

6. Создание и использование индексов и ключей в системе sql Server.
Индексом называется отдельная физическая структура БД, созданная на основе таблиц и предназначенная для ускорения выборки данных, поиск которых осуществляется по значению из проиндексированного столбца. Кроме того, в SQL Server индексы используются для обеспечения уникальности строк и столбцов таблицы, упорядочения информации и распределения данных таблицы в отдельном файле или группе файлов с целью повышения скорости доступа.
В SQL Server данные и индексы таблиц хранятся в виде страниц следующего формата:
8192
байт -
96 байт -
36 байт -8060
байт {
{
В SQL Server дисковая память для таблиц и индексов разделяется блоками по 8 страниц, которые называются экстентами. После заполнения одного экстента объекту выделяется следующий (еще 8 страниц).
Для представления индексов в SQL Server используется схема двоичного дерева:
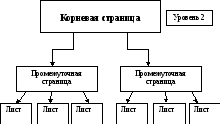
Уровень 1
Уровень
0
Каждый из прямоугольников на схеме отображает страницу индекса. С увеличением числа уровней производительность обработки индекса уменьшается. В SQL Server поддерживается два типа индексов: кластерные и некластерные.
Кластерный индекс – это двоичное дерево, в котором на нулевом уровне (уровне листов) содержатся страницы актуальных данных таблицы и физически информация хранится в логическом порядке данного индекса. Создание кластерного индекса требует наличия в БД свободного дискового пространства в 1,2 раза большего, чем существующий объем данных таблицы. Для каждой таблицы может существовать только один кластерный индекс.
В случае некластерных индексов страницы листового уровня содержат не актуальные данные таблицы, а указатель на строку данных, включающий номер страницы данных и порядковый номер записи на странице. Некластерный индекс не требует физического переупорядочения строк данных таблицы и соответственно, не требует наличия в БД большого свободного дискового пространства.
Некластерные индексы всегда имеют на один уровень больше кластерных, поэтому после достижения уровня листов дополнительно требуется выполнить чтение страницы данных. Если таблица имеет кластерный индекс, указатели строк некластерных индексов будут ссылаться на уровень листов кластерного индекса. Если таблица не имеет кластерного индекса указатель строк включает идентификатор файла, номер страницы данных и номер записи на странице.
Для одной таблицы может быть создано до 249 некластерных индексов. Строка индекса не может иметь длину больше 900 Байт и не должна включать более 16 столбцов значений.
Для любой таблицы достаточно иметь один кластерный и 2 - 6 некластерных индексов (за исключением создания хранилищ данных).
Индексы не могут быть созданы для столбцов со следующими типами данных: BIT, TEXT, IMAGE. Индексы не могут создаваться для видов.
Для создания индексов определенной таблицы базы данных SQL-сервера можно воспользоваться одним из следующих способов:
• создать индекс с помощью SQL-команды CREATE INDEX;
• воспользоваться возможностями утилиты SQL Server Enterprise Manager.
Рассмотрим второй способ создания индексов. Haчальным этапом создания индекса является выбор необходимой базы данных и таблицы, для которой он будет определяться.
Выполнение команды. Все задачи/Manage Indexes меню Действие отобразит на экране диалоговое окно управления индексами базы данных. Следует обратить внимание на выпадающие списки данного диалогового окна Database и Table, которые позволяют перемещаться между базами данных и их таблицами. При том в списке Existing indexes отображаются имеющиеся индексы для выбранных таблиц баз данных.
В нижней части данного диалогового окна расположены управляющие кнопки, выполняющие следующие действия:
New - создание нового индекса для выбранной таблицы БД;
Edit - редактирование параметров существующего индекса;
Delete - удаление предварительно выбранного индекса;
Close - закрытие диалогового окна;
Help - получение справочной информации по данному вопросу.
Для создания нового индекса следует воспользоваться кнопкой New данного диалогового окна. Это действие приведет к открытию другого диалогового окна Create New Index, с помощью которого и устанавливаются параметры индекса. В поле Index name данного диалогового окна необходимо ввести имя создаваемого индекса, после чего определить перечень полей участвующих в индексе. Для добавления определенного поля в индекс следует установить флажок слева от его имени. Здесь также можно просмотреть следующую информацию о поле: Column - имя поля, Data type - тип данных, Length - размер, Nullable - возможность использования Null-значений, Precision - точность и Scale - порядок вводимых значений. Можно менять порядок расположения полей в представленном списке.
Группа опций Index options позволяет настроить дополнительные параметры создаваемого индекса:
Unique values – при необходимости ввода в определённое поле только уникальных значений, следует установить данную опцию. Это позволит осуществлять автоматическую проверку уникальности при каждом добавлении новой записи. Если будет предпринята попытка ввода уже имеющегося значения в записи данного поля, будет выдано сообщение об ошибке. При этом следует обратить внимание на запрет присутствия NULL-значений в этом поле. При использовании NULL-значений и установке данной опции могут возникнуть ошибки. Поэтому рекомендуется установить обязательный ввод значений в поле, для которого планируется создание уникального индекса;
Clustered index - в системе SQL-сервер имеется возможность физического индексирования данных. Другими словами, использование индексов приводит к созданию отдельной структуры, которая связывается с физическим расположением данных в таблице. Использование этой опции позволяет произвести так называемое кластерное индексирование, в результате чего будут отсортированы данные в самой таблице согласно порядку этого индекса, и вся добавляемая информация будет приводить к изменению физического порядка данных. При этом нужно учитывать, что в таблице может быть определён только один кластерный индекс;
Ignore duplicate values - выбор данной опции приводит к игнорированию ввода повторяющихся значений в проиндексированных полях;
Do not recompute statistics - установка этой опции определяет функцию автоматического обновления статистики для таблицы;
File group - с помощью данной опции можно осуществить выбор файловой группы, в которой будет находиться создаваемый индекс;
Fill factor - данная возможность используется крайне редко. С помощью этой опции осуществляется настройка разбиения индекса на страницы. Если планируется частое изменение, удаление и добавление информации в таблице базы данных, то коэффициент FILLFACTOR следует установить как можно меньше, например, 20. Установка коэффициенту значения 100 рекомендуется при использовании больших таблиц, обращение к которым обычно происходит только для чтения;
Pad index - опция определяет заполнение внутреннего пространства индекса и используется совместно с опцией Fill factor;
Drop existing - при использовании кластерного индекса, выбор данной опции определяет его повторное создание, что позволяет предотвратить нежелательное обновление кластерных индексов.
Использование кнопки Edit SQL данного диалогового окна предоставляет пользователю сгенерированную SQL-команду, с помощью которой и будут выполняться произведенные настройки. В окне имеются управляющие кнопки Parse и Execute, с помощью которых можно проанализировать корректность установленных настроек (Parse), а также произвести запуск полученной SQL-команды (Execute).
Впоследствии созданные индексы могут использоваться в SQL-операторах SELECT следующим образом:
SELECT ...
FROM <имя таблицы> (INDEX= <имя_индекса>)
Одним из основных понятий баз данных, используемых при контроле целостности информации, является ключ. Разделяют первичные и внешние ключи. Первичный ключ - это уникальное поле (или несколько полей), однозначно определяющее записи таблицы базы данных. Внешние ключи - это поля таблицы, которые, как правило, соответствуют первичным ключам из других таблиц.
Рассмотрим основные различия между индексами и ключами:
SQL-сервер разрешает определить только один первичный ключ для таблицы, тогда как уникальных индексов можно создавать несколько;
при использовании первичного ключа запрещается возможность ввода NULL-значений, тогда как при работе с уникальными индексами этот запрет не является обязательным, однако придерживаться его желательно.
Рассмотрим процесс создания первичных ключей с помощью утилиты SQL Server Enterprise Manager. Первым этапом решения данной задачи будет выбор таблицы в списке объектов базы данных. Выполнение команды Design Table меню Действие приведет к загрузке дизайнера таблиц, в окне которого следует выбрать необходимые поля, убрать флажок из колонки Allow Nulls для этих полей. Установка первичного ключа осуществляется с использованием кнопки Set primary key.
Если данная операция была выполнена корректно, то слева от имени поля/полей должен появиться значок ключа. Удаление первичного ключа производится аналогично его установке.
Для создания индекса используется команда Transact-SQL.
CREATE INDEX, общий синтаксис которой следующий:
CREATE[UNIQUE][CLUSTERED|NONCLUSTERED] INDEX <имя индекса> ON <имя таблицы>(имя столбца[, имя столбца]…)
[WITH[PAD_INDEX,][,] FILLFACTOR=x][[,]
IGNORE_DUP_KEY][[,] DROP_EXISTING}[[,]
STATISTICS_NORECOMPUTE]]
[ON группа файлов]
Рассмотрим параметры этой команды:
PAD_INDEX - это размер пространства, оставляемого открытым на каждой внутренней странице. По умолчанию число элементов на внутренней странице ≥2. Этот параметр используется совместно с FILLFACTOR и использует процентное значение этого параметра.
IGNORE_DUP_KEY - позволяет продолжить работу даже при попытке поместить в таблицу строки с дублирующимся значением уникального ключевого поля – на экран выводится сообщение, а строка игнорируется.
DROP_EXISTING - при использовании этого параметра существующий кластерный индекс удаляется и создаётся заново, существующие некластерные индексы перестраиваются только после создания нового кластерного индекса
STATISTICS_NORECOMPUTE - блокирует автоматическое обновление статистических сведений по индексам.
Рассмотрим другие операции над индексами.
1) Просмотр индексов:
а) в окне SQL Server Enterprise Manager выбрать БД (пиктограмма в папке Databases);
б) перейти во вкладку Table and indexes – здесь отображаются имена всех таблиц и имена связанных с ними индексов для выбранной БД.
2) Переименование, удаление индексов.
Для удаления индекса используется команда Transact-SQL:
DROP INDEX[владелец.] <имя_ таблицы>. <имя_индекса> [,[владелец.] <имя_таблицы>, <имя_индекса>]
Переименование индекса осуществляется командой:
sp_rename <имя_объекта>, <новое имя> [,COLUMN|INDEX]
Можно также использовать окно SQL Server Enterprise Manager: открыть таблицу в дизайнере, из контекстного меню для таблицы выбрать Properties, в диалоговом окне Table Properties выбрать вкладку Indexes/Key - здесь можно переименовать индекс и создать новый индекс.
Стратегия использования индексов:
1) Следует индексировать:
столбцы, используемые для объединения таблиц;
столбцы, используемые для ограничения диапазона данных, которые анализируются при выполнении запросов;
столбцы, используемые в директивах ORDER BY и
GROUP BY;
столбцы, используемые для суммирования и подведения итогов.
2) Не следует индексировать:
таблицы с небольшим количеством строк;
столбцы, имеющие широкий диапазон значений;
столбцы, значения в которых очень длинные (>25 байт);
столбцы, не используемые при построении запросов.
3) Целесообразно использовать кластерные индексы для столбцов:
если столбцы используются во многих запросах;
если столбцы используются в ORDER BY или
GROUP BY;
если столбцы используются для объединения таблиц.
Использование функции автоматического выбора типа индекса:
открыть Query Analyzer;
в списке DB выбрать имя БД;
ввести текст SQL-команды;
Выбрать команду Query/Perform Index Analysis.
SQL Server проанализирует запрос для определения, можно ли создать индекс, который будет способствовать ускорению выполнения запроса. Если индекс удается обнаружить, то будет выведено окно Query Analyzer. Для создания предлагаемого индекса, щёлкнуть кнопку Accept.