

АРХИТЕКТУРА ВМС
Иерархическая структура памяти ЭВМ. Назначение и организация кэш памяти. Понятие ассоциативности кэша. Многоуровневая организация кэш.
Назначение КЭШ памяти
Как известно, процессор работает с данными, хранящимися в оперативной памяти. Однако скорость работы оперативной памяти и процессора существенно различаются: если бы процессор напрямую общался с оперативной памятью (читал или записывал данные), то большую часть времени попросту простаивал бы. Именно для сокращения задержек доступа к оперативной памяти и применяется кэшпамять, которая значительно более скоростная в сравнении с оперативной. Фактически если оперативная память используется для того, чтобы сгладить задержки доступа к данным на накопителе (HDD-диске, SSD-накопителе или флэшпамяти), то кэшпамять процессора применяется для нивелирования задержек доступа к самой оперативной памяти. В этом смысле оперативную память можно рассматривать как кэш накопителя. Однако между оперативной памятью и кэшем процессора есть одно очень серьезное различие: кэш процессора полностью прозрачен для программиста, то есть нельзя адресовать программным образом находящиеся в нем данные.
Есть и другая причина, по которой необходимо использовать кэшпамять как промежуточное звено между процессором и оперативной памятью. Дело в том, что процесс чтения и записи данных в оперативную память происходит не отдельными байтами, а пакетами, состоящими как минимум из четырех 64-разрядных ячеек (из четырех четверных слов). Это позволяет повысить эффективность работы памяти. Однако процессор загружает данные в свои регистры в виде байт, слов, двойных слов или даже четверных слов. В любом случае он не работает с пакетами данных. То есть минимальная единица информации, считываемая из оперативной памяти, всегда больше той минимальной единицы информации, с которой работает процессор.
Аналогично при записи модифицированных процессором данных в оперативную память логично было бы первоначально накапливать их во временном хранилище (кэше), а затем, дождавшись освобождения системой шины, выгружать в оперативную память одним махом. Это ликвидировало бы никому не нужные задержки и значительно увеличило бы производительность подсистемы памяти. Попутно отметим, что такой механизм отложенной записи реализован во всех современных процессорах.
Понятно, что для того, чтобы кэш процессора мог выполнять свою основную задачу, то есть сглаживать доступ к оперативной памяти, он должен работать гораздо быстрее, чем она. Так, если оперативная память представляет собой динамическую память с произвольным доступом (Dynamic Random Access Memory, DRAM), то кэш процессора выполняется на базе статической оперативной памяти (Static Random Access Memory, SRAM).
Принцип работы кэша процессора
Кэш состоит из контроллера и собственно кэшпамяти. Кэшконтроллер управляет работой кэшпамяти, то есть загружает в нее нужные данные из оперативной памяти и возвращает, когда нужно, модифицированные процессором данные в оперативную память. Архитектурно кэшконтроллер расположен между процессором и оперативной памятью (рис. 1). Перехватывая запросы к оперативной памяти, кэшконтроллер определяет, имеется ли копия затребованных данных в кэше. Если такая копия там есть, то это называется кэшпопаданием (cache hit) — в таком случае данные очень быстро извлекаются из кэша (существенно быстрее, чем из оперативной памяти). Если же требуемых данных в кэше нет, то говорят о кэшпромахе (cache miss) — тогда запрос данных переадресуется к оперативной памяти.
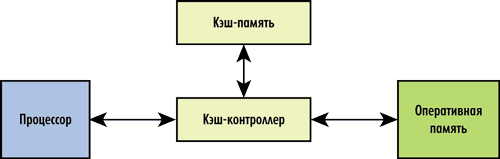
Рис. 1. Структура кэш-памяти процессора
Для достижения наивысшей производительности кэшпромахи должны происходить как можно реже (в идеале — отсутствовать). Учитывая, что по емкости кэшпамять намного меньше оперативной памяти, добиться этого не такто просто. А потому основная задача кэшконтроллера заключается в том, чтобы загружать кэшпамять действительно нужными данными и своевременно удалять из нее данные, которые больше не понадобятся.
Загрузка кэша данными реализуется на основе так называемой стратегии кэширования, а выгрузка данных — на основе политики замещения.
Политики замещения данных в кэшпамяти
Самый простой алгоритм, не наделенный интеллектом, — это алгоритм произвольного выбора, когда замещаемые данные выбираются случайным образом (Random). Понятно, что политика замещения на основе алгоритма произвольного выбора проста в реализации, однако неэффективна, а потому не используется в современных процессорах.
Решение о замещении данных в кэше может приниматься также на основе частотного анализа обращений к данным (Least Frequently Used, LFU), когда в первую очередь замещаются те данные, у которых самая низкая частота обращений. Политика замещения на основе частотного анализа обращений требует наличия счетчиков обращений в каждой строке кэша, обновляемых при каждом удачном запросе.
Следующий возможный алгоритм, определяющий политику замещения, — это алгоритм LRU (Least Recently Used), когда замещаются те данные, к которым дольше всего не обращались.
Возможен также алгоритм FIFO (First Input First Output) или LRR (Least Recently Replaced), когда замещаются те данные, которые были загружены раньше всех.
Отметим, что алгоритмы LRU и FIFO тоже требуют наличия счетчиков в каждой строке кэша и именно эти два алгоритма применяются во всех современных процессорах.
Стратегии кэширования
Основная задача кэшконтроллера заключается в том, чтобы наполнить кэш актуальными данными и свести к минимуму количество кэшпромахов.
Фактически для этого кэшконтроллер должен знать или уметь предсказывать, какие данные потребуются процессору в будущем, и на основе этого заранее загружать их в кэш (упреждающая загрузка данных).
Существует несколько стратегий помещения данных в кэшпамять. Самая простая и неинтеллектуальная стратегия заключается в том, что обращение к оперативной памяти происходит только в том случае, если затребованных процессором данных нет в кэше (возникает кэшпромах). Данная стратегия называется кэшированием по требованию (on demand). Однако при такой стратегии кэширования частота кэшпромахов достаточно высока — по этой причине она не используется.
Значительно более эффективна стратегия упреждающей спекулятивной загрузки данных в кэш, когда кэшконтроллер заранее загружает данные в кэшпамять на основе прогнозируемых предположений о том, какие данные понадобятся процессору в ближайшем будущем.
Самый простой алгоритм основан на предположении, что данные из оперативной памяти обрабатываются последовательно. То есть кэшконтроллер попросту загружает в кэш из оперативной памяти не только затребованные процессором данные, но и следующие в порядке возрастания адресов. Если данные обрабатываются последовательно, то последующие запросы процессора приведут к попаданию в кэшпамять.
Описанный алгоритм упреждающей загрузки является самым простым, но не самым эффективным, поскольку далеко не всегда данные в программе обрабатываются последовательно. Более интеллектуальные алгоритмы упреждающей спекулятивной загрузки данных в кэш предсказывают адрес следующей запрашиваемой ячейки памяти на основе анализа предыдущих обращений.
Организация кэша
Рассмотрим, как структурно устроен кэш. Как мы уже знаем, размер кэша всегда намного меньше размера оперативной памяти, поэтому необходимо, чтобы вместе с каждым блоком информации, сохраняемым в кэше, сохранялся адрес этого блока данных в оперативной памяти.
Рассмотрим гипотетический пример. Пусть имеется система с 32-разрядной адресацией памяти, то есть для задания адреса каждого байта памяти требуется четырехбайтный адрес. Предположим, что наш гипотетический кэш работает на уровне отдельных байтов, то есть может сохранять в качестве элемента байт оперативной памяти. Тогда каждый структурный элемент кэшпамяти должен сохранять не только байт данных оперативной памяти, но еще и его четырехбайтный адрес в оперативной памяти. Получается уже некое подобие строки, которая называется кэшстрокой (cache-line).
Адрес сохраняемого байта принято именовать тегом (tag).
При чтении данных из кэша процессор формирует адрес, который сравнивается с тегом кэшстроки. В случае совпадения кэш выдает требуемый байт данных, если же совпадения адреса с тегом нет (кэшпромах) — производится обращение к оперативной памяти.
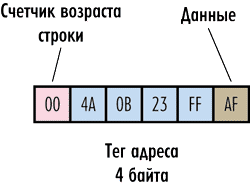
Рис. 2. Структура гипотетического кэша
Также, для реализации политики замещения на основе алгоритма FIFO или LRU, необходимо каждую строку кэша дополнить счетчикам возраста.
В описанном выше гипотетическом кэше объем полезной сохраняемой информации в шесть раз меньше полного объема кэша, поскольку на каждый байт хранимых данных приходится еще шесть служебных байт. Для того чтобы повысить объем полезной информации и одновременно уменьшить объем служебных данных, достаточно сохранять информацию в кэше не в виде отдельных байтов, а в виде блоков данных. Тегом строки будет адрес в оперативной памяти первого содержащегося в ней байта. Отметим, что блок сохраняемых данных в кэшстроке (то есть по сути сама кэшстрока) имеет строго фиксированный размер и является минимальной единицей информации, которая может быть считана из кэша или загружена в кэш. Как мы помним, чтение из оперативной памяти (равно как и запись в нее) происходит пакетом данных, а кэш работает только с кэшстроками. Поэтому адрес первого байта кэшстроки всегда кратен размеру пакета данных.
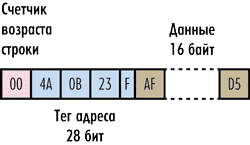
Рис. 3. Пример кэш-строки размером 16 байт
Теперь посмотрим, насколько эффективнее сохранять в кэшстроке не один байт, а фиксированный блок данных. Предположим, что размер кэшстроки составляет 32 байта. Возникает вопрос, какова должна быть при этом разрядность поля адреса тега? Если, как и ранее, рассматривается 32-разрядная адресация оперативной памяти, а тег, как мы отмечали, должен сохранять адрес первого байта кэшстроки, то, казалось бы, нужно четырехбайтовое поле адреса. Однако следует учесть, что данные в кэшстроках не могут перекрываться, а значит, теги всех строк должны быть кратны 32. Именно поэтому необходимая для адресации разрядность тега будет ниже. Предположим, к примеру, что в кэше сохраняется последовательная цепочка данных и адрес первого байта в оперативной памяти равен 0000 (в шестнадцатеричной системе). Тогда тег первой строки будет равен 0000, тег второй строки (адрес 32-го байта) — 0020, тег третьей строки — 0040 и т.д. То есть теги будут образовывать последовательность 0000, 0020, 0040, 0060, 0080, 00A0 и т.д. Если записать эту последовательность в двоичном виде, то можно заметить, что последние пять цифр в каждом теге всегда будут равны нулю. Эти пять нулей можно смело откинуть — тогда поле тега будет уже не 32-, а 27-битным.
Для получения отдельного байта процессор формирует 32-битный адрес, который делится на старшие 27 бит и младшие 5 бит. Старшие 27 бит используются для поиска нужной кэшстроки, а младшие 5 бит (смещение адреса) определяют конкретное положение нужного байта в строке.
Понятие ассоциативности кэша
Один из главных вопросов в организации кэша заключается в следующем: как связать строки оперативной памяти со строками кэшпамяти? То есть если, к примеру, требуется загрузить в кэш первую строку оперативной памяти, то в какую именно строку кэшпамяти она будет загружаться? Возможны 3 различных варианта.
Полностью ассоциативная кэшпамять
Первый и самый простой вариант заключается в том, что любая строка оперативной памяти может быть записана в любую строку кэшпамяти. То есть каждая строка кэшпамяти может быть связана с любой строкой оперативной памяти и наоборот (рис. 4). Такая кэшпамять получила название полностью ассоциативной (fully associative).
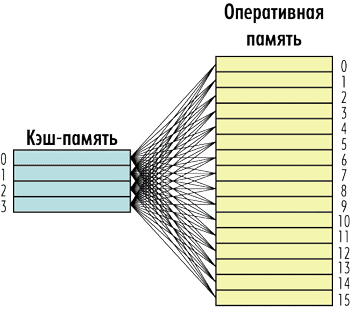
Рис. 4. Структура полностью ассоциативной кэш-памяти
Главный минус такой организации заключается в том, что для того чтобы определить, имеются ли запрошенные процессором данные в кэшпамяти, нужно перебрать все кэшстроки, то есть сравнить тег кэшстроки со старшими битами адреса. Наиболее простой способ — это последовательный перебор всех тегов. Однако при большом их количестве этот способ крайне непроизводителен.
Кэшпамять с прямым отображением
Другой вариант организации отображения оперативной памяти на кэшпамять противоположен рассмотренному полностью ассоциативному кэшу. Это так называемый кэш прямого отображения (Direct mapping), когда каждая строка оперативной памяти соответствует не любой, а только одной, строго определенной строке кэшпамяти. В этом случае каждая строка оперативной памяти связана только с одной строкой кэшпамяти, а каждой строке кэшпамяти соответствует несколько строк оперативной памяти, но опять-таки не любых, а строго определенных.
В рассмотренном примере кэша из восьми строк и оперативной памяти из 24 строк можно установить следующую жесткую связь между кэшстроками и строками памяти. Строке кэшпамяти с номером 0 соответствуют строки оперативной памяти с номерами 0, 8 и 16; строке с номером 1 — строки с номерами 1, 9 и 17, а последней строке с номером 7 — строки с номерами 7, 15 и 23 (рис. 5). То есть в нашем примере каждой строке кэшпамяти будут соответствовать три строки оперативной памяти.
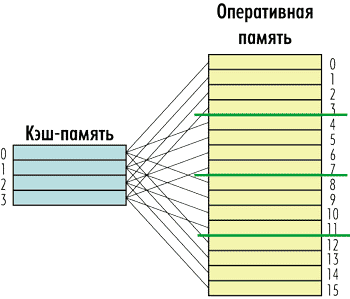
Рис. 5. Структура кэш-памяти с прямым отображением
Плюс кэшпамяти с прямым отображением заключается в том, что поиск элементов в такой памяти происходит очень быстро, поскольку для этого нужно просмотреть тег только одной кэшстроки.
Однако у такой кэшпамяти есть и очень существенный недостаток. Представьте ситуацию, когда процессор пытается последовательно обратиться к строкам оперативной памяти с условными номерами 0, 8 и 16 (в рассмотренном ранее примере). Все эти строки оперативной памяти жестко связаны с одной и той же строкой кэшпамяти с номером 0. При каждом таком обращении будет происходить помещение содержимого строк оперативной памяти в одну и ту же строку кэша. Причем помещение данных в кэш будет производиться путем их замещения, то есть процессор будет сначала размещать данные в кэшстроку, а потом эти же данные будут записываться обратно в оперативную память, а на их место в кэшпамяти будут записываться новые данные.
Наборно-ассоциативный кэш
Промежуточным вариантом между полностью ассоциативным кэшем и кэшем с прямым отображением является наборноассоциативный кэш (N-way cache — N-канальный кэш).
Такой кэш состоит из нескольких независимых банков (сегментов), каждый из которых представляет собой кэш с прямым отображением, а сами банки являются полностью ассоциативными по отношению к оперативной памяти. То есть любой элемент оперативной памяти может быть размещен в любом банке кэшпамяти, однако внутри банка ему соответствует строго определенная кэшстрока (рис. 6).
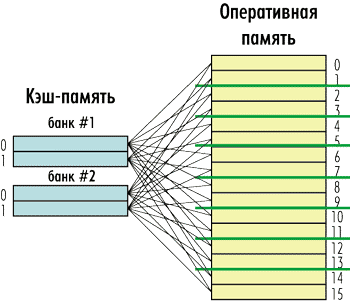
Рис. 6. Структура наборно-ассоциативного кэша
Количество банков кэша называется его степенью ассоциативности или канальностью (way). То есть может быть 2-канальный (2-way), 4-канальный (4-way), 8-канальный (8-way) и т.д. кэш. Причем количество каналов кэша — это степень числа 2. Наибольшее распространение получили 4- и 8-канальные кэши. На рис. 6 в качестве примера показан 4-канальный кэш.
Многоуровневая организация кэша
Все современные процессоры имеют как минимум двухуровневую структуру кэшпамяти, а большинство процессоров Intel — трехуровневую кэшпамять. При этом различают кэш первого уровня (обозначается L1), кэш второго уровня (L2) и кэш третьего уровня (L3). Причем в случае процессоров Intel кэши всех уровней размещены на кристалле процессора.
Понятно, что в случае, когда в процессоре имеется многоуровневая система кэшпамяти, необходимо организовать взаимодействие между кэшами разных уровней.
Для начала рассмотрим двухуровневую систему кэша. Такая кэшпамять строится на базе одной из двух архитектур: включающей, которую также называют инклюзивной (inclusive), и исключающей, именуемой эксклюзивной (exclusive). То есть кэш L2 всегда построен либо по включающей, либо по исключающей архитектуре по отношению к кэшу L1 (отметим, что при наличии кэша L3 кэши L2 и L1 могут быть и не включающими, и не исключающими по отношению друг к другу).
Кэш L2, построенный по включающей архитектуре, всегда дублирует содержимое кэша L1, а потому эффективная емкость кэшпамяти равна емкости кэша L2.
Кэш L2, построенный по исключающей архитектуре, никогда не дублирует содержимое кэша L1, а потому эффективная емкость кэшпамяти равна суммарной емкости кэшей L1 и L2.
Пусть кэш имеет включающую архитектуру. Рассмотрим, каким образом происходит запись данных из оперативной памяти в такой кэш. Если в такой системе кэшпамяти при полностью заполненном кэше L2 процессор пытается загрузить еще одну кэшстроку, то произойдет следующее. Обнаружив, что все кэшстроки заняты, кэш L2 избавляется от наименее ценной из них, стремясь при этом найти линейку, которая еще не была модифицирована, поскольку в противном случае ее еще придется выгружать в оперативную память.
Затем кэш L2 передает полученные из памяти данные кэшу L1. Если кэш первого уровня также заполнен, ему приходится избавляться от одной из кэшстрок по сценарию, описанному выше.
Таким образом, загруженная порция данных присутствует и в кэше L1, и в кэше L2.
Отметим, что процессоры Intel Pentium II и Pentium III имели двухуровневый кэш, построенный по включающей архитектуре.
В случае кэша, построенного по исключающей архитектуре, кэш L1 никогда не уничтожает кэшстроки при нехватке места. Даже если кэшстроки не были модифицированы, они вытесняются в кэш L2 на то место, где находилась только что переданная кэшу L1 кэшстрока. То есть кэши L1 и L2 как бы обмениваются друг с другом своими кэшстроками, благодаря чему кэшпамять используется весьма эффективно.
Классификации архитектур вычислительных систем. Классификация Флинна, Фенга.
Классификация Флинна
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.
SISD (single instruction stream / single data stream) (рис. 1.1) - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка.
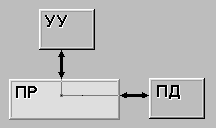
Рисунок 1.1 – Архитектура SISD
SIMD (single instruction stream / multiple data stream) (рис. 1.2) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1.
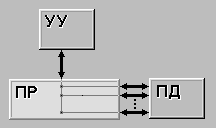
Рисунок 1.2 – Архитектура SIMD
MISD (multiple instruction stream / single data stream) (рис. 1.3) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей относят конвейерные машины к данному классу, однако это не нашло окончательного признания в научном сообществе.

Рисунок 1.3 – Архитектура MISD
MIMD (multiple instruction stream / multiple data stream) (рис. 1.4) - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
Рисунок 1.4 – Архитектура MIMD
Итак, что же собой представляет каждый класс? В SISD, как уже говорилось, входят однопроцессорные последовательные компьютеры типа VAX 11/780. Однако, многими критиками подмечено, что в этот класс можно включить и векторно-конвейерные машины, если рассматривать вектор как одно неделимое данное для соответствующей команды. В таком случае в этот класс попадут и такие системы, как CRAY-1, CYBER 205, машины семейства FACOM VP и многие другие.
Бесспорными представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое управляющее устройство контролирует множество процессорных элементов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинаковую команду и выполняет ее над своими локальными данными. Для классических процессорных матриц никаких вопросов не возникает, однако в этот же класс можно включить и векторно-конвейерные машины, например, CRAY-1. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных.
Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы: Cm*, C.mmp, CRAY Y-MP, Denelcor HEP, BBN Butterfly, Intel Paragon, CRAY T3D и многие другие. Интересно то, что если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) не над одиночным векторным потоком данных, а над множественным скалярным потоком, то все рассмотренные выше векторно-конвейерные компьютеры можно расположить и в данном классе.
Предложенная схема классификации вплоть до настоящего времени является самой применяемой при начальной характеристике того или иного компьютера. Если говорится, что компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным базовый принцип его работы, и в некоторых случаях этого бывает достаточно. Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания архитектуры, например dataflow и векторно-конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток - это чрезмерная заполненность класса MIMD. Необходимо средство, более избирательно систематизирующее архитектуры, которые по Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования.
Наличие пустого класса (MISD) не стоит считать недостатком схемы. Такие классы, по мнению некоторых исследователей в области классификации архитектур, могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.