

Ольков_С_Г_Аналитическая юриспруденция
.pdfвсегда мало! С другой стороны коэффициент локализации (коэффициент Джини), коэффициент Герфиндаля или коэффициент Лоренца охватывают всю совокупность, и всегда более точно отражают степень неравенства по всей совокупности. Например, если у нас возникла потребность выяснить значимо ли различаются между собой субъекты Российской Федерации по уровню преступности (по коэффициенту преступности на 100 тысяч народонаселения), то наиболее адекватный ответ будет получен с помощью коэффициентов концентрации.
Рассмотрим по порядку некоторые коэффициенты дифференциации и концентрации.
Децильный коэффициент (coefficient of deciles) (Kд) – частное от деления девятого дециля на первый дециль ранжированного вариационного ряда (дециль включает в себя 10 перцентилей):
Kд = ДД9 , где Д1 – первый дециль, Д9 – девятый дециль.
1
Для нахождения децилей в частотных рядах (интервальных рядах) используют специальные интерполяционные формулы. С использованием частот:
|
|
|
101 ×å fi - Fk−1 |
|
|
|
|
|
|
хk 1 |
|
||||||
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
Д1 = xk −1 + Lk |
× |
|
|
|
i=1 |
|
|
, где |
Д1 |
– |
первый |
дециль, |
|
− |
– |
||
|
|
|
fk |
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
нижняя граница интервала, содержащего первый дециль; |
Lk – |
||||||||||||||||
длина интервала, содержащего первый дециль ( |
|
− ); |
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
xk |
−хk 1 |
|
|
|
f k – частота интервала, включающего первый дециль; |
|
|
|
||||||||||||||
Fk −1 – накопленные частоты предшествующего интервала. |
|
|
|
||||||||||||||
С использованием частостей: |
|
|
|
|
|
хk 1 |
|
||||||||||
|
101 ×åwi -Wk−1 |
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
Д1 = xk−1 + Lk × |
|
|
|
|
i=1 |
, |
где |
Д1 |
– |
первый |
дециль, |
|
− |
– |
|||
|
|
|
|
|
wk |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
нижняя граница интервала, содержащего первый дециль; |
Lk – |
||||||||||||||||
длина интервала, содержащего первый дециль ( |
|
− ); |
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
xk |
−хk 1 |
|
|
|
wk – частость интервала, включающего первый дециль;
Wk −1 – накопленные частоcти предшествующего интервала. Величина Д1 – рассчитывается:
157
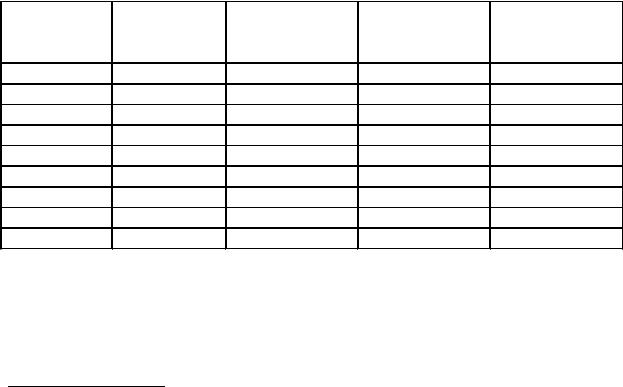
n |
n |
0,1×åfi – для частот; 0,1×åwi – для частостей. |
|
i=1 |
i=1 |
Для распознания интервала, включающего первый дециль, соответственно накапливаем частоты или частости пока они не превзойдут полученное число.
Нахождение девятого дециля:
|
|
|
|
9 ×å fi |
- Fk−1 |
|
||
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
; |
Д9 = xk−1 |
+ Lk × |
10 |
i=1 |
|
|
|||
|
|
fk |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
9 ×åwi -Wk−1 |
|
|||
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
. |
|
Д9 = xk−1 |
+ Lk × |
|
|
10 |
i=1 |
|
|
|
|
|
|
wk |
|
|
|
||
|
|
|
|
|
|
|
|
|
Величина Д9 – рассчитывается: |
||||||||
n |
|
|
|
|
|
|
|
n |
0,9 ×å fi |
– для частот; 0,9×åwi – для частостей. |
|||||||
i=1 |
|
|
|
|
|
|
|
i=1 |
Для распознания интервала, включающего девятый дециль, соответственно накапливаем частоты или частости пока они не превзойдут полученное число.
Рассмотрим пример. Возьмем вариационный ряд коэффициентов преступности по субъектам России за 2010 год10.
|
|
Накопленная |
|
Накопленная |
Х=КП, шт. |
Частота |
частота |
Частость, |
частость |
|
( fi ) |
( Fi ) |
( wi ) |
(Wi ) |
361-660 |
3 |
3 |
0,0365 |
0,0365 |
661-960 |
1 |
4 |
0,0122 |
0,0487 |
961-1260 |
9 |
13 |
0,1098 |
0,1585 |
1261-1560 |
13 |
26 |
0,159 |
0,3175 |
1561-1860 |
21 |
47 |
0,256 |
0,5735 |
1861-2160 |
12 |
59 |
0,146 |
0,7195 |
2161-2460 |
13 |
72 |
0,159 |
0,8785 |
2461-2787 |
10 |
82 |
0,122 |
1 |
ИТОГО |
82 |
|
|
|
n
0,1×å fi = 0,1×82 = 8,2 – для частот;
i=1
n
0,1×åwi = 0,1×1 = 0,1– для частостей.
i=1
10 Полностью данный вариационный ряд, как в исходном, так и ранжированном виде приводится в главе посвященной вероятностным распределениям.
158
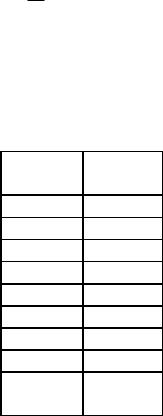
n
0,9×å fi = 0,9×82 = 73,8 – для частот;
i=1
n
0,1×åwi = 0,9×1 = 0,9 – для частостей.
i=1
Д1 = 961 +300 × 0,1×82 -4 =1101 , 9
Д9 = 2161 +300 × 0,9×82 -59 = 2223 ; 72
Kд = |
Д9 |
= |
2223 |
= 2,02 . |
|
Д1 |
1101 |
||||
|
|
|
Фондовый коэффициент (Кф) применительно к нашему примеру покажет во сколько раз средний коэффициент преступности у 10% субъектов РФ с самым высоким уровнем преступности выше среднего коэффициента преступности 10% регионов с самым низким уровнем преступности по
ранжированному ряду: Kф = ххв .
н
В нашем примере длина вариационного ряда составляет 82 наблюдения (единицы). 10%=8,2. Округлим до 8, а, следовательно, возьмем 8 значений, отсчитывая их от начала ранжированного ряда, и 8 значений, отсчитывая их от конца ранжированного ряда:
Верхни
еНижние
361  2787
2787
373  2751
2751
425  2719
2719
920  2633
2633
1003  2595
2595
1020  2583
2583
1031  2570
2570
1034  2504
2504
Итого:
6167 21142
хв = |
21142 |
= 2642 ,75 ; |
хн = |
6167 |
= 770,875 ; |
|
8 |
|
|
8 |
|
159
Kф = |
|
хв |
= |
2642,75 |
= 3,43 . |
|
|
|||
|
|
770,875 |
|
|
||||||
|
|
хн |
|
|
|
|
||||
Коэффициент дифференциации (coefficient of differentiation) |
||||||||||
вычисляется по формуле: |
|
|
||||||||
|
|
Q |
− Q |
1− Q1 |
|
|
|
|||
Kдиф |
|
|
|
Q |
, где Q1 |
– первый квартиль; Q3 |
– третий |
|||
= 3 |
1 |
= |
|
3 |
||||||
|
Q |
|||||||||
|
|
Q + Q |
|
|
1 |
|
|
|
||
|
3 |
1 |
1+ Q |
|
|
|
||||
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
3 |
|
|
|
квартиль. Знакомый нам коэффициент вариации (coefficient of variation):
Квар = σ ×100 , |
|
обычно |
в |
1,5 |
раза |
больше |
коэффициента |
|||||
x |
|
|
|
|
|
|
|
|
|
|
|
|
дифференциации: |
Кдиф » |
Kвар |
|
, |
а |
коэффициент |
вариации |
|||||
|
|
|||||||||||
|
|
|
|
|
1,5 |
|
|
|
|
|
|
|
соответственно: |
|
|
|
|
|
|
|
|
|
|||
Квар » Кдиф ×1,5 |
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Квар = σ ×100 = |
550 |
×100 = 30,69% , |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
||||||
x |
|
1792 |
|
|
|
|
|
|
|
|
|
|
Формула для нахождения нижнего квартиля: |
|
|
||||||||||
1+int[(1+n) / 2] , |
где |
int |
- означает |
целое число |
(дробная часть |
|||||||
2 |
|
|
|
|
|
|
|
|
|
|
|
|
игнорируется (отбрасывается):
1+int[(1+82) / 2] = 21 . Находим 21 по счету значение ранжированного
2
вариационного ряда коэффициентов преступности по субъектам РФ в 2010 году, которое в нашем случае равно 1426.
Формула для нахождения третьего квартиля:
é1+int[(1+ n) / 2]ù |
|
||
(n +1) - ê |
2 |
ú |
|
ë |
û . |
|
|
é1+int[(1+82) / 2]ù |
= 62 . Находим 62 по счету значение |
||
(82 +1) - ê |
2 |
ú |
|
ë |
û |
|
|
ранжированного вариационного ряда коэффициентов преступности по субъектам РФ в 2010 году, которое в нашем случае равно 2177.
Kдиф = |
Q3 |
− Q1 |
= 2177 |
−1426 |
= 0,208 . |
|||
|
Q3 |
+ Q1 |
2177 |
+1426 |
|
|||
Кдиф » |
Kвар |
= |
0,3069 |
= 0,205 . |
||||
1,5 |
1,5 |
|||||||
|
|
|
|
|
||||
160

Показатели концентрации по своей сути близки к показателям дифференциации. К показателям концентрации (concentration) относят:
1)коэффициент концентрации Джини (коэффициент локализации) (Gini index);
2)коэффициент Герфиндаля (Herfindahl index);
3)коэффициент Лоренца (Lorenz curve).
Пример. Возьмем данные о распределении коэффициентов преступности по субъектам Российской Федерации за 2010 год:
Число зарегистрированных преступлений в расчете на 100 тыс. чел. населения, единица,
значение показателя за год
|
2010 |
Российская Федерация |
1852 |
Центральный федеральный округ |
1620 |
Белгородская область |
1101 |
Брянская область |
1817 |
Владимирская область |
1794 |
Воронежская область |
1215 |
Ивановская область |
1767 |
Калужская область |
1795 |
Костромская область |
1440 |
Курская область |
1595 |
Липецкая область |
1405 |
Московская область |
1695 |
Орловская область |
1681 |
Рязанская область |
920 |
Смоленская область |
2164 |
Тамбовская область |
1267 |
Тверская область |
2198 |
Тульская область |
1034 |
Ярославская область |
1634 |
г.Москва |
1760 |
Северо-Западный федеральный округ |
1736 |
Республика Карелия |
2009 |
Республика Коми |
2072 |
Архангельская область |
1984 |
Ненецкий авт.округ |
2029 |
Вологодская область |
2012 |
161

Калининградская область |
1797 |
|
Ленинградская область |
1742 |
|
Мурманская область |
2012 |
|
Новгородская область |
1828 |
|
Псковская область |
1788 |
|
г.Санкт-Петербург |
1399 |
|
Южный федеральный округ (с 2010 |
1495 |
|
года) |
||
|
||
Республика Адыгея |
1055 |
|
Республика Калмыкия |
1431 |
|
Краснодарский край |
1275 |
|
Астраханская область |
2583 |
|
Волгоградская область |
1745 |
|
Ростовская область |
1403 |
|
Северо-Кавказский федеральный округ |
810 |
|
Республика Дагестан |
425 |
|
Республика Ингушетия |
373 |
|
Кабардино-Балкарская Республика |
1042 |
|
Карачаево-Черкесская Республика |
1020 |
|
Республика Северная Осетия - Алания |
1003 |
|
Чеченская Республика |
361 |
|
Ставропольский край |
1332 |
|
Приволжский федеральный округ |
1839 |
|
Республика Башкортостан |
1778 |
|
Республика Марий Эл |
1780 |
|
Республика Мордовия |
1031 |
|
Республика Татарстан |
1555 |
|
Удмуртская Республика |
2144 |
|
Чувашская Республика |
1426 |
|
Пермский край |
2719 |
|
Кировская область |
1547 |
|
Нижегородская область |
2427 |
|
Оренбургская область |
1631 |
|
Пензенская область |
1236 |
|
Самарская область |
2138 |
|
Саратовская область |
1494 |
|
Ульяновская область |
1365 |
|
Уральский федеральный округ |
2331 |
|
Курганская область |
2470 |
|
Свердловская область |
2195 |
162

Тюменская область |
2396 |
Ханты-Мансийский авт.округ-Югра |
2487 |
Ямало-Ненецкий авт.округ |
6275 |
Челябинская область |
2402 |
Сибирский федеральный округ |
2340 |
Республика Алтай |
2426 |
Республика Бурятия |
2751 |
Республика Тыва |
1890 |
Республика Хакасия |
2177 |
Алтайский край |
1928 |
Забайкальский край |
2595 |
Красноярский край |
2454 |
Иркутская область |
2633 |
Кемеровская область |
2330 |
Новосибирская область |
2504 |
Омская область |
1658 |
Томская область |
2787 |
Дальневосточный федеральный округ |
2230 |
Республика Саха (Якутия) |
1810 |
Камчатский край |
1591 |
Приморский край |
2570 |
Хабаровский край |
2308 |
Амурская область |
2148 |
Магаданская область |
2205 |
Сахалинская область |
2126 |
Еврейская автономная область |
2172 |
Чукотский авт.округ |
1685 |
Требуется: 1) вычислить коэффициент концентрации Джини (коэффициент локализации) и дать его интерпретацию. Построить кривую Лоренца; 2) вычислить коэффициент Герфиндаля; 3) вычислить коэффициент Лоренца; 4) используя правило сложения дисперсий, рассчитать общую, внутригрупповую и межгрупповую дисперсию для данного ряда (поскольку данный ряд мы разобьем на несколько частей); 5) найти коэффициент детерминации и эмпирическое корреляционное отношение с целью выяснения степени влияния региона на уровень преступности.
Решение:
163
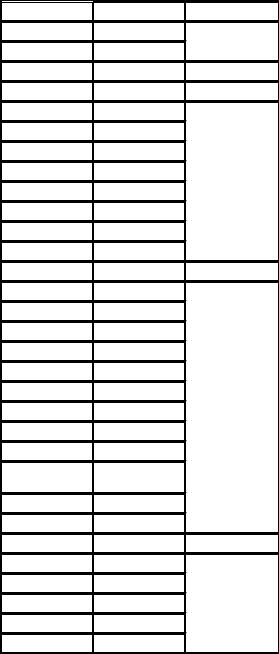
1)Из исходного ряда уберем коэффициенты преступности для России в целом и общие коэффициенты по округам, оставив только коэффициенты для каждого конкретного субъекта РФ.
2)Ранжируем вариационный ряд от минимума к максимуму. Всего имеем N=83; минимум=361 (Чеченская Республика); максимум=6275 (Ямало-Ненецкий автономный округ).
Р.S. Исключим из анализа «выброс» - значение для ЯмалоНенецкого округа, оставив 82 значения.
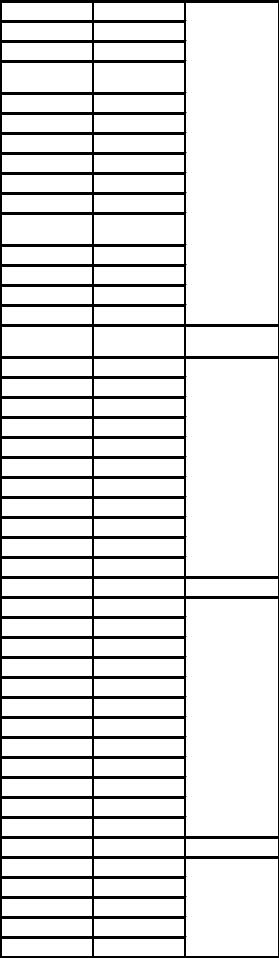
Таблица. Ранжированный ряд коэффициентов преступности по субъектам РФ с частотами.
№ п/п |
Ранж. |
Частота |
1 |
361 |
|
2 |
373 |
|
3 |
425 |
3 |
4 |
920 |
1 |
5 |
1003 |
|
6 |
1020 |
|
7 |
1031 |
|
8 |
1034 |
|
9 |
1042 |
|
10 |
1055 |
|
11 |
1101 |
|
12 |
1215 |
|
13 |
1236 |
9 |
14 |
1267 |
|
15 |
1275 |
|
16 |
1332 |
|
17 |
1365 |
|
18 |
1399 |
|
19 |
1403 |
|
20 |
1405 |
|
21 |
1426 |
|
22 |
1431 |
|
23 |
1440 |
|
24 |
|
|
1494 |
|
|
25 |
1547 |
|
26 |
1555 |
13 |
27 |
1591 |
|
28 |
1595 |
|
29 |
1631 |
|
30 |
1634 |
|
31 |
1658 |
|
164
32 |
1681 |
|
33 |
1685 |
|
34 |
1695 |
|
35 |
1742 |
|
36 |
|
|
1745 |
|
|
37 |
1760 |
|
38 |
1767 |
|
39 |
1778 |
|
40 |
1780 |
|
41 |
1788 |
|
42 |
1794 |
|
43 |
|
|
1795 |
|
|
44 |
1797 |
|
45 |
1810 |
|
46 |
1817 |
|
47 |
1828 |
21 |
48 |
|
|
1890 |
|
|
49 |
1928 |
|
50 |
1984 |
|
51 |
2009 |
|
52 |
2012 |
|
53 |
2012 |
|
54 |
2029 |
|
55 |
2072 |
|
56 |
2126 |
|
57 |
2138 |
|
58 |
2144 |
|
59 |
2148 |
12 |
60 |
2164 |
|
61 |
2172 |
|
62 |
2177 |
|
63 |
2195 |
|
64 |
2198 |
|
65 |
2205 |
|
66 |
2308 |
|
67 |
2330 |
|
68 |
2396 |
|
69 |
2402 |
|
70 |
2426 |
|
71 |
2427 |
|
72 |
2454 |
13 |
73 |
2470 |
|
74 |
2487 |
|
75 |
2504 |
|
76 |
2570 |
|
77 |
2583 |
|
165

78 |
2595 |
|
79 |
2633 |
|
80 |
2719 |
|
81 |
2751 |
|
82 |
2787 |
10 |
3) Определим |
длину интервала: L = |
КП макс − КП мин |
, где L – длина |
|
|
h |
|||
интервала, h |
– число групп, а число |
групп |
(h) по формуле |
|
Стерджесса: h=1+3,322×logN. Для нашего случая получим:
h=1+3,322×log(82)=7,36≈8; L = |
2787 −361 |
8 =303≈300. Примем число |
интервалов равным 8, а длину интервала 300.
P.S. Существует несколько способов определения длины интервалов: 1) равные интервалы (как в вышеприведенном случае):
L = Rh , где R – размах.
2) Равнонаполненные интервалы: f = Nh , где N – число наблюдений (единиц совокупности), f – частота. Для нашего примера N=82. Следовательно, имеем: f = 828 =10 . В данном случае
мы всю совокупность будем разбивать на десятки. В графе «частота» напротив каждого интервала будет стоять число 10 (за исключением последнего, куда можно включить число 12). Начало и конец каждого интервала для нашего примера будет определяться десятками (берем по 10 субъектов), отсчитанными по ранжированному ряду. Например, длина первого интервала будет от 361 до 1055, длина второго от 1101 до 1405 и т.д.
3) Интервалы, меняющиеся по арифметической прогрессии:
L = |
|
|
|
R |
|
, где R – размах. |
||||
1+2 +...h |
||||||||||
Для нашего примера: L = |
|
|
|
2787 −361 |
|
|
= 67,3 . |
|||
1 |
+ 2 |
+3 + 4 +5 +6 |
+ 7 |
+8 |
||||||
|
|
|
||||||||
Существуют и другие способы определения длины интервала, и с очевидностью встает вопрос, а какой из способов наиболее эффективный? В теории статистики на него имеется ответ
– способ, который для данного конкретного случая дает максимальную межгрупповую дисперсию. То есть для нашего примера нужно провести группировки по всем трем способам,
166