

66. Открытое хеширование.
Для сокращения времени доступа к данным в таблицах используется так называемое случайное упорядочивание или хеширование.
При открытом хешировании таблица рассматривается как массив связанных списков. Каждый такой список называется блоком и содержит записи, отображаемые хеш-функцией в один и тот же табличный адрес. Эта стратегия разрешения коллизий называется методом цепочек.
Если таблица является массивом связанных списков, то элемент данных просто вставляется в соответствующий список в качестве нового узла. Чтобы обнаружить элемент данных, нужно применить хеш-функцию для определения нужного связанного списка и выполнить там последовательный поиск.
Каждый новый элемент данных вставляется в хвост соответствующего связанного списка.
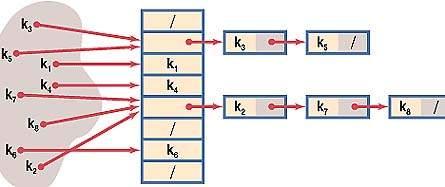
В общем случае метод цепочек быстрее открытой адресации, так как просматривает только те ключи, которые попадают в один и тот же табличный адрес. Кроме того, открытая адресация предполагает наличие таблицы фиксированного размера, в то время как в методе цепочек элементы таблицы создаются динамически, а длина списка ограничена лишь количеством памяти. Основным недостатком метода цепочек являются дополнительные затраты памяти на поля указателей. В общем случае динамическая структура метода цепочек более предпочтительна для хеширования.
67. Хеш-функции (ключи как натуральные числа, деление с остатком, умножение).
Хеш-функция – это некоторая функция h(k), которая берет некий ключ k и возвращает адрес, по которому производится поиск в хеш-таблице, чтобы получить информацию, связанную с k.
В качестве хеш-функции h(k) выбирается функция, которая более равномерно рассеивает ключи по пространству таблицы. Это важно для уменьшения числа коллизий.
При выборе хеш-функции следует учитывать:
сложность ее вычисления;
насколько равномерно распределяет она результат хеширования таблицы.
Для очередного ключа все m хеш-значений должны быть равновероятны.
Идеальной хеш-функцией является такая функция, которая для любых двух неодинаковых ключей дает неодинаковые адреса:
k1≠k2 ⇒ h(k1) ≠ h(k2)
Существует много способов создания функций хеширования, использующих преобразование произвольного натурального числа к натуральному индексу, лежащему в заданном диапазоне 0 .. m. Поэтому перед хешированием значения ключей приводятся к натуральному значению, если по своей природе они таковыми не являются. Например, последовательности ASCII-символов можно интерпретировать как целые числа, записанные в системе счисления с основанием 256. Вещественные числа можно привести к натуральному типу с некоторой заданной точностью, предварительно умножив на соответствующую степень 10.
Основные методы построения хеш-функции:
Метод деления с остатком
Ключу k ставится в соответствие остаток от деления k/m (m – число возможных хеш-значений).
h(k) = k mod m
Эффективность рассеивания зависит от m.
Метод умножения
h(k) = [m*(k*A mod 1)]
Здесь производится умножение ключа на некую константу А, лежащую в
интервале [0..1]. После этого берется дробная часть этого выражения и умножается на некоторую константу m, выбранную таким образом, чтобы результат не вышел за границы хеш-таблицы. Оператор [ ] возвращает наибольшее целое, которое меньше аргумента.