

Теория информации / Cover T.M., Thomas J.A. Elements of Information Theory. 2006., 748p
.pdf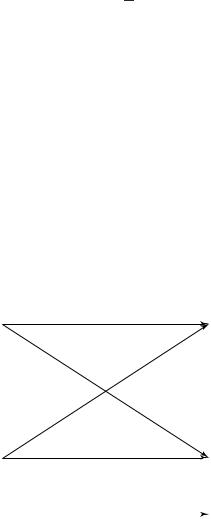
236 CHANNEL CAPACITY
Specifically, S = {y1, y2, . . . , ym, e}, and
Pr{S = y|X = x} = αp(y|x), y Y,
Pr{S = e|X = x} = α.
Determine the capacity of this channel.
7.28Choice of channels. Find the capacity C of the union of two channels (X1, p1(y1|x1), Y1) and (X2, p2(y2|x2), Y2), where at each time, one can send a symbol over channel 1 or channel 2 but not both. Assume that the output alphabets are distinct and do not intersect.
(a)Show that 2C = 2C1 + 2C2 . Thus, 2C is the effective alphabet size of a channel with capacity C.
(b)Compare with Problem 2.10 where 2H = 2H1 + 2H2 , and interpret part (a) in terms of the effective number of noise-free symbols.
(c)Use the above result to calculate the capacity of the following channel.
1 − p
0 |
|
0 |
|
|
|
p |
|
|
|
p |
|
1 |
|
1 |
|
1 |
− p |
||
2 |
|
|
2 |
|
1 |
||
|
|
|
|
7.29Binary multiplier channel
(a)Consider the discrete memoryless channel Y = XZ, where X and Z are independent binary random variables that take on values 0 and 1. Let P (Z = 1) = α. Find the capacity of this channel and the maximizing distribution on X.
(b)Now suppose that the receiver can observe Z as well as Y . What is the capacity?
PROBLEMS 237
7.30Noise alphabets. Consider the channel
Z
X  ∑
∑  Y
Y
X = {0, 1, 2, 3}, where Y = X + Z, and Z is uniformly distributed over three distinct integer values Z = {z1, z2, z3}.
(a)What is the maximum capacity over all choices of the Z alpha-
bet? Give distinct integer values z1, z2, z3 and a distribution on X achieving this.
(b)What is the minimum capacity over all choices for the Z alpha-
bet? Give distinct integer values z1, z2, z3 and a distribution on X achieving this.
7.31Source and channel. We wish to encode a Bernoulli(α) process
V1, V2, . . . for transmission over a binary symmetric channel with crossover probability p.
|
|
|
|
1 − p |
|
|
|
|
|
|
|
|
p |
|
|
^ |
|
V n |
|
X n (V n) |
|
p |
|
Y n |
|
V n |
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
1 − p |
|
|
|
|
Find conditions on and so that the probability of error ˆ n =
α p P (V V n) can be made to go to zero as n −→ ∞.
7.32Random 20 questions. Let X be uniformly distributed over {1, 2,
. . . , m}. Assume that m = 2n. We ask random questions: Is X S1? Is X S2? . . . until only one integer remains. All 2m subsets S of {1, 2, . . . , m} are equally likely.
(a)How many deterministic questions are needed to determine X?
(b)Without loss of generality, suppose that X = 1 is the random object. What is the probability that object 2 yields the same answers as object 1 for k questions?
(c)What is the expected number of objects in {2, 3, . . . , m} that have the same answers to the questions as those of the correct object 1?

238CHANNEL CAPACITY
(d)Suppose that we ask n + √n random questions. What is the expected number of wrong objects agreeing with the answers?
(e)Use Markov’s inequality Pr{X ≥ t µ} ≤ 1t , to show that the probability of error (one or more wrong object remaining) goes to zero as n −→ ∞.
7.33BSC with feedback. Suppose that feedback is used on a binary
symmetric channel with parameter p. Each time a Y is received,
it becomes the next transmission. Thus, X1 is Bern( 12 ), X2 = Y1,
X3 = Y2, . . ., Xn = Yn−1.
(a)Find limn→∞ n1 I (Xn; Y n).
(b)Show that for some values of p, this can be higher than capacity.
(c) Using this feedback transmission scheme, Xn(W, Y n) = (X1 (W ), Y1, Y2, . . . , Ym−1), what is the asymptotic communication rate achieved; that is, what is limn→∞ n1 I (W ; Y n)?
7.34Capacity. Find the capacity of
(a)Two parallel BSCs:
1 |
1 |
|
p |
|
p |
2 |
2 |
X |
Y |
3 |
3 |
|
p |
|
p |
4 |
4 |
(b) BSC and a single symbol:
1 |
1 |
|
|
p |
|
|
p |
|
2 |
2 |
|
X |
|
Y |
3 |
|
3 |
|
||
 1
1 2
2 3
3  4
4 5
5240 CHANNEL CAPACITY
Now consider the channel with memory. Before transmission begins, Z is randomly chosen and fixed for all time. Thus,
Yi = ZXi .
(b) What is the capacity if
Z = |
|
1, |
p |
= |
0.5 |
(7.169) |
− |
1, |
p |
0.5? |
|||
|
|
|
= |
|
|
7.37Joint typicality. Let (Xi , Yi , Zi ) be i.i.d. according to p(x, y, z). We will say that (xn, yn, zn) is jointly typical [written (xn, yn, zn)
A(n)] if
•p(xn) 2−n(H (X)± ).
•p(yn) 2−n(H (Y )± ).
•p(zn) 2−n(H (Z)± ).
•p(xn, yn) 2−n(H (X,Y )± ).
•p(xn, zn) 2−n(H (X,Z)± ).
•p(yn, zn) 2−n(H (Y,Z)± ).
•p(xn, yn, zn) 2−n(H (X,Y,Z)± ).
|
|
|
(Xn, Y n, Zn) |
is drawn according to |
p(xn)p(yn) |
||||||
Now suppose that |
˜ |
˜ |
˜ |
|
|
|
|||||
p(zn |
|
Xn, Y n, Zn |
have the same marginals as |
p(xn, yn, zn) |
|||||||
|
). Thus, ˜ |
˜ |
˜ |
|
|
|
A(n) |
||||
|
|
|
|
|
|
|
(Xn Y n Zn) |
|
|||
but are independent. Find (bounds on) Pr{ ˜ , ˜ , ˜ |
|
|
} in |
||||||||
terms of |
the |
entropies |
H (X),H (Y ),H (Z),H (X, Y ),H (X, Z), |
||||||||
H (Y, Z), and H (X, Y, Z).
HISTORICAL NOTES
The idea of mutual information and its relationship to channel capacity was developed by Shannon in his original paper [472]. In this paper, he stated the channel capacity theorem and outlined the proof using typical sequences in an argument similar to the one described here. The first rigorous proof was due to Feinstein [205], who used a painstaking “cookiecutting” argument to find the number of codewords that can be sent with a low probability of error. A simpler proof using a random coding exponent was developed by Gallager [224]. Our proof is based on Cover [121] and on Forney’s unpublished course notes [216].
The converse was proved by Fano [201], who used the inequality bearing his name. The strong converse was first proved by Wolfowitz [565], using techniques that are closely related to typical sequences. An iterative algorithm to calculate the channel capacity was developed independently by Arimoto [25] and Blahut [65].
HISTORICAL NOTES |
241 |
The idea of the zero-error capacity was developed by Shannon [474]; in the same paper, he also proved that feedback does not increase the capacity of a discrete memoryless channel. The problem of finding the zero-error capacity is essentially combinatorial; the first important result in this area is due to Lovasz [365]. The general problem of finding the zero error capacity is still open; see a survey of related results in Korner¨ and Orlitsky [327].
Quantum information theory, the quantum mechanical counterpart to the classical theory in this chapter, is emerging as a large research area in its own right and is well surveyed in an article by Bennett and Shor [49] and in the text by Nielsen and Chuang [395].

