

Вопросы - Ответы Программирование
.pdf6. Работа с файлами. Типы файлов, основные операции.
Объявление файла
Файл — это именованная структура данных, представляющая собой последовательность элементов данных одного типа, причем количество элементов последовательности практически не ограничено. В первом приближении файл можно рассматривать как массив переменной длины неограниченного размера.
Как и любая структура данных (переменная, массив) программы, файл должен быть объявлен в разделе описания переменных. При объявлении файла указывается тип элементов файла.
В общем виде объявление файла выглядит так: Имя:file of ТипЭлементов;
Примеры:
res: file of char; // файл символов
koef: file of real; // файл вещественных чисел
f: file of integer; // файл целых чисел
Файл, компонентами которого являются данные символьного типа, называется символьным, или текстовым. Описание текстового файла в общем виде выглядит так:
Имя:TextFile;
где:
имя — имя файловой переменной;
TextFile — обозначениетипа, показывающее, что Имя — это файловая переменная, представляющая текстовый файл.
Вывод в файл
Непосредственно вывод в текстовый файл осуществляется при помощи инструкции write или writeln. В общем виде эти инструкции записываются следующим образом:
write (ФайловаяПеременная, СписокВывода) ;
writeln (ФайловаяПеременная, СписокВывода);
где:
ФайловаяПеременная — переменная, идентифицирующая файл, в который выполняется вывод;
СписокВывода -- разделенные запятыми имена переменных, значения которых надо вывести в файл. Помимо имен переменных в список вывода можно включать строковые константы.

Например, если переменная f является переменной типа TextFiie, то инструкция вывода значений переменных x1 и х2 в файл может быть такой:
write(f, 'Корни уравнения', xl, х2);
Различие между инструкциями write и writeln состоит в том, что инструкция writeln после вывода всех значений, указанных в списке вывода, записывает в файл символ "новая строка".
Открытие файла для вывода
Перед выводом в файл его необходимо открыть. Если программа, формирующая выходной файл, уже использовалась, то возможно, что файл с результатами работы программы уже есть на диске. Поэтому программист должен решить, как поступить со старым файлом: заменить старые данные новыми или новые данные добавить к старым. Способ использования старого варианта определяется во время открытия файла.
Возможны следующие режимы открытия файла для записи в него данных:
перезапись (запись нового файла поверх существующего или создание нового файла);
добавление в существующий файл.
Для того чтобы открыть файл в режиме создания нового файла или замены существующего, необходимо вызвать процедуру Rewrite(f), где f — файловая переменная типа TextFile.
Для того чтобы открыть файл в режиме добавления к уже существующим данным, находящимся в этом файле, нужно вызвать процедуру Append (f), где f — файловая переменная типа TextFile.
На рис. 7.1 приведено диалоговое окно программы, которая выполняет запись или добавление в текстовый файл.
Рис. 7.1. Диалоговое окно программы записи-добавления в файл
В листинге 7.1 приведена процедура, которая запускается нажатием командной кнопки Записать. Она открывает файл в режиме создания нового или замещения существующего файла и записывает текст, находящийся в поле компонента Memo1.
Имя файла нужно ввести во время работы в поле Editl. Можно задать предопределенное имя файла во время разработки формы приложения. Для этого надо присвоить значение,
например test.txt, свойству Edit1.Text.
Листинг 7.1. Создание нового или замещение существующего файла
procedure TForm1.Button1Click(Sender: TObject);
var
f: TextFile; // файл
fName: String[80]; // имя файла
i: integer;
begin
fName := Editl.Text;
AssignFile(f, fName);
Rewrite(f); // открыть для перезаписи
// запись в файл
for i: =0 to Memol.Lines.Count do // строки нумеруются с нуля
writeln(f, Memol.Lines[i]);
CloseFile(f); // закрыть файл
MessageDlg('Данные ЗАПИСАНЫ в файл ',mtlnformation,[mbOk],0);
end;
В листинге 7.2 приведена процедура, которая запускается нажатием командной кнопки Добавить. Она открывает файл, имя которого указано в поле Edit1, и добавляет в него содержимое поля Memol.
Листинг 7.2. Добавление в существующий файл
procedure TForm1.Button2Click(Sender: TObject);
var
f: TextFile; // файл
fName: String[80];.// имя файла
i: integer; begin
fName := Edit1.Text;
AssignFile(f, fName);
Append(f); // открыть для добавления
// запись в файл
for i:=0 to Memo1.Lines.Count do // строки нумеруются с нуля
writeln(f, Memo1.Lines[i]);
CloseFile(f); // закрыть файл
MessageDlg('Данные ДОБАВЛЕНЫ в файл ',mtInformation,[mbOk],0);
end;
Ввод из файла
Программа может вводить исходные данные не только с клавиатуры, но и из текстового файла. Для того чтобы воспользоваться этой возможностью, нужно объявить файловую переменную типа TextFiie, назначить ей при помощи инструкции AssignFile имя файла, из которого будут считываться данные, открыть файл для чтения (ввода) и прочитать (ввести) данные, используя инструкцию read или readln.
Открытие файла
Открытие файла для ввода (чтения) выполняется вызовом процедуры Reset, имеющей один параметр — файловую переменную. Перед вызовом процедуры Reset с помощью функции AssignFile файловая переменная должна быть связана с конкретным файлом.
Например, следующие инструкции открывают файл для ввода:
AssignFile(f, 'c:\data.txt'); Reset(f);
Если имя файла указано неверно, например файла с указанным именем на диске нет, то возникает ошибка времени выполнения программы. Следует отметить, что другой причиной возникновения ошибки при открытии файла, находящегося на гибком диске, может быть отсутствие готовности дисковода, проще говоря, отсутствие диска в накопителе.
Поэтому в программе следует предусмотреть возможность повторной попытки открытия файла после подтверждения повторения операции.
Как и при открытии файла для записи, программа может взять на себя задачу обработки возможной ошибки при открытии файла, проверяя значение функции IOResult.
Фрагмент программы, текст которого приведен в листинге 7.4, использует значение функции lOResult для проверки результата открытия файла. Если попытка открыть файл вызывает ошибку, то программа выводит диалоговое окно с сообщением об ошибке и запросом на подтверждение повторного открытия файла.
Листинг 7.4. Обработка ошибки открытия файла (фрагмент программы)
var
fname : string[80]; // имя файла f : TextFile; // файл
res : integer; // код ошибки открытия файла (значение lOResult) answ : word; // ответ пользователя
begin
fname := 'a:\test.txt'; AssignFile (f, fname);
repeat
<$I-}
Reset(f); // открыть файл для чтения
{$!+} res:=IOResult; if res <> 0
then answ:=MessageDlg('Ошибка открытия '
+ fname+#13 +'Повторить попытку?',mtWarning,
[mbYes, mbNo],0); until (res= 0) OR (answ = mrNo); if res <> 0
then exit; // завершение процедуры
//здесь инструкции, которые выполняются
//в случае успешного открытия файла
end;
7.Абстрактные типы данных. Назначение. Классические абстрактные типы данных (список, очередь, деревья, хеш таблицы и т.д. )
Хеш-табли́ца — это структура данных, реализующая интерфейс ассоциативного массива, а именно, она позволяет хранить пары (ключ, значение) и выполнять три операции: операцию добавления новой пары, операцию поиска и операцию удаления пары по ключу.
Введение
Существует два основных варианта хеш-таблиц: с цепочками и открытой адресацией. Хеш-таблица содержит некоторый массив H, элементы которого есть пары (хеш-таблица с открытой адресацией) или списки пар (хеш-таблица с цепочками).
Выполнение операции в хеш-таблице начинается с вычисления хеш-функции от ключа. Получающееся хеш-значение i = hash(key) играет роль индекса в массиве H. Затем выполняемая операция (добавление, удаление или поиск) перенаправляется объекту, который хранится в соответствующей ячейке массива H[i].
Ситуация, когда для различных ключей получается одно и то же хеш-значение, называется коллизией. Такие события не так уж и редки — например, при вставке в хештаблицу размером 365 ячеек всего лишь 23-х элементов вероятность коллизии уже превысит 50 % (если каждый элемент может равновероятно попасть в любую ячейку) — см. парадокс дней рождения. Поэтому механизм разрешения коллизий — важная составляющая любой хеш-таблицы.
В некоторых специальных случаях удаѐтся избежать коллизий вообще. Например, если все ключи элементов известны заранее (или очень редко меняются), то для них можно найти некоторую совершенную хеш-функцию, которая распределит их по ячейкам хештаблицы без коллизий. Хеш-таблицы, использующие подобные хеш-функции, не нуждаются в механизме разрешения коллизий, и называются хеш-таблицами с прямой адресацией.
Число хранимых элементов, делѐнное на размер массива H (число возможных значений хеш-функции), называется коэффициентом заполнения хеш-таблицы (load factor) и
является важным параметром, от которого зависит среднее время выполнения операций.
Свойства хеш-таблицы
Важное свойство хеш-таблиц состоит в том, что, при некоторых разумных допущениях, все три операции (поиск, вставка, удаление элементов) в среднем выполняются за время O(1). Но при этом не гарантируется, что время выполнения отдельной операции мало́. Это связано с тем, что при достижении некоторого значения коэффициента заполнения необходимо осуществлять перестройку индекса хеш-таблицы: увеличить значение размера массива H и заново добавить в пустую хеш-таблицу все пары.
Разрешение коллизий
Существует несколько способов разрешения коллизий.
Метод цепочек

Разрешение коллизий при помощи цепочек.
Каждая ячейка массива H является указателем на связный список (цепочку) пар ключ-значение, соответствующих одному и тому же хеш-значению ключа. Коллизии просто приводят к тому, что появляются цепочки длиной более одного элемента.
Операции поиска или удаления элемента требуют просмотра всех элементов
соответствующей ему цепочки, чтобы найти в ней элемент с заданным ключом. Для добавления элемента нужно добавить элемент в конец или начало соответствующего списка, и, в случае, если коэффициент заполнения станет слишком велик, увеличить размер массива H и перестроить таблицу.
При предположении, что каждый элемент может попасть в любую позицию таблицы H с равной вероятностью и независимо от того, куда попал любой другой элемент, среднее время работы операции поиска элемента составляет Θ(1 + α), где α — коэффициент заполнения таблицы.
Линейный однонаправленный список — это структура данных, состоящая
из элементов одного типа, связанных между собой.
В информатике линейный список обычно определяется как абстрактный тип данных (АТД), формализующий понятие упорядоченной коллекции данных.
На практике линейные списки обычно реализуются при помощи массивов и связных списков. Иногда термин «список» неформально используется также как синоним понятия «связный список».
К примеру, АТД нетипизированного изменяемого списка может быть определѐн как набор из конструктора и четырѐх основных операций:
1.операция, проверяющая список на пустоту;
2.операция добавления объекта в список;
3.операция определения первого (головного) элемента списка;
4.операция доступа к списку, состоящему из всех элементов исходного списка, кроме первого.
Характеристики
Длина списка. Количество элементов в списке.
Списки могут быть типизированными или нетипизированными. Если список типизирован, то тип его элементов задан, и все его элементы должны иметь типы, совместимые с заданным типом элементов списка. Обычно списки, реализованные при помощи массивов, являются типизированными.
Список может быть сортированным или несортированным

В зависимости от реализации может быть возможен произвольный доступ к элементам списка.
Очередь́ — структура данных с дисциплиной доступа к элементам «первый пришёл — первый вышел» (FIFO, First In — First Out). Добавление элемента (принято обозначать словом enqueue — поставить в очередь) возможно лишь в конец очереди, выборка — только из начала очереди (что принято называть словом dequeue — убрать из очереди), при этом выбранный элемент из очереди удаляется.
Способы реализации очереди
Существует несколько способов реализации очереди на языках программирования.
Массив
Первый способ представляет очередь в виде массива и двух целочисленных переменных start и end.
Обычно start указывает на голову очереди, end — на элемент, который заполнится, когда в очередь войдѐт новый элемент. При добавлении элемента в очередь в q[end] записывается новый элемент очереди, а end уменьшается на единицу. Если значение end становится меньше 1, то мы как бы циклически обходим массив и значение переменной становится равным n. Извлечение элемента из очереди производится аналогично: после извлечения элемента q[start] из очереди переменная start уменьшается на 1. С такими алгоритмами одна ячейка из n всегда будет незанятой (так как очередь с n элементами невозможно отличить от пустой), что компенсируется простотой алгоритмов.
Преимущества данного метода: возможна незначительная экономия памяти по сравнению со вторым способом; проще в разработке.
Недостатки: максимальное количество элементов в очереди ограничено размером массива. При его переполнении требуется перевыделение памяти и копирование всех элементов в новый массив.
Связный список
Второй способ основан на работе с динамической памятью. Очередь представляется в качестве линейного списка, в котором добавление/удаление элементов идет строго с соответствующих его концов.
Преимущества данного метода: размер очереди ограничен лишь объѐмом памяти.
Недостатки: сложнее в разработке; требуется больше памяти; при работе с такой очередью память сильнее фрагментируется; работа с очередью несколько медленнее.
Очереди в различных языках программирования
Практически во всех развитых языках программирования реализованы очереди. В CLI для этого предусмотрен класс System.Collections.Queue с методами Enqueue и Dequeue. В STL
также присутствует класс queue<>, определѐнный в заголовочном файле queue. В нѐм используется та же терминология (push и pop), что и в стеках.
Применение очередей
Очередь в программировании используется, как и в реальной жизни, когда нужно совершить какие-то действия в порядке их поступления, выполнив их последовательно. Примером может служить организация событий в Windows. Когда пользователь оказывает какое-то действие на приложение, то в приложении не вызывается соответствующая процедура (ведь в этот момент приложение может совершать другие действия), а ему присылается сообщение, содержащее информацию о совершенном действии, это сообщение ставится в очередь, и только когда будут обработаны сообщения, пришедшие ранее, приложение выполнит необходимое действие.
Клавиатурный буфер BIOS организован в виде кольцевого массива, обычно длиной в 16 машинных слов, и двух указателей: на следующий элемент в нѐм и на первый незанятый элемент.
Дерево — это связный граф (то есть такой граф, между любой парой вершин которого существует по крайней мере один путь), не содержащий циклов (то есть ациклический граф).[1] Ацикличность означает, что между любой парой вершин в дереве существует только один путь.
Ориентированное (направленное) дерево — ацикличный орграф (ориентированный граф, не содержащий циклов), в котором только одна вершина имеет нулевую степень захода (в неѐ не ведут дуги), а все остальные вершины имеют степень захода 1 (в них ведѐт ровно по одной дуге). Вершина с нулевой степенью захода называется корнем дерева, вершины с нулевой степенью исхода (из которых не исходит ни одна дуга)
называются концевыми вершинами или листьями.[2]
Формально дерево определяется как конечное множество T одного или более узлов со следующими свойствами:
1.существует один корень дерева T
2.остальные узлы (за исключением корня) распределены среди  непересекающихся множеств T1,...,Tm, и каждое из множеств является деревом; деревья T1,...,Tm называются поддеревьями данного корня T
непересекающихся множеств T1,...,Tm, и каждое из множеств является деревом; деревья T1,...,Tm называются поддеревьями данного корня T
Связанные определения
Степень узла — количество исходящих дуг (или, иначе, количество поддеревьев узла).
Концевой узел (лист) — узел со степенью 1 (то есть узел, в который ведёт только одно ребро; в случае ориентированного дерева — узел, в который ведёт только одна дуга и не исходит ни одной дуги).
Узел ветвления — неконцевой узел.
Уровень узла — длина пути от корня до узла. Можно определить рекурсивно:
1.уровень корня дерева T равен 0;
2.уровень любого другого узла на единицу больше, чем уровень корня ближайшего поддерева дерева T, содержащего данный узел.
Дерево с отмеченной вершиной называется корневым деревом.
o m-й ярус дерева T — множество узлов дерева, на уровне m от корня дерева.
oчастичный порядок на вершинах: 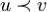 , если вершины u и v различны и вершина u лежит на (единственной!) элементарной цепи, соединяющей корень с вершиной v.
, если вершины u и v различны и вершина u лежит на (единственной!) элементарной цепи, соединяющей корень с вершиной v.
oкорневое поддерево с корнем v — подграф 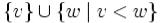 .
.
Остовное дерево (остов) — это подграф данного графа, содержащий все его вершины и являющийся деревом. Рёбра графа, не входящие в остов, называются хордами графа относительно остова.
Лес — множество (обычно упорядоченное), не содержащее ни одного непересекающегося дерева или содержащее несколько непересекающихся деревьев.
Двоичное дерево
Термин двоичное дерево (оно же бинарное дерево) имеет несколько значений:
Неориентированное дерево, в котором степени вершин не превосходят 3.
Ориентированное дерево, в котором исходящие степени вершин (число исходящих рёбер) не превосходят 2.
Абстрактная структура данных, используемая в программировании. На двоичном дереве основаны такие структуры данных, как двоичное дерево поиска, двоичная куча, красночёрное дерево, АВЛ-дерево, фибоначчиева куча и др.
N-арные деревья
N-арные деревья определяются по аналогии с двоичным деревом. Для них также есть ориентированные и неориентированные случаи, а также соответствующие абстрактные структуры данных.
N-арное дерево (неориентированное) — это дерево (обычное, неориентированное), в котором степени вершин не превосходят N+1.
N-арное дерево (ориентированное) — это ориентированное дерево, в котором исходящие степени вершин (число исходящих рёбер) не превосходят N.
Свойства
Дерево не имеет кратных рёбер и петель.
Любое дерево с n вершинами содержит n − 1 ребро. Более того, конечный связный граф является деревом тогда и только тогда, когда B − P = 1, где B — число вершин, P — число рёбер графа.
Граф является деревом тогда и только тогда, когда любые две различные его вершины можно соединить единственным элементарным путём.
Любое дерево однозначно определяется расстояниями (длиной наименьшей цепи) между его концевыми (степени 1) вершинами.
Любое дерево является двудольным графом. Любое дерево, содержащее счётное количество вершин, является планарным графом.