

Введение
В большинстве случаев изображение представляется для наблюдателя в виде совокупности однородных участков, отличающихся друг от друга теми или иными характеристиками. Количество различных типов, или классов, участков обычно невелико, вся же картина разделена на непересекающиеся области, каждая из которых заполнена изображением одного из типов. Целью анализа таких изображений наблюдателем или автоматической системой является определение геометрических областей и указание для каждой из них номера типа (класса). Иногда такую совокупность сведений об исходном изображении называют ею картой. Обработка изображения, позволяющая получить карту, называется сегментацией.
Количество признаков, по которым могут отличаться друг от друга различные типы участков изображения, может быть достаточно большим. Встречается большое число задач, где участки изображения имеют разный уровень средней яркости. При одинаковом уровне средней яркости участков изображения может различаться их дисперсия флуктуации. Часто можно наблюдать сцену, на которой различие областей проявляется в разном проявлении корреляционных свойств: медленные, плавные колебания яркости на одних участках изображения сменяются существенно более быстрыми перепадами яркости на других. Во многих случаях участки изображения разных типов различаются не по одной какой-либо характеристике, а по нескольким.
Встречаются изображения, в которых вся сцена разбита на области, не отличающиеся друг от друга ни по каким своим характеристикам. Вся информация (карта) в этих случаях представляет собой совокупность границ между отдельными участками. Типичным примером такого типа служит изображение кирпичной кладки. Очевидно, что для сегментации таких изображений непригодны методы, основанные на анализе моментно-корреляционных характеристик, о которых говорилось выше [1].
Большое разнообразие в задачу сегментации вносит обработка цветных изображений. Одним из важнейших признаков для сегментации в этом случае может служить цвет, который дополняет совокупность характеристик, применяемых при обработке черно-белых изображений. К этому же типу задач относится и сегментация спектрозональных изображений. Отметим, что такие задачи значительно сложнее, а число публикаций в этой области сравнительно невелико. И подчеркнем, что такие задачи представляют очень большой научный и практический интерес и, вероятно, они составляют одни из перспективных направлений развития цифровой обработки изображений.
Методы, используемые при сегментации, еще более разнообразны, чем признаки, по которым различаются отдельные классы. Следует отметить, что единого общепризнанного, эффективного подхода, который бы лежал в основе всех или хотя бы большинства методов, не существует.
Методы сегментации можно разделить на два класса: автоматические – не требующие взаимодействия с пользователем и интерактивные – использующие пользовательский ввод непосредственно в процессе работы. В данной курсовой работе рассматриваются автоматический метод.
Задачи автоматической сегментации делятся на два класса:
1) выделение областей изображения с известными свойствами;
2) разбиение изображения на однородные области.
Между этими двумя постановками задачи есть принципиальная разница. В первом случае задача сегментации состоит в поиске определенных областей, о которых имеется априорная информация (например, мы знаем цвет, форму областей, или интересующие нас области представляют собой изображения известного объекта). Методы этой группы узко специализированы для каждой конкретной задачи. Сегментация в такой постановке используется в основном в задачах машинного зрения (анализ сцен, поиск объектов на изображении)
Во втором случае никакая априорная информация о свойствах областей не используется, зато на само разбиение изображения накладываются некоторые условия (например, все области должны быть однородны по цвету и текстуре). Так как при такой постановке задачи сегментации не используется априорная информация об изображенных объектах, то методы этой группы универсальны и применимы к любым изображениям. В основном сегментация в этой постановке применяется на начальном этапе решения задачи, для того чтобы получить представление изображения в более удобном виде для дальнейшей работы [2].
Исследуемые в микроскопии препараты во многих случаях имеют малую толщину, и следовательно, малые коэффициенты поглощения. Получаемые изображения при визуализации спектров, записанных с помощью микроскопа-гиперспектрофотометра рис. 1, часто имеют недостаточный контраст для детального исследования микрообъектов, поэтому требуется цветовое контрастирование изображений. Методы цветового контрастирования обычно выполняются над изображениями, записанными в формате RGB. В случае если изображение получено в результате приведения спектра к цветовой системе RGB, появляется возможность повышения контраста при использовании предварительной обработки спектров перед приведением их к системе RGB. В настоящей статье рассмотрен эффективный метод модификации спектра для повышения цветового контраста изображений [3].
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Целью данной работы является разработка методики сегментации гиперспектральных данных на основе алгоритма k-внутригрупповых средних на основе принципа минимальной длины описания.
Для получения гиперспектральных данных существует несколько основных способов, в данной работе рассматриваются и сравниваются два из них. Рассмотрим первый способ. На рис. 1 показана блок-схема микроскопа-гиперспектрофотометра, который использовался для получения гиперспектральных данных о микрообъектах.

Рис. 1. Блок-схема микроскопа-гиперспектрофотометра
Излучение от осветителя направляется на входную щель монохроматора, который выделяет часть излучения в узком спектральном интервале. С помощью волоконного жгута излучение с выходной щели монохроматора направляется на микрообъект. В зависимости от выбранного типа микроскопа, работающего в режиме пропускания или отражения, излучение, прошедшее через образец или отраженное от него, направляется в объектив микроскопа, который формирует в плоскости видеоматрицы увеличенное изображение микрообъекта в установленном спектральном интервале. При последовательной перестройке длины волны выходящего из монохроматора излучения формируется набор изображений микрообъекта, полученных на разных длинах волн, которые образуют гиперспектральный куб.
Отличие второго способа от использованного в работе состоит в применении микроскопа с перестраиваемым акустооптическим светофильтром, установленным перед видеоматрицей, который выделяет заданный спектральный интервал.

Рис. 2. Схема установки для получения гиперспектральных данных с помощью микроскопа с переключаемым акустооптическим светофильтром: АОПС – акустооптический перестраиваемый светофильтр
Описанный способ (см. рис. 2) получения гиперспектральных данных позволяет достигнуть высокого пространственного разрешения, которое определяется количеством и размером элементов видеоматрицы. Однако, спектральное разрешение, определяемое полушириной спектра пропускания светофильтра, остается на уровне несколько десятков нанометров, что не достаточно для решения многих задач качественного и количественного анализа состава микрообъектов.
На основе выводов и результатов выполненного анализа, целесообразно использовать первый способ получения гиперспектральных данных. Ниже представлена иллюстрация (см. рис. 3) структуры гиперспектральных данных [4].

Рис. 3. Структура гиперспектральных данных [7]
Применительно к сегментации гиперспектральных данных набор коэффициентов пропускания на каждой длине волны можно определить как вектор признаков. Таким образом, при кластеризации в группы объединяются объекты со схожими спектрами пропускания.
Далее описывается эвристический алгоритм кластеризации, который основан на вычислении k внутригрупповых средних, а так же принцип минимальной длины описания (МДО) который позволяет автоматически определить количество различных объектов на изображении. Использование данного метода избавляет пользователя от необходимости ввода эталонных спектров и позволяет анализировать гиперспектральных данные полностью автоматически.
В
задаче распознавания без учителя
машинной системе предоставляется лишь
совокупность образов
 ∈Χ
, i=1,...,M.
На основе этих образов система должна
не только построить решающее правило
∈Χ
, i=1,...,M.
На основе этих образов система должна
не только построить решающее правило
 ,но и сформировать само множество классов
,но и сформировать само множество классов
Поскольку решающее правило относит каждый образ обучающей выборки к одному из классов, задача, по сути, сводится к тому, чтобы объединить образы обучающей выборки в группы (на основе которых и формируются классы). Такое объединение называется группированием. Коль скоро группирование осуществлено, для построения решающего правила могут быть применены ранее рассмотренные методы распознавания с учителем. Здесь, однако, возникает вопрос: на каком основании какие-то образы следует относить к одной группе, а какие-то – к другой?
Один из интуитивно очевидных ответов на этот вопрос заключается в том, что объединяться должны похожие друг на друга образы. Степень сходства определяется расстоянием в пространстве признаков. Выбор метрики, однако, во многом произволен, хотя чаще всего используют евклидово расстояние. Если в классы объединяются наиболее близко расположенные друг к другу образы, то задача группирования превращается в задачу кластеризации, то есть в задачу поиска кластеров (областей, содержащих компактно расположенные группы образов).
Рассмотрим
эвристический алгоритм кластеризации,
который основан на вычислении k
внутригрупповых средних, или кратко
алгоритм k
средних. Этот алгоритм требует задания
числа кластеров, исторически обозначаемых
через k.
Мы, однако, как и выше, будем использовать
переменную d для обозначения числа
классов и
 для обозначения множества классов.
для обозначения множества классов.
Алгоритм состоит из следующих шагов:
Каждому из d кластеров произвольным образом назначаются их центры (или эталонные образы)
 .
Часто в качестве этих центров выступают
первые (или случайно выбранные) d
образов обучающей выборки
.
Часто в качестве этих центров выступают
первые (или случайно выбранные) d
образов обучающей выборки
 =
=
 ,где
i=1,…d.
,где
i=1,…d.
Каждый образ выборки относится к тому классу, расстояние до центра которого, минимально:
 где
i
= 1,…,d.
где
i
= 1,…,d.
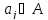
Центры кластеров пересчитываются, исходя из того, какие образы
к
каждому из них были отнесены:
 , где
, где –
–

количество
образов попавших в класс
 .
.
Шаги 2 и 3 повторяются, пока не будет достигнута сходимость то есть пока классы не перестанут изменяться.
Проблема выбора числа кластеров в задаче группирования очень важна, поскольку предположение о том, что число кластеров известно, является очень сильным ограничением на класс решаемых задач. Наиболее многообещающим инструментом решения этой проблемы является принцип минимальной длины описания (МДО).
Рассмотрим,
как выбор числа кластеров может быть
осуществлен на основе принципа МДО в
методе k средних. Пусть на некотором
шаге этого алгоритма получены центры
кластеров:
 .
Эти центры кластеров, по сути, являются
параметрами модели данных. Общее число
параметров в такой модели равно Nd.
.
Эти центры кластеров, по сути, являются
параметрами модели данных. Общее число
параметров в такой модели равно Nd.
Кодирование
параметров модели обычно выполняется
путем дискретизации пространства
параметров с некоторой точностью.
Известно, что для регулярных параметрических
семейств оптимальной является точность
 ,
где M
– количество элементов в выборке.
Объяснение этой точности на интуитивном
уровне сводится к тому, что величина
,
где M
– количество элементов в выборке.
Объяснение этой точности на интуитивном
уровне сводится к тому, что величина
 представляет
собой величину ожидаемой ошибки в оценке
каждого из элементов вектора параметров,
поэтому кодировать эти параметры с
большей точностью не имеет смысла.
Помимо этого в описание модели также
должно входить значение числа кластеровd,
для чего потребуется примерно
представляет
собой величину ожидаемой ошибки в оценке
каждого из элементов вектора параметров,
поэтому кодировать эти параметры с
большей точностью не имеет смысла.
Помимо этого в описание модели также
должно входить значение числа кластеровd,
для чего потребуется примерно
 бит.
Таким образом, общая длина описания
модели может быть оценена как
бит.
Таким образом, общая длина описания
модели может быть оценена как

Описанием
каждого образа
 обучающей
выборки в рамках данной модели будет:
обучающей
выборки в рамках данной модели будет:
Номер
 ближайшего
эталона (центра какого-либо класса):
ближайшего
эталона (центра какого-либо класса):
 ,
для указания, которого требуется
,
для указания, которого требуется
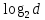 бит.
бит.
Закодированный в некотором виде вектор разности
 .
Длина описания этой разности может
быть оценена как
.
Длина описания этой разности может
быть оценена как ,
гдеC
- некоторая константа, которая может
не учитываться в конечном критерии.
Смысл этой константы в том, что она
указывает точность кодирования векторов.
Если разность
,
гдеC
- некоторая константа, которая может
не учитываться в конечном критерии.
Смысл этой константы в том, что она
указывает точность кодирования векторов.
Если разность
 меньше точности кодирования, то длина
описания этой разности полагается
равной нулю (если этот момент не
учитывать, то при стремлении разности
к нулю, длина описания будет стремиться
к минус бесконечности, что лишено
смысла).
меньше точности кодирования, то длина
описания этой разности полагается
равной нулю (если этот момент не
учитывать, то при стремлении разности
к нулю, длина описания будет стремиться
к минус бесконечности, что лишено
смысла).
Таким образом, длина описания данных в рамках модели может быть оценена как :

Итоговый критерий на основе принципа МДО будет :

При фиксированном значении d поиск центров кластеров может производиться обычным методом k средних. Если же этот метод выполнить при разных значениях d, то выбор между полученными результатами можно осуществить на основе критерия МДО.
Благодаря
использованию критерия МДО для выбора
числа кластеров решается проблема
переобучения. Действительно, если
увеличивать число кластеров, то не
только будет уменьшаться длина описания
данных
 ,
определяемая средним расстоянием от
образов выборки до центров кластеров,
но также будет увеличиваться и длина
описания модели
,
определяемая средним расстоянием от
образов выборки до центров кластеров,
но также будет увеличиваться и длина
описания модели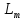 [5].
[5].
ПРАКТИЧЕСКАЯ ЧАСТЬ
Для достижения поставленной цели была разработана компьютерная программа с помощью среды программирования «Mathlab».
Алгоритм, реализующий эту программу, состоит из следующих последовательных операций:
Определение исходных данных: определение начальной и конечной длин волн, шага длины волны между соседними изображениями, высоты и ширины изображения.
Формирование набора признаков из спектров поглощения.
Кластеризация на основе принципа минимальной длины описания.
Построение карты классов объектов по результатам кластеризации.
Результаты и описание работы компьютерной программы:
В данной работе были использованы следующие гиперспектральные данные:
Гиперспектральный куб окрашенной клетки крови.
Гиперспектральный куб неокрашенной клетки крови.
Гиперспектральный куб неокрашенной сегментоядерной клетки крови.
Гиперспектральный куб окрашенной сегментоядерной клетки крови.
Согласно наиболее распространенной методике определения количественного состава веществ-препаратов, вначале их окрашивают, и количество вещества определяют исходя из того, что чем больше искомого вещества, тем больше препарат окрашивается, поскольку большее количество окрашивающего вещества прореагировало с исследуемым веществом (см.рис. 4, рис. 10)
Ниже (см. рис. 4) представлено выборочное монохромное изображение окрашенной клетки крови из набора кадров, образующих гиперспектральный куб. Результат работы алгоритма сегментации гиперспектрального куба окрашенной клетки крови (см. рис 5), где синим цветом выделены клетки крови, а зеленым межклеточный матрикс.

Рис. 4. Изображение окрашенной клетки крови на длине волны 650 нм

Рис.5. Результат сегментации гиперспектрального куба окрашенной клетки крови
На рис. 6 представлено монохромное изображение неокрашенной клетки крови из набора кадров, образующих гиперспектральный куб и результат работы алгоритма сегментации гиперспектрального куба неокрашенной клетки крови (см. рис 7), где зеленым цветом выделены клетки крови, а синим межклеточный матрикс.

Рис. 6. Изображение неокрашенной клетки крови на длине волны 540 нм

Рис.7. Результат сегментации гиперспектрального куба неокрашенной клетки крови
На рис. 8 представлено монохромное изображение неокрашенной сегментоядерной клетки крови из набора кадров, образующих гиперспектральный куб и результат работы алгоритма сегментации гиперспектрального куба неокрашенной сегментоядерной клетки крови (см. рис 9), где зеленым цветом выделены клетки крови, а синим межклеточный матрикс.

Рис. 8. Изображение неокрашенной сегментоядерной клетки крови на длине волны 580 нм

Рис.9. Результат сегментации неокрашенной сегментоядерной клетки крови
На рис. 10 представлено монохромное изображение окрашенной сегментоядерной клетки крови из набора кадров, образующих гиперспектральный куб и результат работы алгоритма сегментации гиперспектрального куба окрашенной сегментоядерной клетки крови (см. рис 11), где зеленым цветом выделены клетки крови, а синим межклеточный матрикс.

Рис. 10. Изображение окрашенной сегментоядерной клетки крови на длине волны 590 нм

Рис.11. Результат сегментации неокрашенной сегментоядерной клетки крови
Исходя из полученных результатов сегментации, можно установить, что разработанный алгоритм работает корректно не зависимо от типа входящих данных – будь то гиперспектральные данные неокрашенной клетки крови, либо окрашенной сегментоядерной клетки крови.
На рис.12 приведен результат сегментации, выполненной с помощью алгоритма, которой описан в работе [8]. Сравнивая результат, полученный в проведенном исследовании (см. рис.5,7,9,11), с результатами в работе [8] (см. рис.12), можно установить, что разработанный алгоритм является результативным.

Рис.12. Результаты сегментации, показанные в работе [8]
ВЫВОДЫ
В результате выполненной работы был произведен анализ литературных источников по методам получения и обработки гиперспектральных данных для выделения однородных участков изображения, а так же по методам машинного обучения. На основе выводов и результатов выполненного анализа, был сделан выбор в пользу определенного способа получения гиперспектральных данных. Была разработана компьютерная программа для сегментации изображения с использованием гиперспектральных данных в среде программирования «Matlab». Использование методов машинного обучения позволило выполнять анализ гиперспектральные данный полностью автоматически. Сравнив полученные результаты работы разработанной программы с результатами, опубликованными в работе [8] , можно утверждать, что разработанный алгоритм корректен и эффективен.
ПРИЛОЖЕНИЕ
Функция, реализующая алгоритм сегментации изображения клеток крови с использованием гиперспектральных данных:
clc
clear
dirpath = 'HS_Data\s_painted\';
fstWavelength = 420;
lstWavelength = 800;
wavelengthStep = 10;
filenamePostfix = 'nm.bmp';
% не забудь выставить размеры картинок
height = 256;
width = 342;
picsNumber = (lstWavelength - fstWavelength) / wavelengthStep;
hsImages = zeros(picsNumber, height, width);
for i = 1 : picsNumber
wavelength = fstWavelength + (i - 1) * wavelengthStep;
filename = [dirpath num2str(wavelength) filenamePostfix];
img = imread(filename);
if size(img, 3) ~= 1
img = rgb2gray(img);
end;
hsImages(i, :, :) = double(img);
end;
hsFeatures = zeros(height * width, picsNumber);
for i = 1 : height
for j = 1 : width
fIndex = (i - 1) * width + j;
hsFeatures(fIndex, :) = hsImages(:, i, j);
end;
end;
minCNumber = 2;
maxCNumber = 10;
[indices, ~] = mdl_kMeans(hsFeatures, minCNumber, maxCNumber);
segmented = zeros(height, width);
for i = 1 : height
for j = 1 : width
fIndex = (i - 1) * width + j;
segmented(i, j) = indices(fIndex);
end;
end;
figure
title('Segmented image', 'FontSize', 14);
pcolor(segmented);
shading flat
Алгоритм k внутригрупповых средних с выбором числа кластеров согласно принципу минимальной длины описания:
% Аргументы:
% features - массив векторов признаков
% fstK – минимальное число кластеров
% lstK - максимальное число кластеров
% Результат:
% rIndices - массив, который содержит индексы кластеров
% которым были присовены исходные данные
% rClusters – массив эталонных векторов признаков
% для каждого кластера
function[rIndices, rClusters] = mdl_kMeans(features, fstK, lstK)
% M – количество векторов в обучающей выборке
% N – размерность вектора признаков
[M, N] = size(features);
maxIter = 1000;
minimumDescriptionLength = inf;
rIndices = [];
rClusters = [];
for k = fstK : lstK
[indices, clusters] = kmeans(features, k, 'MaxIter', maxIter);
modelLength = (N*k/2) * log2(M) + log2(k);
dataLength = 0;
for i = 1 : M
diffVec = features(i, :) - clusters(indices(i));
distance = diffVec * diffVec';
dataLength = dataLength + log2(distance) + log2(k);
end;
descriptionLength = modelLength + dataLength;
if descriptionLength < minimumDescriptionLength
minimumDescriptionLength = descriptionLength;
rIndices = indices;
rClusters = clusters;
end;
end;
end