полагаем n = 2k. Точность этих оценок
можно сравнить теоретически и
экспериментально (статистически).
Замечание. Точность, однако, не является единственным критерием качества оценок. Весьма важно, например, свойство устойчивости оценки к изменению закона распределения или к засорению; в этом смысле, как оказывается, â3 — наиболее хороша, а â2 — наименее; действительно, пусть, например, в нашу выборку случайно попало наблюдение, резко превосходящее все остальные (в случае с партией триодов, попался триод, не прошедший отбраковку); значение оценки â2 резко изменится, значение â3 почти не изменится.
1.3. Теоретическое сравнение оценок
Все три оценки несмещённые, что можно проверить методами теории вероятностей. определим дисперсии оценок :
Dâ1
= D(
![]() ) =
) =
![]() ,
,
Dâ2
= D(![]() max
xi
) =
max
xi
) =
![]() ,
,
Dâ3
= D(x(k)
+ x(k+1))
![]() ,
,
откуда ясно, что â2 — наиболее точная оценка, а â3 — наименее.
1.4. Статистическое сравнение оценок
Далеко не всегда удается аналитически вычислить дисперсию оценки. Как экспериментально определить, какой из оценок пользоваться? По одной выборке нельзя судить о разбросе значений оценки, поскольку значение всего одно; необходимо иметь несколько выборок, например, k = 20, (или хотя бы 5 10), оценить разброс значений для каждой оценки и предпочесть ту оценку (тот способ оценивания), для которой разброс меньше. Если же выборка всего одна, то следует (если n достаточно велико) разбить её случайным образом на несколько выборок, и по ним сравнивать качество оценок.
Сформируем k =20 выборок из распределения R[0, a=10] объема n для различных n=10, 40, 160 и определим разброс оценок. Характеристиками разброса значений а1,...,аk оценки â будем считать размах
w = max ai - min ai и среднеквадратичное отклонение (ско)
Sa=
![]() ,
,
![]() .
.
Выполнение в пакете STATISTICA
Оценивание по выборкам объема n = 10
Шаг 1. Сформируем k =20 выборок объема n =10 и определим значения оценок a1, a2, a3 на каждой выборке. Создадим таблицу требуемых размеров (20v10c).
Шаг 2. Генерация выборок
Последовательность действий:
клавиша Vars - All specs... (спецификация всех) - появляется окно-таблица, в первом столбце которой находятся названия переменных (var1, var2,..., var20), а в Long Name - функция расчета. Выделим первую клетку этого столбца и введем = rnd(10)
генерация случайных чисел, равномерно распределенных на отрезке [ 0, 10 ]. Скопируем эту запись в буфер обмена: Copy, а затем перенесем ее в остальные клетки (со 2 по 20) - ОК.
Далее нажмите кнопку x = ? - All variables - OK.
Шаг 3. Определим статистики, по которым вычисляются оценки. Выделим всю матрицу данных, затем найдем Sums (сумму), Max’s (максимальное) и Medians (медиану).В нижней части таблицы появляются 3 строки с требуемыми статистиками.
Для новых строк введем более удобные обозначения: Sumа, Maximum и Mediana, для этого дважды кликните по имени стоки.
Шаг 4. Транспонируем нашу матрицу, которая теперь имеет размер 20v13с в матрицу 13v 20c (чтобы совершать действия со столбцами): Data - Transponse - File.
Шаг 5. Вычислим значения оценок â1, â2 и â3 на 20 выборках.
Добавим в матрицу 3 столбца (с 14 по 16 для значений оценок) Vars - Add - Number of vars: 3 - after: (после последней) и определим значения оценки â1 - кн. Vars - Specs... (спецификация) - Name: A1 - Long name, согласно (1): = 2/10 Sumа
Аналогично определим значения оценок â2 и â3 ; различными будут операторы; для â2 по (2): = 11/10 Maximum
для â3 по (3): = 2 Medianа
Шаг 6. Сравнение оценок графически: Graphs - 2D Graphs - Line Plots (Variables) - в окне Variables: А1, A2, A3, Graphs Type : Multiple, - ОК.
Из графика видно, что значения оценок находятся в окрестности 10, и что оценка â2 имеет разброс меньше, чем â1 и â3 .
Шаг 7. Определим характеристики разброса для оценок. Выделим столбцы a1, a2, a3 – и расчитаем для них- SD’s (стандартное отклонение), затем аналогично: Min’s, Max’s. (см. выше). Выписываем результаты в тетрадь и вычисляем размах w. Сравнение размахов w и стандартных отклонений Sа для трех оценок показывает, что оценка â2(х1, ... , хn) наиболее точна, а оценка â3(х1, ... , хn) - наименее.
Задание
Проведите оценивание по выборкам объема n=40 и n=160 и итоговое сравнение аналитически и графически.
Заролните следующую табдицу.
Таблица 1. Разброс значений оценок.
|
|
|
â1 |
â2 |
â3 |
|
|
amin |
|
|
|
|
n = 10 |
amax |
|
|
|
|
|
w |
|
|
|
|
|
Sa |
|
|
|
|
|
amin |
|
|
|
|
n = 40 |
amax |
|
|
|
|
|
w |
|
|
|
|
|
Sa |
|
|
|
|
|
amin |
|
|
|
|
n = 160 |
amax |
|
|
|
|
|
w |
|
|
|
|
|
sa |
|
|
|
Убедитесь в том, что приведенные результаты экспериментального сравнения 3 способов обработки наблюдений показывают следующее:
1. Значения оценок концентрируются в окрестности оцениваемого параметра (проявление свойства несмещенности оценок).
2. С ростом числа наблюдений точность (величина разброса) оценок улучшается (проявление свойства состоятельности).
3. Различные оценки различаются по величине средней ошибки, откуда ясно, что различные способы обработки наблюдений нужно сравнивать по величине среднего значения некоторого критерия качества, например, среднего значения квадрата ошибки.
Работа N4. Доверительные границы и интервалы
результатом применения точечной оценки â(x1,...,xn) является одно числовое значение; оно не дает представления о точности, т.е. о том, насколько близко полученное значение к истинному значению параметра. Интуитивно ясно, что такое представление может дать, например, дисперсия оценки, так что истинное значение должно находиться где-то в пределах
â
(24)![]()
Внесем уточнения.
Основные положения
Определения и построение интервалов.
Пусть (x1,...,xn) x - n независимых наблюдений над случайной величиной с законом распределения F(z/a), зависящим от параметра a, значение которого неизвестно.
Определение
1. Функция
наблюдений a1(x1,...,xn)
(заметим, что это случайная величина)
называется нижней доверительной границей
для параметра a с уровнем доверия РД
(обычно близким к 1), если при любом
значении
![]()
P{ a1(x1,...,xn) a} PД
Определение
2. Функция
наблюдений a2(x1,...,xn)
(случайная величина) называется верхней
доверительной границей для параметра
![]() с уровнем доверия РД
, если при любом значении
с уровнем доверия РД
, если при любом значении
![]()
P{ a2(x1,...,xn) a } PД .
Определение 3. Интервал со случайными концами (случайный интервал)
I(x) = ( a1(x), a2(x) ) ,
определяемый двумя функциями наблюдений, называется доверительным интервалом для параметра a с уровнем доверия РД , если при любом значении a
P{ I(x) a } P{ a1(x1,...,xn) a a2(x1,...,xn) } PД ,
т.е. вероятность (зависящая от a) накрыть случайным интервалом I(x) истинное значение a - велика: больше или равна РД.
Построение доверительных границ и интервалов.
Для построения доверительного интервала (или границы) необходимо знать закон распределения статистики =(x1,...,xn), по которой оценивается неизвестный параметр (такой статистикой может быть оценка = â(x1,...,xn) ). Один из способов построения состоит в следующем. Предположим, что некоторая случайная величина = (, a), зависящая от статистики и неизвестного параметра a такова, что
1)
закон распределения
![]() известен и не зависит от a;
известен и не зависит от a;
2)
(,
a) непрерывна и монотонна по
![]() .
.
Выберем
диапазон для
![]()
интервал
интервал
![]() так, чтобы попадание в него было
практически достоверно:
так, чтобы попадание в него было
практически достоверно:
P{ f1 (, a) f2 } PД , (1)
для
чего достаточно в качестве
![]() и
и![]() взять квантили распределения
взять квантили распределения![]() уровня (1- РД
)/2 и (1+ РД
)/2 соответственно. Перейдем в (1) к другой
записи случайного события, разрешив
неравенства относительно параметра a;
получим (полагая, что
уровня (1- РД
)/2 и (1+ РД
)/2 соответственно. Перейдем в (1) к другой
записи случайного события, разрешив
неравенства относительно параметра a;
получим (полагая, что
![]() монотонно возрастает по
монотонно возрастает по![]() ):
):
P{ g(, f1) a g(, f2) } PД .
Это соотношение верно при любом значении параметра a (поскольку это так для (1)), и потому, согласно определению, случайный интервал
( g(, f1) , g(, f2) )
является
доверительным для a с уровнем доверия
РД
. Если
![]() убывает по
убывает по![]() ,
интервалом является (g(,
f2)
, g(,
f1)
).
,
интервалом является (g(,
f2)
, g(,
f1)
).
Для
построения односторонней границы для
a выберем значения
![]() и
и![]() так, чтобы
так, чтобы
P{ (, a) f1 } PД , f1=Q(1 - PД )
или P{ (, a) f2 } PД , f2 = Q( PД ),
где
![]()
квантиль уровня
квантиль уровня
![]() .
После разрешения неравенства под знаком
.
После разрешения неравенства под знаком![]() получим односторонние доверительные
границы для a.
получим односторонние доверительные
границы для a.
Пример.
Доверительный интервал с уровнем доверия
РД
для среднего a нормальной совокупности
при известной дисперсии ![]() .
.
Пусть
x![]() ,
... , xn
- выборка из нормальной N(a,
,
... , xn
- выборка из нормальной N(a, ![]() )
совокупности. Достаточной оценкой для
а является
)
совокупности. Достаточной оценкой для
а является
â
= â(x![]() ,...,xn)
=
,...,xn)
=
![]() ,
,
распределенная
по закону N(a,
![]() )
; пронормируем её, образовав случайную
величину
)
; пронормируем её, образовав случайную
величину
![]() ,
(2)
,
(2)
которая распределена нормально N(0,1) при любом значении а.
По заданному уровню доверия РД определим для отрезок -fp, fp так, чтобы
![]() ,
(3)
,
(3)
т.е. fp - квантиль порядка (1+ РД )/2 распределения N(0,1); заметим, что зависит от а , но (3) верно при любом значении а. Подставим в (3) выражение для из (2) и разрешим неравенство под знаком вероятности в (3) относительно а ; получим соотношение
![]() ,
(4)
,
(4)
верное при любом значении а. под знаком вероятности две функции наблюдений
![]() ,
,
![]() (5)
(5)
определяют случайный интервал
I( x1, ... , xn) =(a1( x1, ... , xn), a2( x1, ... , xn)), (5a)
который в силу (4) обладает тем свойством , что накрывает неизвестное значение параметра а с большой вероятностью РД при любом значении а, и потому, по определению доверительно интервала, он является доверительным с уровнем доверия РД .
В общем случае случайную величину в (1) можно построить следующим образом. Определим функцию распределения F(z/a) статистики (F, конечно, зависит от а). Для непрерывной случайная величина (, а) F( /a), как нетрудно видеть, распределена равномерно на отрезке 0, 1 при любом значении а; приняв f1= (1- PД)/2, f2 =(1+PД)/2, будем иметь в качестве (4)
P{f1 F( /a) f2} = PД .
Для дискретной ситуация аналогична.
Можно рассуждать иначе: при любом фиксированном значении а определим отрезок z1(a), z2(a) так, что
P{ z1(a) z2(a) } РД ; (6)
ясно, что в качестве z1 и z2 можно взять квантили, т.е. определить из условий
F(z1/a)=(1- РД )/2, F(z2/a)=(1+ РД )/2.
Если z1(a) и z2(a) монотонно возрастают по а, то, разрешив два неравенства под знаком Р в (6) и учитывая, что z1(a) < z2(a), получим:
P{ z2-1() a z1-1() } РД ,
вверное при любом а; ясно, что интервал ( z2-1() , z1-1() ), определяемый двумя функциями от , является доверительным с уровнем доверия РД.
Уровень доверия
Уровень доверия РД означает, что правило определения интервала дает верный результат с вероятностью РД, которая обычно выбирается близкой к 1, однако, 1 не равно. Убедимся статистически на примере в том, что доверительный интервал с уровнем доверия РД может не содержать (с малой вероятностью 1- РД ) истинное значение параметра.
Пример. рассмотрим приведенный в (5) случайный интервал I(x1, ..., xn), который при любом значении а накрывает это значение с большой вероятностью РД:
Р{ I(x1,...,xn) a } = РД ,
и потому, если пренебречь возможностью осуществления события aI, имеющего малую вероятность (1-РД), можно считать событие aI(x1,...,xn) практически достоверным, т.е. можно верить тому, что вычисленный по конкретным наблюдениям x1,...,xn интервал I содержит неизвестное значение параметра а.
Испытаем интервал (5) на 50 выборках объема n=10 для трех уровней доверия РД : 0.9 , 0.99 , 0.999 (соответственно, три значения fp) .
При РД = 0.9 число неверных из k =50 результатов окажется в окрестности 5, так как среднее число неверных
k(1- РД) = 5;
при РД =0.99 появление хотя бы одного неверного из k =50 весьма вероятно: вероятность этого события
1- РДk=1-0.9950 0.61;
при РД =0.999 появление хотя бы одного неверного весьма сомнительно: вероятность этого события
1- РДk=1-0.99950 0.05.
Задание.
1. Определить, сколько раз из k =50 доверительный интервал оказался неверным, это сделаем для трех значений РД . Графики для РД =0.9 и РД =0.99 распечатать. Выполнение в пакетах см. в пп. 2 - 4.
2. Провести аналогично 50 испытаний доверительного интервала (7) - (9) для случая неизвестной дисперсии.
Интервалы для параметров нормального распределения
Пусть х1, … ,хn - выборка из нормального N(a,2) распределения; значения среднего а и дисперсии 2 неизвестны. Оценки для а и 2:
![]() ,
,
![]() .
(7)
.
(7)
Как известно, доверительным интервалом для среднего а с уровнем доверия РД при неизвестной дисперсии является интервал
I(x) = (a1(х), a2(х) ), (8)
где
![]() ,
,![]() , (9)tp
- квантиль
порядка (1+ РД)/2
распределения Стьюдента с n-1
степенями свободы.
, (9)tp
- квантиль
порядка (1+ РД)/2
распределения Стьюдента с n-1
степенями свободы.
Доверительным интервалом для стандартного отклонения с уровнем доверия РД является интервал
I (x)=(1(х), 2(х)) , (10)
где
![]() ,
,![]() , (11)
, (11)
t1 и t2- квантили порядков соответственно (1+ РД)/2 и (1- РД)/2 распределения хи-квадрат с n-1 степенями свободы.
Сгенерируем выборку объема n=20 из нормального распределения с параметрами a =10, 2=22=4 и определим доверительные интервалы для a и с уровнем доверия РД : 0.8 , 0.9 , 0.95 , 0.98 , 0.99 , 0.995 , 0.998 , 0.999. Результаты выпишем в виде таблицы. C ростом РД интервал расширяется, с ростом n - уменьшается.
Выполнение см. в пп. 2 - 4.
Если нас интересуют не интервалы, а верхние или нижние доверительные границы, то, как известно, они определяются теми же формулами (9) è (11), однако, значения порогов t изменяются. Например, нижней доверительной границей для a с уровнем доверия РД является значение
![]() ,
,
где tp - квантиль порядка РД распределения Стьюдента с n-1 степенями свободы, а верхней границей для с уровнем доверия РД является
![]() ,
,
где t2 - квантиль порядка 1- РД распределения хи-квадрат с n-1 степенями свободы.
Задание: определить верхние доверительные границы для а и с уровнем доверия РД = 0.95 .
Задание на самостоятельную работу
1) для заданной задачи построить оценку заданным методом (варианты заданий см. ниже);
2) построить доверительный интервал, основанный на этой оценке;
3) сгенерировать выборку заданного объема;
4) вычислить доверительный интервал.
Отчет по работе должен содержать:
постановки вопросов, формулы,
графики испытания доверительного интервала для 2-х случаев: с известной и неизвестной дисперсией (по п. 1.2),
таблицу доверительных интервалов для различных РД (по п. 1.3),
вывод формул для оценок и интервалов, сгенерированную выборку и вычисленный интервал (по п. 1.4) .
Варианты задач.
Задача1. Расстояние а до некоторого объекта измерялось n1 раз одним прибором и n2- вторым; результаты х1,…,хn1; y1,…,yn2. Оба прибора при каждом измерении дают независимые случайные ошибки, нормально распределенные со средним 0 и стандартными отклонениями 1 и 2 соответственно. Методом максимального правдоподобия построить оценку â для а и доверительный интервал с уровнем доверия РД .
Варианты исходных данных
|
¹ |
n1 |
n2 |
1, êì |
2, êì |
Ðä |
a, êì |
|
1 |
5 |
10 |
3 |
5 |
0.95 |
300 |
|
2 |
8 |
12 |
3 |
5 |
0.98 |
300 |
|
3 |
10 |
15 |
3 |
5 |
0.95 |
300 |
|
4 |
5 |
10 |
4 |
6 |
0.98 |
350 |
|
5 |
8 |
12 |
4 |
6 |
0.95 |
350 |
|
6 |
10 |
15 |
4 |
6 |
0.98 |
350 |
|
7 |
5 |
10 |
5 |
8 |
0.95 |
400 |
|
8 |
8 |
12 |
5 |
8 |
0.98 |
400 |
|
9 |
10 |
15 |
5 |
8 |
0.95 |
400 |
измерения получить моделированием с заданным параметром а.
Решение (без вывода). Оценка
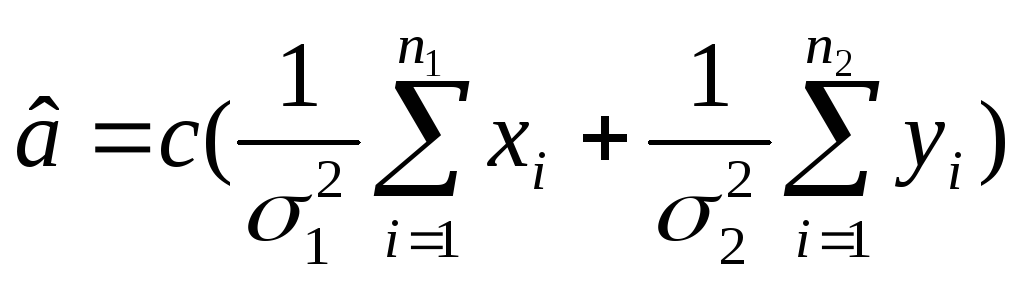 ,
где с=
,
где с=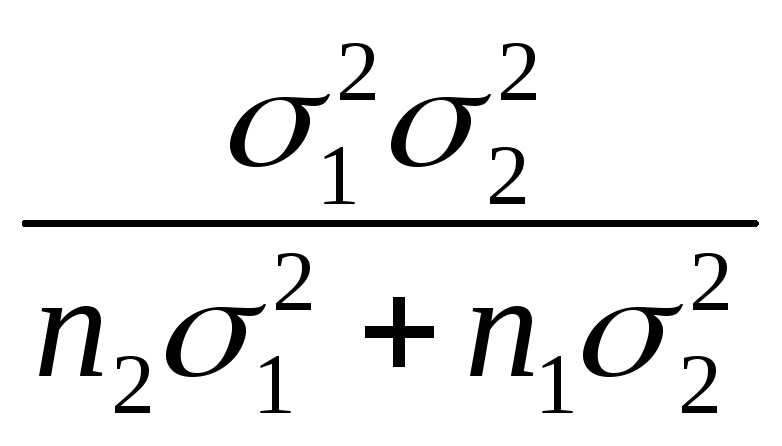 ;
;
доверительный интервал
I=(![]() ,
,![]() ),
),
где
![]() - квантиль порядка (1+РД)/2
распределения N(0,1).
- квантиль порядка (1+РД)/2
распределения N(0,1).
Задача 2. Изготовлена большая партия из N=10000 приборов. Известно, что время безотказной работы случайно и распределено по показательному закону с плотностью
![]() ,
x
0
,
x
0
С целью определения значения параметра а этой партии были поставлены на испытания n приборов; времена безотказной работы оказались равными х1,…,хn. Методом моментов построить оценку для а и доверительный интервал с уровнем доверия РД . Кроме того, построить доверительный интервал для числа М приборов, имеющих время безотказной работы менее 50 часов.
Варианты исходных данных
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
n |
20 |
25 |
30 |
20 |
25 |
30 |
20 |
25 |
30 |
|
ÐД |
0.95 |
0.99 |
0.95 |
0.99 |
0.95 |
0.99 |
0.95 |
0.99 |
0.95 |
|
à |
300 |
400 |
500 |
300 |
400 |
500 |
300 |
400 |
500 |
измерения получить моделированием с заданным параметром а.
Решение (без вывода). Оценка
![]() ;
;
доверительный интервал для а
Ia
= (![]() ,
,
![]() ),
),
где t1=Q(2n, (1-РД)/2), t2=Q(2n, (1+РД)/2) - квантили распределения хи-квадрат с 2n степенями свободы; доверительный интервал для М
IM
= ( N(1- exp(-![]() )),
N(1- exp(-
)),
N(1- exp(-![]() ))
).
))
).
Задача 3. Некоторое неизвестное расстояние а измерялось с аддитивной случайной ошибкой , распределенной по закону Коши с плотностью
p(
x ) =
![]() , -
< x < .
, -
< x < .
По результатам х1,…,хn независимых измерений методом порядковых статистик построить оценку для а и приближенный доверительный интервал с коэффициентом доверия РД .
Варианты исходных данных
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
n |
30 |
40 |
50 |
30 |
40 |
50 |
30 |
40 |
50 |
|
b |
3 |
4 |
5 |
6 |
3 |
4 |
5 |
6 |
3 |
|
ÐД |
0.95 |
0.98 |
0.95 |
0.98 |
0.96 |
0.98 |
0.95 |
0.98 |
0.95 |
|
a |
15 |
20 |
25 |
15 |
20 |
25 |
15 |
20 |
25 |
измерения получить моделированием с заданным параметром а.
Решение (без вывода).Оценкой для а является выборочная медиана - порядковая статистика с номером [n/2]+1
![]() ,
,
или
![]()
(у этих статистик асимптотические свойства одинаковы). Приближенный доверительный интервал, основанный на асимптотическом распределении выборочной р-квантили
I=(![]() ),
),
где tp=Q((1+РД)/2) - квантиль порядка (1+РД)/2 распределения N(0,1).
Задача
4. В водоеме обитает некоторая биологическая
популяция, состоящая из смеси особей
двух возрастов. Длина особи - случайная
величина, распределенная по нормальному
закону N(
ai,
i2
), где i=1,2
- индекс, относящийся к возрасту. С целью
определения доли q
особей 1-го возраста проведен отлов n
особей и измерена их длина. По результатам
х1,…,хn
методом моментов построить оценку![]() дляq
и приближенный доверительный интервал
с уровнем доверия РД
. Построить гистограмму наблюдений.
дляq
и приближенный доверительный интервал
с уровнем доверия РД
. Построить гистограмму наблюдений.
Варианты исходных данных
-
1
2
3
4
5
6
7
8
9
n
40
50
60
40
50
60
40
50
60
à1
5
6
5
6
5
6
5
6
5
à2
8
9
8
9
8
9
8
9
8
ÐÄ
0.95
0.95
0.98
0.95
0.95
0.98
0.95
0.95
0.98
q
0.5
0.4
0.3
0.5
0.4
0.3
0.5
0.4
0.3
Принять 1=1см, 2=1см. измерения получить моделированием с заданным значением q.
Решение (без вывода):
I = ( q1, q2 ),
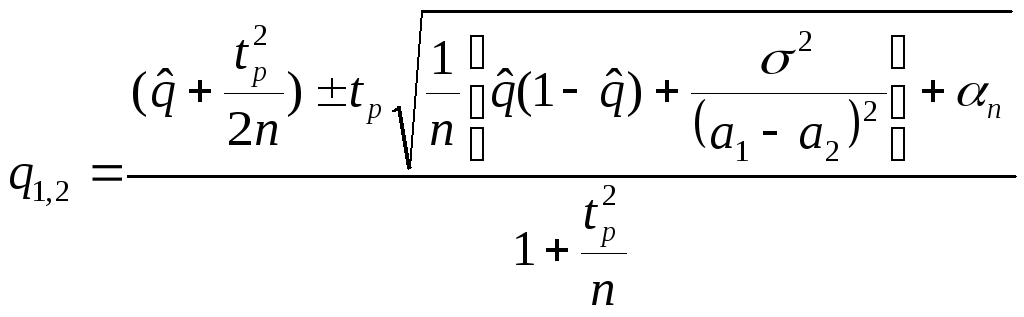 ,
n
,
n
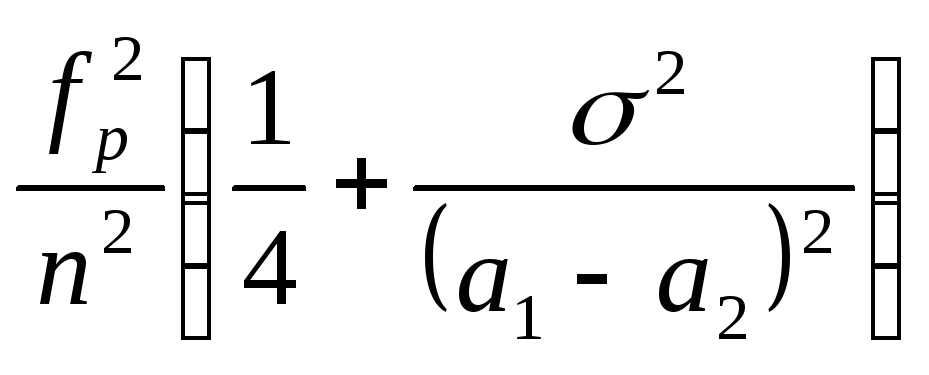 ,
,
tp- квантиль порядка (1+ РД)/2 для N(0,1).