

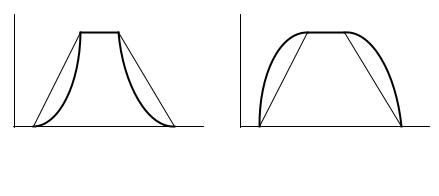
Основные понятия теории нечетких множеств |
18 |
При этом выделяют два частных |
случая данной операции |
(рис. 3.4) – концентрирование: |
|
CON A = A2 |
(3.14) |
и растяжение: |
|
DIL A = A0,5. |
(3.15) |
Рис. 3.4. Операции концентрирования и растяжения нечетких множеств
Операция концентрирования соответствует уменьшению нечеткости границ формализуемого понятия и обычно используется для представления лингвистического модификатора «очень». Наоборот, операция растяжения соответствует увеличению нечеткости границ формализуемого понятия и используется для представления модифи-
каторов «слегка», «более или менее» и т.п.
4. Понятие лингвистической переменной
Лингвистическая переменная представляет собой переменную,
значениями которой являются слова или сочетания слов естествен-
ного языка, формализуемые в виде нечетких множеств на общей области определения.
Формально, лингвистическая переменная определяется следующим набором:
< L, T, U, S, M >,
где:
L – имя переменной,
T – терм-множество, т.е. множество лингвистических значений переменной (термов);
U – универсальное множество (область определения);
S – синтаксическое правило порождения элементов терммножества;
Основные понятия теории нечетких множеств |
19 |
M – семантическое правило, которое ставит в соответствие каждому терму некоторое нечеткое множество на области определения U.
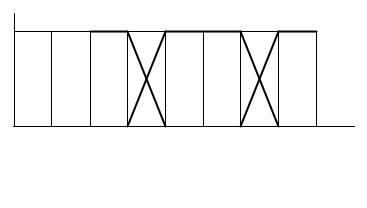
Рассмотрим следующий пример лингвистической переменной.
L = Длина;
T= {малая, средняя, большая};
U= [20, 80].
Синтаксическое правило S в данном случае сводится к перечислению элементов терм-множества, а семантическое правило ставит в соответствие термам «малая», «средняя» и «большая» нечеткие множества, как показано на рис. 4.1.
Рис. 4.1. Пример лингвистической переменной «Длина»
С лингвистической переменной всегда связана простая переменная, определенная на множестве U и область значений которой совпадает со всем U – эта переменная называется базовой.
Терм, состоящий из одного слова или набора слов, такого что никакой его поднабор терма не образует, называется атомарным, в противном случае – составным. Структура составных термов определяется синтаксическим правилом S (которое часто задается в виде некоторой грамматики). Обычно составные термы образуются из атомарных с использованием лингвистических модификаторов «не», «очень», «более или менее», и др. и логических связок «и», «или».
В нашем примере составными термами являются:
очень большая; более или менее малая;
не большая и не очень малая; малая или средняя и т.д.
Семантическое правило M обычно определяется следующим образом: семантика атомарных термов (соответствующие им нечеткие множества) задается явно, а семантика составных термов задается на основе входящих в их состав атомарных термов, с применением опе-
Основные понятия теории нечетких множеств |
20 |
раций над соответствующими нечетким множествами. Обычно используются следующие операции (табл. 4.1).
|
Таблица 4.1 |
|
модификатор или |
операция |
|
логическая связка |
||
|
||
очень |
концентрирование |
|
более или менее |
растяжение |
|
не |
дополнение |
|
и |
пересечение |
|
или |
объединение |
При этом операции пересечения и объединения определяются, как правило, на основе минимаксного подхода, поскольку только при таком определении выполняется свойство идемпотентности, которое для данного случая является существенным, поскольку термы вида «А и А», «А или А» должны совпадать по смыслу с «А».
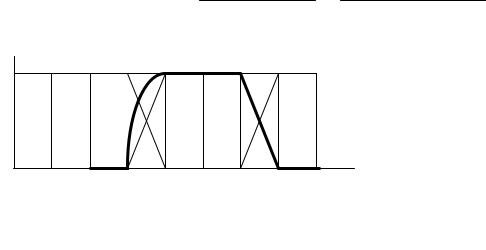
Например, для нашей лингвистической переменной «Длина» мы можем определить семантику порожденного терма «не большая и не очень малая» следующим образом (рис. 4.2):
M (не большая и не очень малая)= M (большая)∩CON M (малая).
Рис. 4.2. Нечеткое множество, соответствующее терму «не большая и не очень малая»
терму «не большая и не очень малая»
Лингвистическая переменная, все термы которой представляются нечеткими интервалами или нечеткими числами, называется
числовой.