

38513-LW_Integral_ppt
.pdfПоследовательная версия.
Алгоритмическая оптимизация
Предпоследняя оптимизация основана на математических особенностях вычисляемого интеграла, а именно на том факте, что функции sin и cos периодические.
–Предположим, что количество точек в сетке интегрирования кратно размеру подобранного буфера.
–В этом случае легко видеть, что итерации цикла по блокам будут вычислять одно и то же значение.
Можно также заметить, что:
b1 b2 |
|
1 |
|
|
|
|
|
1 |
|
|
|
|
||
b a |
b a |
|
||
a1 a 2 |
1 1 |
2 2 |
|
|
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
61 |
|
|

Последовательная версия.
Алгоритмическая оптимизация
Реализуйте алгоритмическое улучшение в проекте 05_AlgOptV2, с использованием техник, рассмотренных в предыдущих разделах.
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
62 |
|
|

Последовательная версия.
Алгоритмическая оптимизация
//количество точек в периоде интегрирования npi = (int)(2.0 / h);
//правильность размера блока assert((n1 % npi) == 0); assert((n2 % npi) == 0);
// вычисление значений sin(x * pi) for(i = 0; i < npi; i++)
{
x = a1 + i*h + h / 2; sinx[i] = sin(x * PI);
}
// вычисление значений cos(y * pi) for(j = 0; j < npi; j++)
{
y = a2 + j*h + h / 2; cosy[j] = cos(y * PI);
}
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
63 |
|
|

Последовательная версия.
Алгоритмическая оптимизация
//вычисление интеграла sum = 0.0;
for(i = 0; i < npi; i++)
{
for(j = 0; j < npi; j++)
{
//вычисление интеграла
sum += (exp(sinx[i] * cosy[j]) /
((b1 - a1) * (b2 - a2))) * h * h;
}
}
*res = sum * (n1 / npi) * (n2 / npi) + 1;
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
64 |
|
|
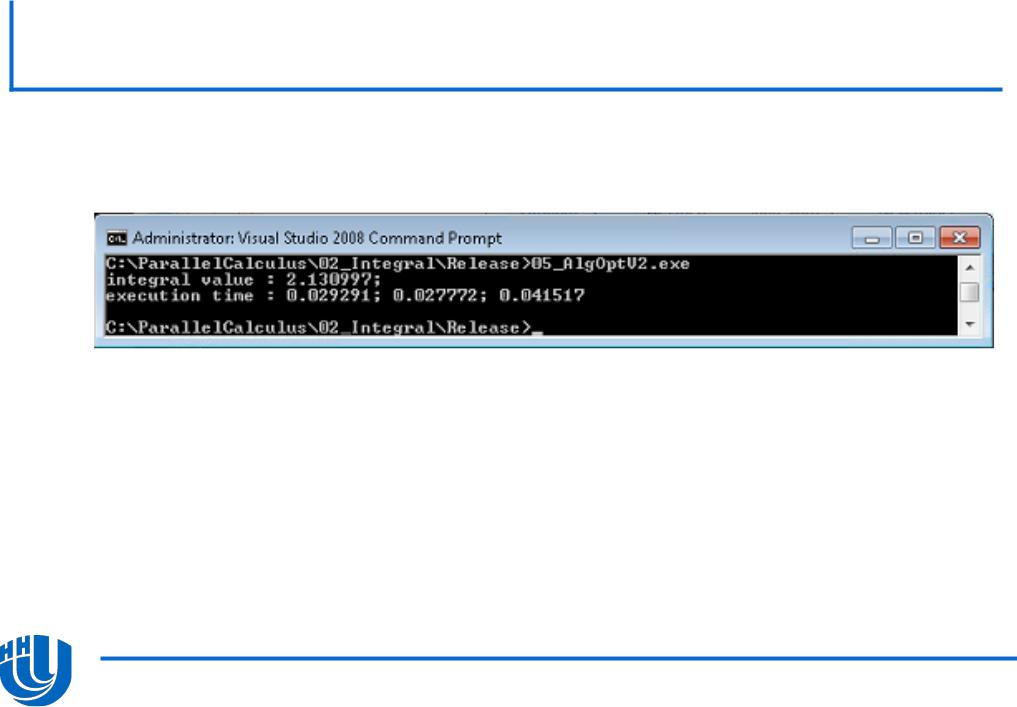
Последовательная версия.
Алгоритмическая оптимизация
Пересоберите получившийся код (команда Build→Rebuild Solution) и запустите его на выполнение.
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
65 |
|
|
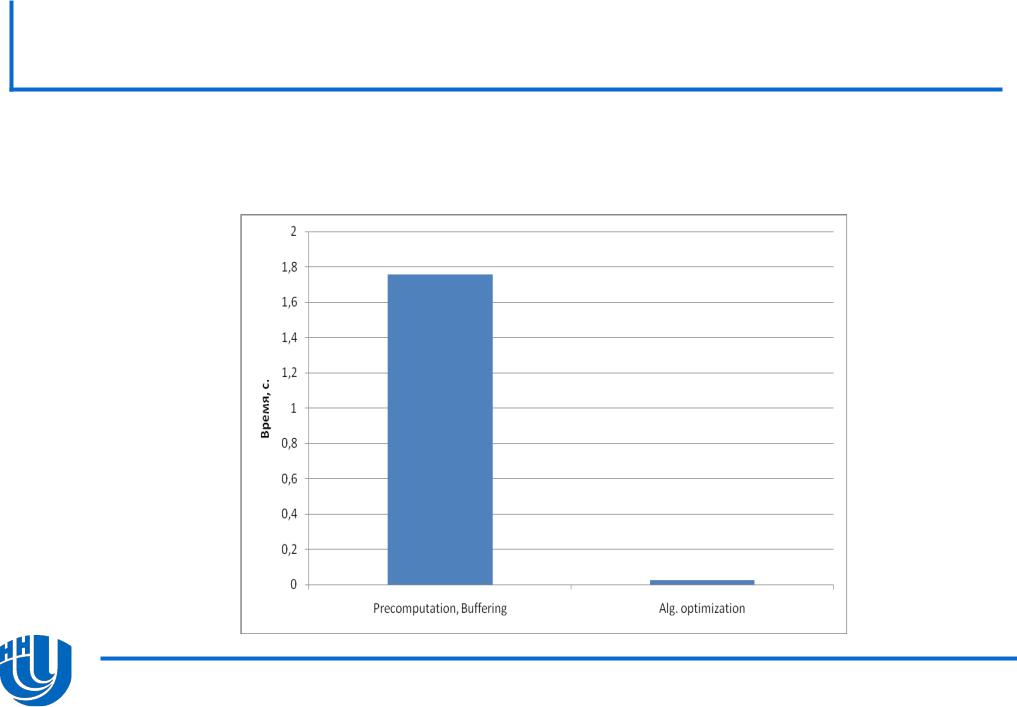
Последовательная версия.
Алгоритмическая оптимизация
Сравнение времени численного интегрирования последовательных реализаций
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
66 |
|
|

Параллельная версия. Распараллеливание
оптимизированного алгоритма
Реализуйте параллельную версию алгоритмически улучшенной реализации в проекте 06_AlgOptV2par.
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
67 |
|
|

Параллельная версия. Распараллеливание
оптимизированного алгоритма
В начале, объявите необходимые переменные.
void integral(const double a1, const double b1, const double a2, const double b2, const double h, double *res)
{
int i, j, n1, n2, npi;
double sum;// локальная переменная для подсчета интеграла
double x; // координата точки сетки по оси x double y; // координата точки сетки по оси y double *sinx; // значение sin(x * pi)
double *cosy; // значение cos(y * pi)
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
68 |
|
|

Параллельная версия. Распараллеливание
оптимизированного алгоритма
Подсчитайте размеры сетки интегрирования и выделите необходимую память.
//количество точек сетки интегрирования
//n1 - по координате x
//n2 - по координате y
n1 = (int)((b1 - a1) / h);
n2 = (int)((b2 - a2) / h);
//количество точек в периоде интегрирования npi = (int)(2.0 / h);
//правильность размера блока assert((n1 % npi) == 0); assert((n2 % npi) == 0);
sinx = new double [npi]; cosy = new double [npi];
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
69 |
|
|

Параллельная версия. Распараллеливание
оптимизированного алгоритма
Параллельно вычислите необходимые значения функций sin и cos.
//вычисление значений sin(x * pi)
#pragma omp parallel for private(x) for(i = 0; i < npi; i++)
{
x = a1 + i*h + h / 2; sinx[i] = sin(x * PI);
}
// вычисление значений cos(y * pi) #pragma omp parallel for private(y)
for(j = 0; j < npi; j++)
{
y = a2 + j*h + h / 2; cosy[j] = cos(y * PI);
}
Н. Новгород, 2010 г. |
Вычисление определенного интеграла |
70 |
|
|