


Chapter 7
Decomposition in This Book
You will see decomposition in many of the examples in this book. In many cases, we have referred to methods for which we don’t show the implementations because they are not relevant to the example and would take up too much space.
Naming
Your computer doesn’t care what you name your variables and functions as long as the name doesn’t result in a conflict with another variable or function. Names exist only to help you and your fellow programmers work with the individual elements of your program. Given this purpose, it is surprising how often programmers use unspecific or inappropriate names in their programs.
Choosing a Good Name
The best name for a variable, method, function, or class accurately describes the purpose of the item. Names can also imply additional information, such as the type or specific usage. Of course, the real test is whether other programmers understand what you are trying to convey with a particular name.
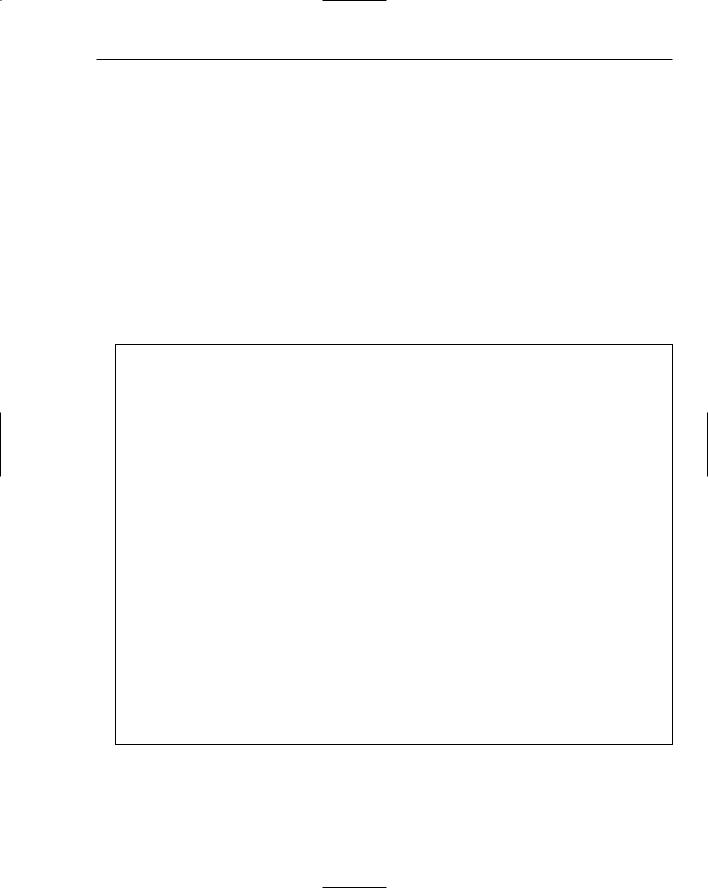
There are no set-in-stone rules for naming other than the rules that work for your organization. However, there are some names that are rarely appropriate. The table below shows some names at the two extreme ends of the naming continuum.
Good Names |
Bad Names |
|
|
srcName, dstName |
thing1, thing2 |
Distinguishes two objects |
Too general |
gSettings |
globalUserSpecificSettingsAndPreferences |
Conveys global status |
Too long |
mNameCounter |
mNC |
Conveys data member status |
Too obscure, concise |
performCalculations() |
doAction() |
Simple, accurate |
Too general, imprecise |
mTypeString |
_typeSTR256 |
Easy on the eyes |
A name only a computer could love |
mWelshRarebit |
mIHateLarry |
Good use of inside joke |
Inappropriate inside joke |
|
|
Naming Conventions
Selecting a name doesn’t always require a lot of thought and creativity. In many cases, you’ll want to use standard techniques for naming. Following are some of the types of data for which you can make use of standard names.
148
Coding with Style
Counters
Early in your programming career, you probably saw code that used the variable “i” as a counter. It is customary to use i and j as counters and inner-loop counters, respectively. Be careful with nested loops, however. It’s a common mistake to refer to the “ith” element when you really mean the “jth” element. Some programmers prefer using counters like outerLoopIndex and innerLoopIndex instead.
Getters and Setters
If your class contains a data member, such as mStatus, it is customary to provide access to the member via a getter called getStatus() and a setter called setStatus(). The C++ language has no prescribed naming for these methods, but your organization will probably want to adopt this or a similar naming scheme.
Prefixes
Many programmers begin their variable names with a letter that provides some information about the variable’s type or usage. The table below shows some common prefixes.
Prefix |
Example Name |
Literal Prefix Meaning |
Usage |
m |
mData |
“member” |
Data member within a class. Some |
_ |
_data |
|
programmers use _ as a prefix to |
|
|
|
indicate a data member. Others con- |
|
|
|
sider m to be more readable. |
s |
sLookupTable |
“static” |
Static variable or data member. Used |
|
|
|
for variables that exist on a per-class |
|
|
|
basis. |
kkMaximumLength “konstant” (German for
“constant” or a horrible misspelling? You decide.)
f |
fCompleted |
“flag” |
Indicates a constant value. Some programmers use all uppercase names to indicate constants as well.
Designates a Boolean value. Used especially to indicate a yes/no property of a class that modifies the object’s behavior based on its value.
n |
nLines |
“number” |
A data member that is also a counter. |
mNum |
mNumLines |
|
Since an “n” looks similar to an “m,” |
|
|
|
some programmers instead use mNum |
|
|
|
as a prefix, as in mNumLines. |
tmp |
tmpName |
“temporary” |
Indicates that a variable is only used to |
|
|
|
hold a value temporarily. Implies that |
|
|
|
subsequent code should not rely on its |
|
|
|
value. |
149

Chapter 7
Capitalization
There are many different ways of capitalizing names in your code. As with most elements of coding style, the most important thing is that your group standardizes on an approach and that all members adopt that approach. One way to get messy code is to have some programmers naming classes in all lowercase with underscores representing spaces (priority_queue) and others using capitals with each subsequent word capitalized (PriorityQueue). Variables and data members almost always start with a lowercase letter and either use underscores (my_queue) or capitals (myQueue) to indicate word breaks. Functions and methods are traditionally capitalized in C++, but, as you’ve seen, in this book we have adopted the style of lowercase functions and methods to distinguish them from class names. We adopt a similar style of capitalizing letters to indicate word boundaries for class and data member names.
Smart Constants
Imagine that you are writing a program with a graphical user interface. The program has several menus, including File, Edit, and Help. To represent the ID of each menu, you may decide to use a constant. A perfectly reasonable name for a constant referring to the Help menu ID is kHelp.
The name kHelp will work fine until one day you add a Help button to the main window. You also need a constant to refer to the ID of the button, but kHelp is already taken.
There are a few ways to resolve this problem. One way is to put the two constants in different namespaces, which were discussed in Chapter 1. However, namespaces may seem like too large a hammer for the small problem of a single name conflict between constants. You could easily resolve the name conflict by renaming the constants to kHelpMenu and kHelpButton. However, a smarter way of naming the constants may be to reverse that into kMenuHelp and kButtonHelp.
The reversed names initially seem not to roll off the tongue very well. However, they provide several benefits. First, an alphabetized list of all of your constants will show all of the menu constants together. If your development environment has an autocomplete or a pop-up menu that shows up as you type your code, this can work to your advantage. Second, it provides a weak, but easy naming hierarchy. Instead of using namespaces, which can become cumbersome, the namespace is effectively part of the name. You can even extend the hierarchy when referring to individual menu items within the help menu, such as kMenuFileSave.
Hungarian Notation
Hungarian Notation is a variable and data member naming convention that is popular with Microsoft Windows programmers. The basic idea is that instead of using single-letter prefixes such m, you should use more verbose prefixes to indicate additional information. The following line of code displays the use of Hungarian Notation:
char* pszName; // psz means “pointer to a null-terminated string”
The term Hungarian Notion arose from the fact that its inventor, Charles Simonyi, is Hungarian. Some also say that it accurately reflects the fact that programs using Hungarian notation end up looking as if they were written in a foreign language. For this latter reason, some programmers tend to dislike Hungarian Notation. In this book, we use prefixes, but not Hungarian Notation. We feel that adequately named variables don’t need much additional context information besides the prefix. We think that a data member named mName says it all.
150