

Структура основной памяти на основе блочной схемы

Рисунок 16 Структура основной памяти на основе блочной схемы
Адресное пространство памяти разбито на группы последовательных адресов, и каждая такая группа обеспечивается отдельным банком памяти. Для обращения к основной памяти используется 9-разрядный адрес, 7 младших разрядов которого A6-A0 поступают параллельно на ячейку 2 старшего разряда. Разряды А8-А7 содержат № банка. Выбор банка обеспечивается либо с помощью динамического номера банка, либо путем мультиплексирования информации.
Ёмкость такого ЗУ равна сумме ёмкостей составляющих, а быстродействие равно быстродействию его отдельного банка.
Циклическая организация
Большей скоростью доступа к основной памяти можно достичь за счет одновременного доступа к многим банкам памяти. Одна из использующихся для этого методик называется расслоением памяти. В её основе лежит чередование адресов, обеспечивающееся за счет циклического разбиения адреса.

Рисунок 17 Циклическая схема расслоения памяти
В данном случае для выбора банка используется А1-А0, для выбора ячейки А8-А2. Поскольку в каждом таком такте на ША может присутствовать только адрес одной ячейки, параллельное обращение к нескольким банкам невозможно, однако оно может быть организовано со сдвигом на 1 такт. Адрес ячейки запоминается в индивидуальном регистре адреса, а дальнейшие операции по доступу к ячейке в каждом банке протекают независимо.
Блочно-циклическая схема расслоения памяти
Каждый банк состоит из нескольких модулей, адресуемых по круговой схеме. Адреса между банком распространены по блочной схеме. Адресные ячейки разбиваются на 3 части: старшие биты определяющие номер банка, следующая группа разрядов указывает на ячейку модуля, а младшие биты выбирают модуль в банке.
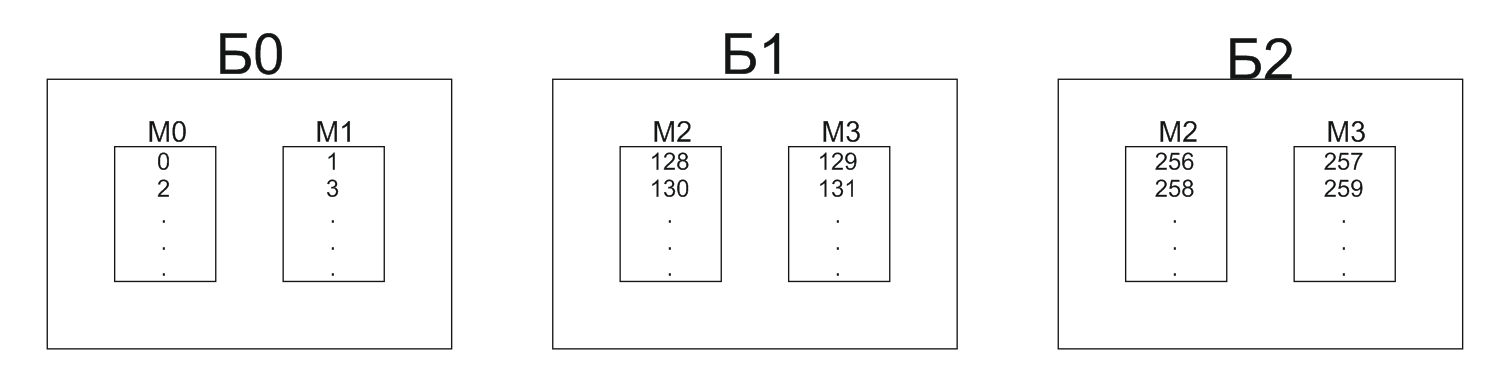
Рисунок 18 Блочно-циклическая схема расслоения памяти
Архитектура с сокращенным набором команд
Основные черты RISC-архитектуры:
Выполнение всех команд за 1 цикл;
Стандартная однословная длина команд, равная естественной длине слова и ширине ШД, допускающая унифицированную поточную обработку;
Малое число команд;
Малое количество форматов команд;
Доступ к памяти только посредством команд чтения и записи;
Все команды, за исключением чтения и записи, используют внутри процессорные межрегистровые пересылки;
Устройство управления с жесткой логикой;
Большой процессорный файл регистров общего назначения;
КлассSimd
Векторные и векторно-конвейерные вычислительные системы
Понятие вектора и размещение данных в памяти
В средствах векторной обработки под вектором понимается 1-мерный массив однотипных данных, регулярным образом размещенным в памяти ВС.
Если обработке подвергаются многомерные массивы, их так же рассматривают как векторы. При размещении матрицы в памяти все её элементы заносятся в ячейки с последовательными адресами, причем возможно размещение как по строкам, так и по столбцам.
Понятие векторного процесса
Векторные процессор – процессор, в котором операндами некоторой команды могут выступать упорядоченные массивы данных, т.е. векторы.
Векторные процессоры могут быть реализованы в двух вариантах:
Как дополнительных блок к универсальной ВС;
Как основа самостоятельной ВС;
Обобщенная структура векторного процессора

Рисунок 19 Обобщенная структура векторного процессора
Обработка всех n компонентов векторов-операндов задается одной векторной командой. Элементы векторов представляются числами в форме с плавающей запятой. АЛУ векторного процессора может быть реализовано в виде единого конвейерного устройства, способного выполнять все предусмотренные операции над числами с плавающей запятой, однако чаще всего АЛУ состоит из отдельных блоков сложения и умножения, каждый из которых конвейеризирован. Кроме того, в состав векторной ВС включается и скалярный процессор, что позволяет выполнять векторные и скалярные команды. Для хранения операций используется векторные регистры, представляющие собой совокупность скалярных регистров, объединенных в очередь FIFO.
Система команд векторного процессора поддерживает работы с векторными регистрами и включает следующие команды:
Загрузка векторного регистра содержимым последовательных ячеек памяти;
Выполнение операций над всеми элементами векторов;
Сохранение содержимого векторного регистра в последовательности ячеек памяти;
Регистр длины вектора (РДВ) – определяет, сколько элементов содержит обрабатываемый в данный момент вектор, т.е. сколько индивидуальных операций с элементами нужно сделать.
Регистр максимальной длины вектора (РМД) – определяет максимальное число элементов вектора, которое может быть одновременно обработано аппаратурой процессора.
Регистр маски вектора – каждому элементу вектора соответствует 1 бит. Установка бита в 1 разрешает запись соответствующего элемента вектора результата в выходной регистр.
Для обработки только ненулевых элементов вектора в системе команд вектора процессора предусмотрены опции упаковки и распаковки. Операция упаковки формирует вектор, содержащий только ненулевые элементы исходного вектора, операция распаковки – обратное представление. Данные задачи процессора выполняются с помощью регистра векторов индекса (РВИ), нулевое значение бита которого свидетельствует, что соответствующий элемент исходного вектора равен нулю.