

Лабораторная работа №11. Изучение робастных оценок наклона линии регрессии
Пусть надежно установлено, что имеется функциональная зависимость между двумя группами числовых переменных представленными в виде пар чисел (xi,yi), где yi - значение отклика при заданном значении фактора xi. Пару значений (xi,yi) называют результатом одного измерения, a n - числом измерений. Предполагаем, что наблюдаемое в опыте значение отклика у можно мысленно разделить на две части. Одна из них закономерно зависит от х, другая часть - случайна по отношению к х:
у = ƒ(х) + ε.
Случайное слагаемое ε выражает либо внутренне присущую отклику изменчивость, либо влияние на него не учтенных факторов. Иногда ε называют ошибкой эксперимента, связывая её присутствие с несовершенством метода измерения у. Разделение у на закономерную и случайную составляющие можно сделать только мысленно. Реально ни f(хj), ни εj в отдельности не известны, в опыте узнаем только их сумму. Предположения относительно величин в классической модели регрессионного анализа:
все опыты были проведены независимо друг от друга в том смысле, что случайности, вызвавшие отклонение отклика от закономерности в одном опыте, не оказывали влияния на подобные отклонения в других опытах;
статистическая природа этих случайных составляющих оставалась неизменной во всех опытах.
Из этих предположений вытекает, что случайные величины εj статистически независимы и одинаково распределены. Для того, чтобы задача о подборе функции отклика была осмысленной, необходимо определить набор допустимых функций f(х). Как правило, предполагают, что множество допустимых функций является параметрическим семейством f(х, θ). Тогда восстановление зависимости между х и у оказывается эквивалентным указанию значения оценки θ по исходным данным (xi,yi). Знание θ позволит по заданному значению фактора х предсказывать закономерную часть отклика у. Ситуация, в которой экспериментатор может выбирать значения факторов xi по своему желанию и таким образом планировать будущие эксперименты, называется активным экспериментом. В этом случае значения факторов обычно рассматриваются как неслучайные. Сообразуясь с целями эксперимента, экспериментатор может выбрать его план (значения xi) наилучшим образом. В отличие от этой ситуации в пассивном эксперименте значения фактора складываются вне воли экспериментатора под действием обстоятельств. Математическая обработка совокупности (xi,yi) от этого не меняется. Самый простой случай подобных задач - это исследование связи между одной независимой переменной х и одной зависимой переменной (откликом) у. Эта задача носит название простой регрессии. Исходными данными этой задачи является совокупность (xi,yi). Первым шагом решения задачи является предположение о возможном виде функциональной связи. Примерами таких предположений могут являться зависимости:
у = a + bx, у = a + bx + сх², у = ea+bx, у = ln(a + bx),
где а, b, с - неизвестные параметры, которые надо определить по исходным данным. Для подбора вида зависимости строят график точек (xi,yi), называемый "облако рассеяния". Его вид подсказывает вероятную функцию. После подбора регрессионной модели и нахождения её параметров, выясняют, насколько хорошо модель описывает имеющиеся данные. Для этого изучают разности между наблюдаемыми и предсказанными значениями у, так называемые остатки. Согласно общим предположениям регрессионного анализа, остатки должны вести себя как независимые одинаково распределенные случайные величины. Исследование остатков начинают с изучения графиков их зависимости от номера наблюдения, зависимой и независимой переменных. Они могут показать наличие какой-то зависимости, не учтенной в модели. Скажем, при подборе простой линейной зависимости между х и у график остатков может показать необходимость перехода к нелинейной модели или включения в модель периодических компонент. График остатков показывает резко отклоняющиеся от модели наблюдения - выбросы. Подобным наблюдениям уделяют особое внимание, так как их присутствие может грубо искажать значения оценок. Устранение выбросов может проводиться с помощью удаления этих данных из совокупности. Эта процедура называется цензурированием. Можно применять робастные методы оценивания параметров, устойчивые к грубым отклонениям. В простейшем случае задача регрессионного анализа предполагает установление линейной зависимости:
yi = A + bxi + εi.
Здесь xi - заданные числа (значения фактора); yi - наблюденные значения отклика; εi - независимые (ненаблюдаемые) одинаково распределенные случайные величины. Считаем, что нет оснований предполагать какой-либо закон распределения случайных величин ε, однако можно считать, что εi распределены непрерывно. Выводы о зависимости между у и х будем основывать на рангах у. Ясно, что в таком случае ничего определенного о величине А сказать не удается, так как изменение всех yi на одну и ту же постоянную величину не изменяет рангов yi. Задача свелась к поиску единственного неизвестного коэффициента наклона b. Нумеруем наблюдения так, чтобы иксы возрастали с ростом номера. Если из наблюденных величин yi вычесть истинные значения bхi то остатки yi - bxi = А + εi образуют последовательность независимых одинаково распределённых случайных величин. Не зная b, будем вычитать из yi переменную величину βxi, где β изменяется по нашему произволу. Тенденцию изменения значений с измене-нием номера или её отсутствие можно обнаружить с помощью коэффициентов корреляции. Выборочный коэффициент корреляции Пирсона по совокупности (xi, yi - xi) имеет вид:
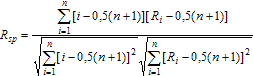
Наименьшей зависимости остатков соответствует r = 0. Для неизвестного β это дает уравнение:
![]()
Его решение - это известное выражение оценки наименьших квадратов. Составим коэффициент ранговой корреляции Спирмена. Он получается заменой величин yi - bxi и xi в коэффициенте выборочной корреляции Пирсона на их ранги. Упорядочим xi. Тогда ранг xi равен i (при условии отсутствия совпадений между xi). Таким образом:
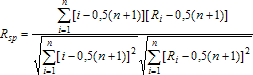
где Ri - ранг величины yi - bxi. Поскольку Ri принимает значения от 1 до n, то оба корня в знаменателе равны n(n² - 1)/12. Преобразовав числитель, находим:
![]()
Коэффициент
корреляции Кендэла определяется как
![]() ,
где Р и Q - соответственно число
согласованных и несогласованных пар
(yi
- bxi,
xi)
и (yj
- bxj,
xj)
для всех i, j таких, что i < j. Здесь пары
(yi
- bxi,
xi)
и (yj
- bxj,
xj)
называются согласованными, если оба
значения одной пары больше обоих значений
другой. В противном случае пары называются
несогласованными. Величина K = Р - Q
называется статистикой Кендэла. Ее
можно записать в следующем виде:
,
где Р и Q - соответственно число
согласованных и несогласованных пар
(yi
- bxi,
xi)
и (yj
- bxj,
xj)
для всех i, j таких, что i < j. Здесь пары
(yi
- bxi,
xi)
и (yj
- bxj,
xj)
называются согласованными, если оба
значения одной пары больше обоих значений
другой. В противном случае пары называются
несогласованными. Величина K = Р - Q
называется статистикой Кендэла. Ее
можно записать в следующем виде:
![]() .
Измеренная с помощью этих коэффициентов
ранговой корреляции зависимость между
рядами (yi
- βxi)
и xj
будет наименьшей, если выбрать β так,
чтобы τ и Rsp
были равны нулю. Проанализируем упрощённо
зависимость τ(β). При β < 0 и очень больших
по абсолютной величине, порядок следования
разностей (yi
- βxi)
определяется исключительно числами
xi, то есть τ = 1. Пусть теперь начинает
возрастать. Первое изменение порядка
следования произойдет при первом
совпадении: yi
- βxi
= yj
- βxj
. При этом Р и Q изменятся на 1 каждый,
уменьшится на 4/n(n - 1). При дальнейшем
увеличении β такие изменения будут
происходить всякий раз, как будет
достигаться равенство в парах yi
- βxi
= yj
- βxj,
то есть при таких значениях β = βij:
.
Измеренная с помощью этих коэффициентов
ранговой корреляции зависимость между
рядами (yi
- βxi)
и xj
будет наименьшей, если выбрать β так,
чтобы τ и Rsp
были равны нулю. Проанализируем упрощённо
зависимость τ(β). При β < 0 и очень больших
по абсолютной величине, порядок следования
разностей (yi
- βxi)
определяется исключительно числами
xi, то есть τ = 1. Пусть теперь начинает
возрастать. Первое изменение порядка
следования произойдет при первом
совпадении: yi
- βxi
= yj
- βxj
. При этом Р и Q изменятся на 1 каждый,
уменьшится на 4/n(n - 1). При дальнейшем
увеличении β такие изменения будут
происходить всякий раз, как будет
достигаться равенство в парах yi
- βxi
= yj
- βxj,
то есть при таких значениях β = βij:
![]()
если все числа xi различны между собой. Иначе используем лишь такие i, j для которых xi ≠ xj. Точек изменения коэффициентов оказывается в этом случае меньше, чем число сочетаний Сn², но величины скачков могут быть больше. Симметрично расположенные скачки равны по величине, поэтому график τ(β) проходит через ноль при таком β0, что левее и правее него остаются по одинаковому количеству точек разрыва. Иначе говоря:
![]()
Это
оценка коэффициента наклона. В условиях
гауссовской модели она менее точна, чем
стандартная, но зато она применима в
гораздо более широких условиях.
Строим
доверительные интервалы для неизвестного
b. Пусть коэффициент доверия 1 - 2ε. Пусть
τε
для данного n обозначает верхнее
критическое значение коэффициента τ.
Точки скачков функции τ(β) выделяют
доверительный интервал β: |τ(β)| ≤ τε.
Статистика Кендэлла K, введем функцию
Это оценка коэффициента наклона. Можно
показать, что в условиях гауссовской
модели она менее точна, чем стандартная,
но зато она применима в гораздо более
широких условиях.
Основываясь на
характере функций, можно построить
доверительные интервалы для неизвестного
b. Выберем коэффициент доверия 1 - 2а.
Пусть для данного n τа обозначает верхнее
критическое значение для коэффициента
ранговой корреляции τ. Точки скачков
функции τ(β) выделяют доверительный
интервал: β: |τ(β)| ≤ τa.
Учитывая, что таблицы распределения
чаще составлены не для величины τa,
а для статистики Кендэла K, введем функцию
![]() .
Скачки этой функции равны 2.
Доверительный интервал для b с коэффициентом
доверия 1 - 2ε имеет вид: |K(β)| ≤ Kε,
где Kε
есть решение уравнения:
.
Скачки этой функции равны 2.
Доверительный интервал для b с коэффициентом
доверия 1 - 2ε имеет вид: |K(β)| ≤ Kε,
где Kε
есть решение уравнения:
Р{|K|
≤ Kε}
= 1 - 2ε
![]() Р{K
≥ Kε
+ 2} = 0,5ε.
Р{K
≥ Kε
+ 2} = 0,5ε.
Обозначим вариационный ряд βij через S. Если среди хi нет совпадающих, то количество чисел βij равно N = 0,5n(n - 1). Положим M1 = (N - Kа)/2, M2 = (N + Kа)/2. Тогда доверительный интервал для b имеет вид:
{SM¹ ≤ b ≤ SM² + 1}, P{ SM¹ ≤ b ≤ SM² + 1} = 1 - ε.
В
случае больших n для K используется
приближенное выражение, основанное на
нормальной аппроксимации распределения
K при гипотезе независимости:
![]() ,
где z - обычный квантиль нормального
распределения. Известна методика учёта
поправок при совпадениях час
,
где z - обычный квантиль нормального
распределения. Известна методика учёта
поправок при совпадениях час
Вопросы для самопроверки
В чём отличие группированного статистического ряда от упорядоченной статистической совокупности
В чём отличие частоты от вероятности
Вопросы к экзаменам
1.Первичная статистическая совокупность, её упорядочение
2. Статистическая функция распределения.
3. Группированный статистический ряд.
4. Гистограмма.
5. Выравнивание статистических распределений.
Именной указатель
Перечень сокращений