

Задания, лекции / LAB1
.rtf
Лабораторная работа N1
Моделирование случайных процессов. Экспериментальная проверка центральной предельной теоремы.
1. Нормальное (гауссовское) распределение.
Это распределение занимает центральное место в теории и практике вероятностно-статистических исследований. В качестве непрерывной аппроксимации к биномиальному распределению оно впервые рассматривалось А. Муавром еще в 1733 г. (теорема Муавра — Лапласа). Некоторое время спустя нормальное распределение было снова открыто и изучено независимо друг от друга К. Гауссом (1809 г.) и П. Лапласом (1812 г.). Оба ученых пришли к нормальной функции в связи со своей работой по теории ошибок наблюдений. Идея их объяснения механизма формирования нормально распределенных случайных величин заключается в следующем. Постулируется, что значения исследуемой непрерывной случайной величины формируются под воздействием очень большого числа независимых случайных факторов, причем сила воздействия каждого отдельного фактора мала и не может превалировать среди остальных, а характер воздействия — аддитивный (т. е. при воздействии случайного фактора F на величину а получается величина a+ (F), где случайная «добавка» (F), мала и равновероятна по знаку 1 . Можно показать, что функция плотности случайных величин подобного типа имеет вид
![]() (1.1)
(1.1)
где а и,2 — параметры закона, интерпретируемые соответственно как среднее значение и дисперсия данной случайной величины (в виду особой роли нормального распределения мы будем использовать специальную символику для обозначения его функции плотности и функции распределения).
-----------
1 Строгая теоретическая формализация этих условий содержится, например, в центральной предельной теореме Соответствующая функция распределения нормальной случайной величины (а, 2) обозначается Ф(х, а,2) и задается соотношением
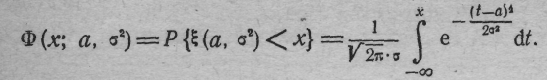 (1.1')
(1.1')
Условимся называть нормальный закон с параметрами а=0 и ,2=1 стандартным, а его функции плотности и распределения обозначать соответственно = (x; 0,1) и Ф(х) = Ф(х; 0,1).
Во многих случайных величинах, изучаемых в экономике, технике, медицине, биологии и в других областях, естественно видеть суммарный аддитивный эффект большого числа независимых причин. Но центральное место нормального закона не следует объяснять его универсальной приложимостью, как это было принято долгое время (по-видимому, под влиянием блестящих работ К. Гаусса и П. Лапласа) В этом смысле нормальный закон — это один из многих типов распределения, имеющихся в природе, правда, с относительно большим удельным весом практической приложимости. И потому нам понятна ирония, звучащая в известном высказывании Липмана (цитируемом А. Пуанкаре в своем труде «Исчисление вероятностей», Париж, 1912 г.): «Каждый уверен в справедливости нормального закона: экспериментаторы — потому, что они думают, что это математическая теорема; математики — потому, что они думают, что это экспериментальный факт». Однако не следует упускать из виду, что полнота теоретических исследований, относящихся к нормальному закону, а также сравнительно простые математические свойства делают его наиболее привлекательным и удобным в применении. Даже в случае отклонения исследуемых экспериментальных данных от нормального закона существует по крайней мере два пути его целесообразной эксплуатации: а) использовать его в качестве первого приближения; при этом нередко оказывается, что подобное допущение дает достаточно точные с точки зрения конкретных целей исследования результаты; б) подобрать такое преобразование исследуемой случайной величины , которое видоизменяет исходный «не нормальный» закон распределения, превращая его в нормальный. Удобным для статистических приложений является и свойство «самовоспроизводимости» нормального закона, заключающееся в том, что сумма любого числа нормально распределенных случайных величин тоже подчиняется нормальному закону распределения. Кроме того, закон нормального распределения имеет большое теоретическое значение: с его помощью выведен целый ряд других важных распределение построены различные статистические критерии и т. п. (2-, t- и F-распределения и опирающиеся на них критерии.).
Графики нормальных плотностей приведены на рис. 1.1.
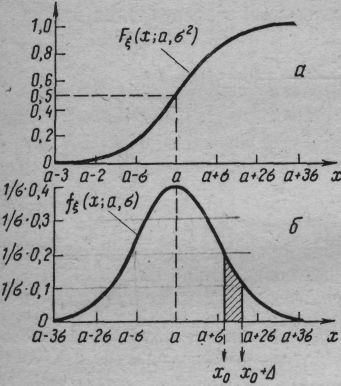
Рис. 1.1. Функции (а) распределения F норм (x; а, 2 ) и f норм (x; а, 2 нормального закона
Основные числовые характеристики нормального закона:
Равномерное (прямоугольное) распределение.
Случайная величина называется равномерно распределенной на отрезке [а,b], если ее плотность вероятности постоянна на этом отрезке и равна нулю вне его, т. е.
![]() (1.2)
(1.2)
Так как график функции f (x) изображается в виде прямоугольника (см. рис.1.1), то такое распределение также называют прямоугольным.
Соответственно функция распределения F (x) равномерного закона задается соотношениями:
 (1.3)
(1.3)
Примерами реальных ситуаций, связанных с необходимостью рассмотрения равномерно распределенных случайных величин, могут служить: анализ ошибок округления при проведении числовых расчетов (такая ошибка, как правило, оказывается равномерно' распределенной на интервале от —5 до +5 -единиц округляемого десятичного знака); время ожидания «обслуживания» при точно периодическом, через каждые Т единиц времени, включении
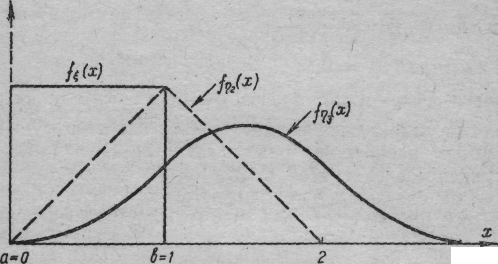
Рис. 1.2. Функция плотности равномерной случайной величины (f(x)) и суммы двух (f(x)) и трех (f(x)) независимых равномерно распределенных на [0, 1] случайных величин
(прибытии) «обслуживающего устройства» и при случайном поступлении (прибытии) заявки на обслуживание в этом интервале (например, время ожидания пассажиром прибытия поезда метро при условии точных двухминутных интервалов движения метро и случайного момента появления пассажира на платформе будет распределено приблизительно равномерно на интервале [0 мин, 2 мин]).
Отметим еще две важные ситуации, в которых используется равномерный закон. Во-первых, в теории и практике статистического анализа данных широко используется вспомогательный переход от исследуемой случайной величины с функцией распределения F(x) к случайной величине =F(), которая оказывается равномерно распределенной на отрезке. Этот прием является полезным при статистическом моделировании наблюдений, подчиненных заданному закону распределения вероятностей, при построении доверительных границ для исследуемой функции распределения и, в ряде других задач математической статистики. Во-вторых, равномерное распределение иногда используется в качестве «нулевого приближения» в описании априорного распределения анализируемых параметров в так называемом байесовском подходе в условиях полного отсутствия априорной информации об этом распределении.
Числовые характеристики равномерного закона:
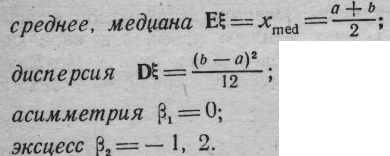
Отметим в заключение одно важное свойство суммы n независимых равномерно распределенных случайных величин: распределение этой суммы очень быстро (по мере роста числа слагаемых) приближается к нормальному закону. В частности, если i— равномерно распределенные на отрезке [0,1] и независимые случайные величины, то можно показать, что плотность такой случайной величины имеет вид
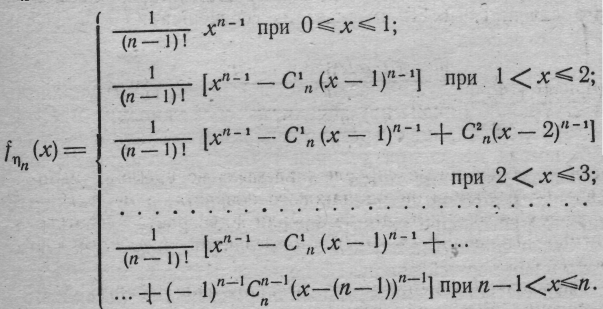
(область возможных значений случайной величины n очевидно, задается отрезком [0, n]). Геометрическое изображение последовательного изменения вида плотности fn по мере роста числа слагаемых n (для n = 1,2, 3) дано на рис. 1.2. Это свойство используется, в частности, при статистическом моделировании нормально распределенных наблюдений.
3. Проверка соответствия выбранной моделираспределения исходным данным (критерии согласия)
Пусть нами высказано предположение, что ряд наблюдений (1.1) образует случайную выборку, извлеченную из генеральной совокупности с некоторой модельной функцией распределения Fmod(X; (1), ..., (s)) где общий вид функции Fmod (т. е. тип модели) считается известным, а параметры, от которых она зависит, могут быть как известными, так и неизвестными.
Описываемые в данном параграфе критерии согласия предназначены для проверки гипотезы
H0 : F(x)= Fmod(X; (1), ..., (s)) (3.2)
и основаны на использовании различных мер расстоянии между анализируемой эмпирической функцией распределения, определяемой по выборке и гипотетической модельной Fmod(x; (1), ..., (s)).
3.1. Критерий 2 Пирсона. Данный критерий согласия позволяет осуществлять проверку гипотезы (3.2) в условиях, когда значения параметров (1), ..., (s)модельной функции распределения не известны исследователю. Для измерения степени отклонения эмпирического распределения от модельного этот критерий использует статистику 2 (читается хи-квадрат) Процедура статистической проверки гипотезы (3.2) складывается в данном случае из следующих этапов.
1. Весь диапазон значений исследуемой случайной величины разбивается на ряд интервалов группирования 1, 2,…, k не обязательно одинаковой длины. Это разбиение на интервалы необходимо подчинить следующим условиям:
а) общее количество интервалов k должно быть не меньшим 8;
б) в каждый интервал группирования, должно попасть не менее 7—10 выборочных значений , причем желательно, чтобы в разные интервалы попало примерно одинаковое число точек;
в) если диапазон исследуемой случайной величины — вся числовая прямая (полупрямая), то крайние интервалы группирования будут полупрямыми (соответственно один из них).
2. На основании выборочных данных х1, x2, … xn cтроятся статистические оценки неизвестных параметров, от которых зависит данный закон распределения F. Более корректным способом действий считается тот, при котором оценки вычисляются на основе сгруппированных данных.
3. Подсчитываются числа vi точек, попавших в каждый из интервалов группирования i , и вычисляются вероятности событий i т. е. вероятности
![]()
попадания в те же интервалы i;
4. Вычисляется величина критической статистики 2 (k—s—1) по формуле
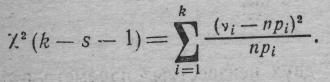
Далее находятся 100(1—/2) %-ная точка 21-/2 (k—s—1) и 100 /2 %-ная точка 2/2 (k—s—1) 2 распределения с k—s—1 степенями свободы (, как обычно, уровень значимости, которым мы задаемся заранее). Если
![]()
то гипотеза, о том, что исследуемая случайная величина | действительно подчиняется закону распределения Fmod, принимается.
3.2.
Проверка нормального характера
распределения по асимметрии, эксцессу
и средним отклонениям, Для приближенной
проверки нормальности исследуемой
случайной величины по результатам
ее наблюдения х1,
x2,
… xn
можно воспользоваться некоторыми
характерными свойствами нормального
распределения. В частности, как известно,
в случае нормального распределения
характеристики асимметрии 1
и эксцесса 2)
должны быть нулевыми и
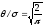 .
.
Поскольку практически мы имеем дело лишь с приближенными, выборочными значениями асимметрии эксцесса, средних абсолютного и квадратического отклонений, то мы не можем требовать точного выполнения соотношений
1 = 2 =0.
dn
= n/s(n)
=
 (3.3)
(3.3)
Однако исходя из нормального характера распределения исследуемой случайной величины , можно вывести и затабулировать законы распределения для 1(n), 2(n), (или для некоторых, подходящих для наших целей их комбинаций) и тем самым определить степень «допустимых» (в пределах нормальности ) отклонений от (3.3). Рассмотрим вариант приближенной проверки нормальности, основанной на вышеупомянутых свойствах 1,
1. Для проверки нормального характера распределения по асимметрии 1(n), и отношению средних отклонений dn = n/s(n) в случае сравнительно небольших объемов выборок (n>25) целесообразно воспользоваться наличием таблиц для вычисления (по данным входным параметрам Q и n) точных значений 100Q%-ных точек распределения статистик 1(n), и dn. В частности, процедура проверки нормальности в данном случае будет следующей: по формуле находим 1(n) – асимметрию:
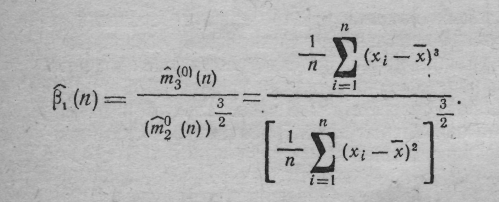
Далее подсчитываем величину dn .

Задавшись для Q1 одним из значений 0,01 или 0,05 и принимая во внимание объем выборки n по табл. находим величину 100 %-ной точки 1.Q1 задавшись для Q2 одним из значений 0,01, 0,05 или 0,10 и принимая во внимание объем выборки n, по табл. из [*] находим величины 100(1-Q2)%- ной точки d n Q2 и 100(1—Q2) %-ной точки dn•1-Q2 если хотя бы одно из неравенств

оказалось нарушенным, то гипотеза нормальности отвергается с уровнем значимости , подчиняющимся неравенствам 1:
2max (Q1, Q2)< < 2 (Q1, + Q2) - 2Q1Q2.
Существует также ряд других способов проверки нормального характера распределения по асимметрии, эксцессу.
* Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. М.Наука., 1985.
4. Задания
В данной лабораторной работе моделирование производится посредством табличного процессора MS Excel.
-
Смоделировать пятнадцать измерений случайной величины X(n=15), имеющей равномерный закон распределения на отрезке [0,1]. Представить измерения в виде вертикально расположенного массива.
Для этого можно, например, ввести n произвольных значений, примерно соблюдая закон распределения (т.е. с примерно равномерным распределением значений от 0 до 1). Можно воспользоваться функцией СЛЧИС (случайное число).
-
Найти среднее значение, среднеквадратичное отклонение, выборочную асимметрию, эксцесс. Разбить отрезок [0,1] на интервалы с учетом рекомендаций в разделе 3.1. , найти частоты, построить гистограмму.
Сделать предварительные выводы о характере распределения.
Замечания:
Для вычисления оценок основных статистических характеристик можно использовать соответствующие встроенные функции.
Для нахождения частот можно использовать функцию ЧАСТОТА. При этом следует иметь ввиду, что функция данная функция возвращает массив, поэтому для вывода значений можно воспользоваться функцией ИНДЕКС. (Рекомендуется посмотреть справочные данные по этим функциям и отработать тестовые примеры).
Желательно характеристики снабжать надписями и обозначениями, данные располагать удобно, наглядно, с определенной системой (например, значения в столбик, характеристики под ними и т.д….)
-
Смоделировать еще одну переменную Y(n=15), имеющей равномерный закон распределения на отрезке [0,1]. Для нее повторить задания п. 1 и 2.
-
Найти значения переменной Z, представляющей сумму соответствующих двух переменных ( zi=xi+yi) Для нее повторить задания п. 1 и 2. Сделать предварительные выводы о характере распределения. При выборе интервалов следует иметь ввиду, что отрезок, которому будут принадлежать значения уже окажется [0,2].
5) Повторить эксперимент для суммы трех равномерно распределенных величин (теперь отрезок будет [0,3]. Дополнительно, проверить гипотезу о нормальном характере распределения по критерию Пирсона.
При этом рекомендуется на свободном месте построить таблицу, содержащую следующие столбцы:
-
левый конец интервала,
-
правый конец интервала,
-
частоты vi ,
4. значение модельного распределения на левом конце интервала,
5. значение модельного распределения на правом конце интервала,
6. вероятность попадания в интервал pi (разность 2 и 3),
7.
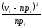 .
.
число строк - число интервалов.
Далее согласно 3.1 найти критерий и произвести проверку гипотезы. Для нахождения процентных точек можно воспользоваться функцией XИ2ОБР.
Замечание: имеющаяся в арсенале процедура ПИРСОН рассчитывает коэффициент корреляции и не относится к данному критерию согласия.
6.) Проделать эксперимент 5 для сумм 5-и и 12-и равномерно распределенных величин. Для данных случаев (кроме первого раза) можно использовать функцию XИ2ТЕСТ. Попытаться примерно оценить гипотезу о нормальном распределении с учетом п. 3.2 теоретической части.
7) Повторить эксперименты при n=50. Сделать выводы.