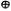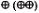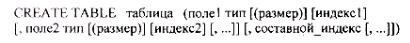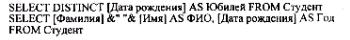С помощью полноэкранных команд, вызываемых через главное меню (Управляющий центр, режим Assist и т.п.), осуществляются создание и редактирование схемы реляционной таблицы (файла), ввод и редактирование данных. Для реализации тех же действий на программном уровне имеются соответствующие команды языка (CREATE, MODIFY, UPDATE, DELETE и др.).
Работа с реляционной таблицей (файлом базы данных) организуется в отдельной рабочем области, которой присваивается имя (алиасное имя или номер). После активизации файла к нему можно перейти, указав номер рабочей области. СУБД запоминает указатель на последней обрабатываемой записи (при первоначальном открытии файла текущий номер записи – 1). Позиционирование в файле на запись выполняется:
непосредственно, указанием номера записи (начало или конец файла, определенный номер записи); при поиске записи по заданному логическому условию.
Язык обеспечивает выполнение всех рассмотренных типовых операций над отдельным файлом, а именно:
DELETE – удаление записей (в программном режиме); SEEK, FIND, LOCATE – поиск записи по условию;
COPY – копирование всех или части записей активного файла в новый файл; CONTINUE - продолжение поиска записи по ранее сформулированному условию и т.п. Границы области действия команды принимают значения:
RECORD n – определенная запись с номером n; ALL – все записи файла;
NEXT n – следующие n записей, начиная с текущей; REST – все записи, начиная с текущей и до конца файла.
Условия выполнения команд задаются с помощью формата ключевых слов FOR и WHILE.
Условие1 действует в качестве фильтра (ВЫБОРКА) записей исходного файла: если записи соответствуют условию, они участвуют в операции. Условие формулируется применительно к полям записи, например:
Условие2 позволяет прекратить операцию в случае его нарушения, например: WHILE [Дата рождения] < 1.1.80
Многие команды включают список полей, указываемых за ключевым словом FIELDS, на которые распространяется действие операции.
Пример 19.52.
DELETE границы FOR условие1 WHILE условие2
Операция логического удаления (пометки) записей активного файла, если они отвечают требованию условия1. Операция выполняется до тех пор, пока истинно
условие2.
COPY TO нов_файл границы FIELDS список_полей FOR условие1 WHILE ycловие2
Записи активного файла, удовлетворяющие условию1, если истинно условие2, используются для формирования нового файла, схема которого задается как
список_полей.
Таким образом, можно выполнить как горизонтальную, так и вертикальную выборку записей реляционной базы данных.
Совместная обработка файлов выполняется лишь для двух файлов: при этом файлы должны быть предварительно открыты в разных рабочих областях, иметь совпадающие внешние ключи.
Пример 19.53.
611
JOIN WITH псевдоним FOR условие FIELDS список_полей
Запись исходного файла объединяется с записью файла, открытого под именем псевдоним, если выполняется условие. Формируется новый файл, схема которого задается списком полей.
Для одновременной работы более чем с двумя файлами используются переменные, в которых сохраняются значения полей в качестве внешнего ключа связи.
Кроме того, данный класс реляционных языков реализует типовые конструкции языков структурного программирования:
циклы (DO WHILE .... END DO);
условные операторы (IF ... ELSE ... ENDIF);
альтернативные операторы (DO CASE ... OTHERWISE ...ENDCASE) и др.
Реляционные dBASE-подобные языки занимают промежуточное положение между языками манипулирования данными СУБД и языками программирования, обладают выраженной процедурностью обработки, когда явно указывается последовательность действий, приводящих к конечному результату.
Графические (схематичные) реляционные языки
Типичным представителем является язык QBE (Query By Example), реализованный в среде электронных таблиц, в ряде СУБД, в пакете Microsoft Query.
Данный язык относится к языкам манипулирования данными. Работа выполняется со схемой реляционной таблицы с использованием простейших синтаксических конструкций.
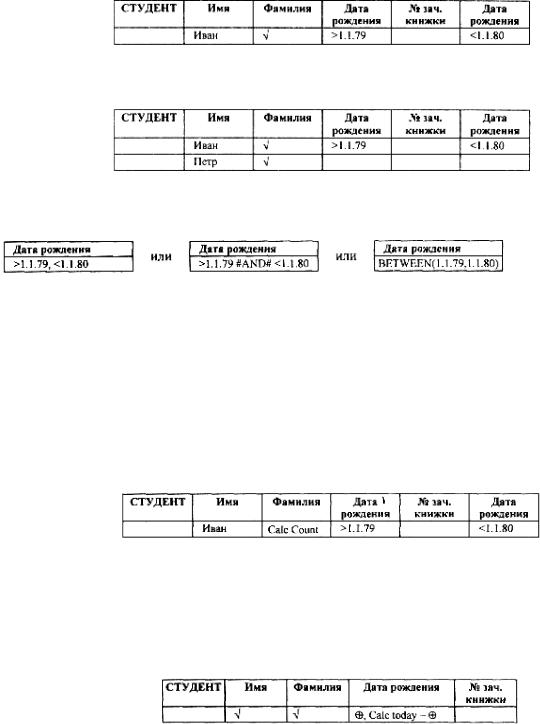
Для вертикальной выборки (проекции) записей реляционной таблицы осуществляется пометка отбираемых полей с помощью символа √ (помеченное поле выводится в выходную структуру новой реляционной таблицы).
Для горизонтальной выборки (селекции) задаются логические условия (критерии) отбора записей в поисковых полях.
Условия могут задаваться как выражения, построенные с помощью операторов различного вида: Арифметические операторы – используются для выполнения вычислений с числами в качестве
констант выражения:
* Умножения двух чисел + Сложения двух чисел
- Вычитания одного числа из другого / Деления одного числа на другое
Операторы сравнения – используются для сравнения двух значений: > (больше)
>= (больше или равно) < (меньше)
<= (меньше или равно) <> (не равно)
= (равно).
Логические операторы – используются с выражениями, которые могут быть истинными или ложными:
И (AND) – должны выполняться оба критерия. Или (OR) – должен выполняться один из критериев. Не (NOT) – этот критерий не должен выполняться.
Могут использоваться специальные операторы типа:
612
BETWEEN – значение в заданном диапазоне. IN – одно из значений списка.
IS – с ключевым словом Null определяет, является ли величина нулем (нет значения) или нет (есть значение).
LIKE – использует символы подстановки для сравнения двух значений. Условия задаются в следующих вариантах:
для одного поля;
водной строке для нескольких полей, считая все условия совместными;
вразных строках для одного или разных полей, считая их альтернативными.
Пример 19.55. Для получения фамилий студентов с именем Иван и датой рождения в диапазоне 1.1.79 –1.1.80создается запрос:
Для получения фамилий студентов с именем Иван с датой рождения в диапазоне 1.1.79-
1.1.80и фамилий студентов с именем Петр создается запрос:
Внекоторых реализациях языка QBE условие на значение диапазона дат может записываться в ином виде:
Язык QBE позволяет вычислять групповые функции (по группе выделенных строк) с помощью функций:
Avg – среднее арифметическое значение поля; Count – число выбранных записей;
Мах – максимальное значение поля; Min – минимальное значение поля; Sum – сумма значений поля.
Для использования подобных функций указываются поля, образующие группу записей.
Пример 19.56. Для подсчета количества студентов с именем Иван и датой рождения в диапазоне 1.1.79 – 1.1.80 создается запрос:
Ключевое слово Сalс означает вычисление значений по данному полю.
Выражения используются в запросе и для формирования новых данных.
Пример 19.57. Для каждого студента определить количество прожитых на сегодняшнюю дату дней:
613
Символ – идентификатор значения поля, today – встроенная функция вычисления сегодняшней даты.
Для совместной обработки реляционных таблиц строится многотабличный запрос, в котором указываются внешние ключи связи, помечаемые в бланках запроса.
Пример 19.58. Получить сведения о студентах, успевающих на 4 и 5, название дисциплины и результат сдачи экзамена (оценку):
Символы – идентификаторы ключей связи в различных реляционных таблицах. Выходная структура содержит поля: имя, фамилия, результат, название дисциплины. Выводятся сведения о студентах, которые учатся на 4 и 5.
Некоторые версии языка QBE позволяют создать набор (множество) значений указанного поля одной таблицы, по отношению к которому проверяются значения поля другой таблицы. Операции сравнения выполняются на уровне множества значений поля с помощью сравнения наборов:
ONLY – второй набор – подмножество первого, NO – наборы не совпадают,
EVERY – первый набор – подмножество второго, EXACTLY – наборы совпадают.
Первый набор формируется с помощью ключевого слова SET.
Пример 19.59. Получить сведения о студентах, которые имеют такие же результаты, что и студент с зачетной книжкой 123456
В ряде СУБД кроме выборки записей возможны операции включения новых записей (INSERT), удаления записей (DELETE) или групповой корректировки выбранных записей (CHANGETO).
ОСНОВНЫЕ ХАРАКТЕРИСТИКИ ЯЗЫКА SQL
Краткая характеристика языка SQL
SQL (Structured Query Language) – это язык программирования, который используется при работе с реляционными базами данных в современных СУБД (ORACLE, dBASE IY, dBASE Y, Paradox, Access и
др.).
Язык SQL стал стандартом языков запросов для работы с реляционными базами данных для архитектуры как файл-сервер,так и клиент-сервер,а также в условиях применения системы управления распределенными базами данных. SQL использует ограниченный набор команд, но в то же время – это реляционно полный язык, предназначенный для работы с базами данных, создания запросов выборки
614
данных, выполнения вычислений, обеспечения их целостности. Синтаксис версий языка SQL может в определенной степени различаться для отдельных СУБД. Рассмотрим наиболее общие операторы языка
SQL.
Операторы языка SQL для работы с реляционной базой данных
1. Создание реляционных таблиц. Создание реляционной базы данных означает спецификацию состава полей: указание имени, типа и длины каждого поля (если это необходимо). Каждая таблица имеет уникальное имя.
Синтаксис оператора создания новой таблицы:
где таблица
- имя создаваемой таблицы;
поле1, поле2
- имена полей таблицы;
тип
– тип поля;
размер
– размер текстового поля;
индекс1, индекс2 - директивы создания простых индексов (по отдельному полю); составной_индекс – директива создания составного индекса.
Каждый индекс имеет уникальное в пределах данной таблицы имя.
Для создания простого индекса используется фраза (помещается за именем поля):
CONSTRAINT имя_индекса {PRIMARY KEY | UNIQUE |
REFERENCES внешняя_таблица [(внешнее поле)]}
Директива создания составного индекса (помещается в любом месте после определения его элементов):
Будет создана таблица СТУДЕНТ, в составе которой: два текстовых поля: Имя, Фамилия, одно поле типа дата/время – Дата рождения.
Создан составной индекс с именем Адр по значениям указанных полей, индекс имеет уникальное значение, в таблице не может быть двух записей с одинаковыми значениями полей, образующих индекс.
2. Изменение структуры таблиц. При необходимости можно выполнить реструктуризацию
615
таблицы:
удалить существующие поля, добавить новые поля, создать или удалить индексы.
Все указанные действия затрагивают одновременно только одно поле или один индекс:
ALTER TABLE таблица
ADD {[COLUMN] поле тип[(размер)} [CONSTRAINT индекс]|
CONSTRAINT составной_индекс}
DROP {[COLUMN] поле i CONSTRAINT имя_индекса} }
Опция ADD обеспечивает добавление поля, опция DROP – удаление поля таблицы, добавление опции CONSTRAINT означает подобные действия для индексов таблицы.
Пример 19.61.
ALTER TABLE Студент ADD COLUMN [Группа] ТЕХТ(5)
Для создания нового индекса для существующей таблицы можно использовать также команду:
CREATE [ UNIQUE ] INDEX индекс
ON таблица (поле[,...])
[WITH { PRIMARY | DISALLOW NULL | IGNORE NULL }]
Фраза WITH обеспечивает наложение условий на значения полей, включенных в индекс: DISALLOW NULL – запретить пустые значения в индексированных полях новых записей; IGNORE NULL – включать в индекс записи, имеющие пустые значения в индексированных полях.
Пример 19.62.
CREATE INDEX Гр ON Студент ([Группа]) WITH DISALLOW NULL
3. Удаление таблицы. Для удаления таблицы (одновременно и структуры, и данных) используется команда:
DROP TABLE имя_таблицы
Для удаления только индекса таблицы (сами данные не разрушаются) выполняется команда:
DROP INDEX имя_индекса ON имя_таблицы
Пример 19.63.
DROP INDEX Адр ON Студент
–удален только индекс Адр
DROP TABLE Студент
–удалена вся таблица
4.Ввод данных в таблицу. Формирование новой записи в таблице выполняется командой:
INSERT INTO таблица_куда [(поле1[, поле2[,...]])]
VALUES (значение1[, значение2[,...]);
Указывается имя таблицы, в которую добавляют запись, состав полей, для которых вводятся значения.
Возможен групповой ввод записей (пакетный режим), являющихся результатом выборки (запроса) из других таблиц:
INSERT INTO таблица_куда [IN внешняя_база_данных]
SELECT [источник.]поле![, поле2[,...]
FROM выражение
WHERE условие
Перед загрузкой выполняется оператор подзапроса SELECT, который и формирует выборку для добавления. Фраза SELECT определяет структуру данных источника передаваемых записей - имена таблицы и полей, содержащих исходные данные для загрузки в таблицу_куда FROM позволяет указать имена исходных таблиц, участвующих в формировании выборки, а фраза WHERE – задает условия выполнения подзапроса. Структура данных выборки должна соответствовать структуре данных таблицы, в которую производится добавление.
Добавление (перезагрузка) записей возможна и во внешнюю базу данных, для которой указывается полностью специфицированное имя (диск, каталог, имя, расширение).
Пример 19.65.
INSERT INTO Студент SELECT [Студент-заочник].* FROM [Студент- заочник]
Все записи таблицы [Студент-заочник]в полном составе полей будут добавлены в таблицу Студент.
Примечание. Структуры таблиц должны совпадать.
Пример 19.66.
INSERT INTO Студент SELECT [Студент-заочник].* FROM [Студент-
заочник] WHERE [Дата рождения] >= #01/01/80#
Записи таблицы [Студент-заочник]добавляются в таблицу Студент, если дата рождения студента больше или равна указанной.
5. Операции соединения таблиц. Операцию INNER JOIN можно использовать в любом предложении FROM. Она создает симметричное объединение, наиболее частую разновидность внутреннего объединения: записи из двух таблиц объединяются, если связующие поля этих таблиц содержат одинаковые значения:
FROM таблица1 INNER JOIN таблица2 ON таблица1.поле1 = таблица2.поле2
Данный оператор описывает симметричное соединение двух таблиц по ключам связи (noлe1; поле2). Новая запись формируется в том случае, если в таблицах содержатся одинаковые значения ключей связи.
Возможные варианты операции:
LEFT JOIN (левостороннее) соединение – выбираются все записи "левой" таблицы и только те записи "правой" таблицы, которые содержат соответствующие ключи связи;
RIGHT JOIN (правостороннее) соединение – выбираются все записи "правой" таблицы и только те записи "левой" таблицы, которые содержат соответствующие ключи связи.
Пример 19.67.
SELECT Студент.*, Оценка.* FROM Студенты INNER JOIN Оценка ON Студент.[№ зач.книжки] = Оценка.[№ зач.книжки];
SELECT Студент.*, Оценка.* FROM Студенты LEFT JOIN Оценка
ON Студент. [№ зач.книжки] = Оценка. [№ зач.книжки];
SELECT Студент.*, Оценка.* FROM Студенты RIGHT JOIN Оценка ON Студент. [№ зач.книжки] = Оценка. [№ зач.книжки];
617
В первом случае создается симметричное соединение двух таблиц по полю [№ зач.книжки]. Не выводятся записи, если значение их ключей связи (указанное поле) не представлено в двух таблицах. Во
втором случае будут выведены все записи таблицы СТУДЕНТ и соответствующие им записи таблицы ОЦЕНКА. В третьем случае – наоборот, все записи таблицы ОЦЕНКА и соответствующие им записи таблицы СТУДЕНТ.
Операции JOIN могут быть вложенными для последовательного соединения нескольких таблиц.
( Дисциплина ON Оценка. [Код дисциплины] = Дисциплина. [Код дисциплины])
ON Студент.[№ зач.книжки]=Оценка. [№ зач.книжки])
Сначала происходит соединение таблиц ОЦЕНКА и ДИСЦИПЛИНА по ключу связи [Код дисциплины]. Соединение симметричное, то есть если коды дисциплины не совпадают, записи этих таблиц не соединяются. Затем происходит соединение таблиц СТУДЕНТ и ОЦЕНКА по ключу связи [№ зач.книжки].
Таким образом, на выходе запроса – результат соединения трех таблиц, но при условии совпадения ключей связи.
6. Удаление записей в таблице. В исходной таблице можно удалять отдельные или все записи, сохраняя при этом структуру и индексы таблицы. При удалении записей в индексированной таблице автоматически корректируются ее индексы:
DELETE [таблица.*] FROM выражение WHERE условия_отбора
Полная чистка таблицы от записей и очистка индексов выполняется операцией:
DELETE * FROM таблица
Пример 19.69.
DELETE * FROM Студент
Все ранее загруженные записи будут удалены.
DELETE * FROM Студент WHERE [Дата рождения]>#1.1.81#
Удаляются только те записи, в которых поле [Дата рождения] больше указанной даты.
Данная операция удаляет записи в таблице, связанные с другой таблицей: условия удаления записей могут относиться к полям связанных таблиц:
DELETE таблица.* FROM таблица INNER JOIN др._таблица
ON таблица, [полеN = др._таблица.[полеМ] WHERE условие
Пример 19.70.
DELETE Студент.* From Студент INner JoIN [Студент заочник]
ON Студент.[Группа]= [Студент заочник]. [Группа]
Удаляются записи в таблице Студент, для которых имеются связанные записи в таблице [Студент заочник].
Примечание. Средствами Microsoft ACCESS невозможно восстановить записи, удаленные с помощью запроса на удаление записей.
618
7. Обновление (замена) значений полей записи. Можно изменить значения нескольких полей одной или группы записей таблицы, удовлетворяющих условиям отбора:
UPDATE таблица SET новое_значение WHERE условия_отбора
новое_значение указывается как имя_поля=новое значение
Пример 19.71.
UPDATE Студент SET [Группа] = "1212"
WHERE [Фамилия] LIKE 'В*' AND [Дата рождения] < = #01/01/81#
Студентов, чьи фамилии начинаются на букву В и дата рождения не превышает указанной, перевести в группу 1212.
UPDATE Студент INner JoIN [Студент заочник] ON Студент. [Группа]= [Студент заочник]. [Группа] SET [Группа]= [Группа]&"а"
В таблице Студент изменить номера групп, если они встречаются в таблице [Студент заочник], добавив букву а.
ОРГАНИЗАЦИЯ ЗАПРОСОВ К БАЗЕ ДАННЫХ НА ЯЗЫКЕ SQL
Синтаксис оператора SELECT
Выборка с помощью оператора SELECT - наиболее частая команда при работе с реляционной базой данных. Этот оператор обладает большими возможностями по заданию структуры выходной информации, указанию источников входной информации, способа упорядочения выходной информации, формированию новых значений и т.п. (табл. 19.9).
Таблица 19.9. Аргументы оператора SELECT
Аргумент
Назначение
Предикат
Предикаты используются для ограничения числа возвращаемых записей:
ALL – все записи;
DISTINCT – записи, различающиеся в указанных для вывода полях;
DISTINCTROW – полностью различающиеся записи по всем полям; ТОР –
возврат заданного числа или процента записей в диапазоне,
соответствующем фразе ORDER BY
Таблица
Имя таблицы, поля которой формируют выходные данные
Поле1, поле2
Имена полей, используемых
при
отборе
(порядок их
следования
определяет выходную структуру выборки данных)
Псевдоним1,
Новые заголовки столбцов результата выборки данных
Псевдоним2
FROM
Определяет
выражение,
используемое
для
задания
источника
формирования выборки (обязательно присутствует в каждом операторе)
Внешняя база данных
Имя внешней базы данных – источника данных для выборки
[WHERE... ]
Определяет условия отбора записей (необязательное)
[GROUP BY... ]
Указание полей (максимум – 10) для формирования групп, по которым
возможно вычисление групповых итогов; порядок их следования
определяет виды итогов (старший, промежуточный и т.п.) –
необязательное
[HAVING... ]
Определяет условия отбора записей для сгруппированных данных (задан
способ группирования GROUP BY...) – необязательное
[ORDER BY... ]
Определяет
поля,
по которым
выполняется упорядочение
выходных
записей; порядок
их следования
соответствует
старшинству ключей
сортировки. Упорядочение возможно как по возрастанию (ASC), так и по
619
убыванию (DESC) значения выбранного поля
[WITH
OWNERACCESS
При работе в сети в составе защищенной рабочей группы для указания
OPTION]
пользователям, не обладающим достаточными правами, возможности
просматривать результат Запроса или выполнять запрос
При выполнении выборки могут формироваться и новые данные, так называемые вычисляемые поля, являющиеся результатом обработки исходных данных. Возможно упорядочение выводимых данных, формирование групп записей, подсчет групповых итогов, формирование подмножеств данных (записей), являющихся основой для формирования условий по обработке следующего этапа – вложенных запросов.
Универсальный оператор SELECT имеет следующую конструкцию:
Синтаксис оператора SELECT весьма лаконично реализует сложные алгоритмы запросов. Практическое освоение элементов постепенное – методом от простого к сложному, а отладка оператора сложной конструкции может идти по частям.
Изучать оператор SELECT лучше всего на конкретных примерах. Слово SELECT определяет структуру выводимой информации, это могут быть поля таблиц, вычисляемые выражения.
Вычисляемое выражение состоит из: полей таблиц; констант; знаков операций;
встроенных функций; групповых функций SQL.
Пример 19.72.
SELECT [Имя], [Фамилия] FROM Студент
SELECT TOP 5 [Фамилия] FROM Студент
SELECT TOP 5 [Фамилия] FROM Студент ORDER BY [Группа]
В первом случае выбираются все записи таблицы Студент в составе указанных полей. Если отбираются все поля в том же самом порядке, что и в структуре таблицы, можно указать символ точки. Во втором случае отбирается 5 первых фамилий студентов, в третьем случае - выбирается 5 первых фамилий студентов, упорядочение записей осуществлено по учебным группам.
Если используются одноименные поля из нескольких таблиц, включенных в предложение FROM, следует указать перед именем такого поля имя таблицы через . (точку): [Студент заочник].[Группа] и [Студент].[Группа] – два одноименных поля из разных таблиц.
Для изменения заголовка столбца с результатами выборки используется служебное слово AS.
Пример 19.73.
В первом случае будут выведены неповторяющиеся даты рождения студентов, которые имеют новое наименование – Юбилей. Во втором случае в результирующей таблице присутствуют все записи, но вместо [Дата рождения] указан Год и вместо Фамилия и Имя, соединенных вместе через пробел, –