

24. Применение конвейеров в современных процессорах (вычислительный конвейер и его стадии, fpu)
В современных микропроцессорах широко используются арифметические конвейеры. Функциональные узлы, реализующие операции с плавающей запятой, все конвейеризованы. Распределение процедур между ФБ ступеней конвейеров соответствует естественной последовательности фаз в алгоритмах выполнения операций.
Структура линейного синхронного конвейера сложения (вычитания) с плавающей запятой:

ПЭ – подготовительный этап (распаковка чисел с ПЗ на знак, порядок и мантиссу; проверка на нуль всех разрядов порядка по IEEE754 как признак равенства нулю операнда).
ВП – выравнивание порядков (сдвиг мантиссы числа с меньшим порядком вправо).
СМТ – суммирование мантисс, определение знака результата.
ПП – проверка переполнения поля порядка результат.
ЗЭ – заключительный этап (нормализация мантиссы результата сдвигом и проверка потери значимости мантиссы или порядка).
Структура линейного конвейера умножения с плавающей запятой

ПЭ – подготовительный этап (распаковка чисел с ПЗ на знак, порядок и мантиссу; проверка на равенство нулю сомножителей).
СПР – сложение порядков (для смещенных порядков вычитание величины смещения).
ППП – проверка переполнения порядка и потери значимости.
УМТ – умножение мантисс как чисел с фиксированной запятой (округление до длины поля мантиссы).
ЗЭ – заключительный этап (нормализация мантиссы результата, проверка переполнения порядка и потери значимости).
Подвергаются конвейеризации также функциональные узлы целочисленного умножения и деления. В современных микропроцессорах эти операции выполняются в однотактных (одношаговых) узлах сверхпараллельной аппаратной избыточной арифметики. Широко применяются матричные умножители и делители, построенные на матричном массиве одноразрядных сумматоров, соединенных цепями переносов и имитирующих процедуру умножения в столбик. К сожалению, в большинстве вариантов матричных умножителей (делителей) требуется большая глубина массива сумматоров (число строк матрицы). Так как матричный умножитель – это многослойная комбинационная схема, задержка ее сравнительно велика. Из-за этого приходится увеличивать длительность такта между соседними парами входных сомножителей, что приводит к снижению производительности. Если схему умножителя разрезать на несколько слоев и между слоями поместить буферные регистры, то образуется многоступенчатый конвейер, который при параллелизме данных (длинном потоке пар сомножителей) позволит уменьшить такт между соседними их парами, так как он станет конвейерным. Последний, как известно, при этом выбирается по формуле
Tk
‘ = max {Tci}<
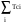 ,
где Тсi – задержка i-го
слоя комбинационной схемы матричного
умножителя.
,
где Тсi – задержка i-го
слоя комбинационной схемы матричного
умножителя.
Конечно, в конвейерном такте нужно учесть еще и задержку буферных регистров:
Тк = Тк’ + Тбр = Тсmax + Тбр.
Однако при числе ступеней в конвейерном умножителе, равном К, сомножители могут подаваться на вход с интервалом в К раз меньшим, чем в случае отсутствия конвейеризации. Настолько же повысится темп появления результатов на выходе.
Схема конвейеризованного матричного умножителя Брауна для четырехразрядных сомножителей
a3 a2 a1 a0
b0
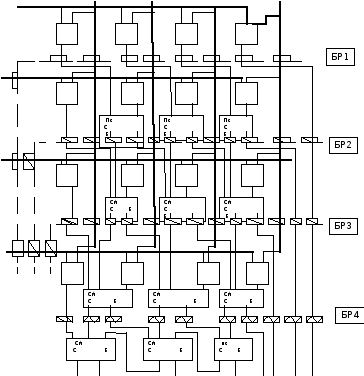
b1
b2
b3
P7 P6 P5 P4 P3 P2 P1 P0
ПС – полусумматор, имеющий два входа для слагаемых (используется в младших разрядах, где перенос С-1 = 0).
СМ – полный сумматор, имеющий все необходимые три входа, в том числе для единицы переноса из соседнего младшего разряда.





- условные обозначения триггеров – защелок соответственно первого, второго, третьего и четвертого буферных регистров (БР) между соседними ступенями конвейера. Так как ступени представляют собой параллельно включенные комбинационные схемы с разными величинами задержек по разным входам, для синхронизации и продвижения результатов предыдущих ступеней в следующие без потерь и гонок целесообразно применить БР с двойной памятью, где каждый разряд «триггер - защелка» - это два последовательно соединенных триггера, управляемых по записи и перезаписи одним синхроимпульсом. Вначале по переднему фронту импульса стробируется запись в первый триггер результатов логической обработки на предыдущей ступени, где обработка началась по заднему фронту предыдущего синхроимпульса. Затем по заднему фронту импульса содержимое первого триггера переписывается во второй на вход следующей ступени, где начинается логическая обработка. Тем самым исключаются гонки между логическими цепями разной длины в каждой из ступеней конвейера.
Заметим, что такой конвейерный умножитель можно применить в качестве функционального блока на пятой ступени описанного выше конвейерного умножителя с плавающей запятой. Это позволит удлинить последний на число ступеней этого конвейера и выровнять времена обработки Tci во всех образовавшихся ступенях умножителя с плавающей запятой. При реальной длине разрядной сетки сомножителей, равной n=32; 64 разряда, расходы оборудования на буферные регистры очень усложняют схему. Тогда идут на компромисс, и число ступеней конвейера уменьшают вдвое – втрое по сравнению с разрядностью.
С целью дальнейшего повышения производительности в операционной части процессора может применяться множество параллельных конвейеров, обрабатывающих как согласные, так и встречные, и ортогональные потоки данных. Процессор, построенный на параллельных синхронных конвейерах, называется систолическим, а на параллельных асинхронных конвейерах – волновым.
25. Классификация параллельных вычислительных систем (Флинн)
Простейший и наиболее широко используемый способ- это макроклассификация ВС, введенная американским ученым Флинном. Различные способы организации ВС подразделяются по числу потоков команд и потоков данных:
1. Системы с одиночным потоком команд и одиночным потоком данных (ОКОD - SISD). Сюда относятся однопроцессорные ЭВМ.
2. Системы с множественным потоком команд и одиночным потоком данных (MKOD - MISD). Сюда относятся ВС с программируемыми конвейерами процессоров.
3. Системы с одиночным потоком команд и множественным потоком данных (OKMD - SIMD). Сюда относятся векторно - конвейерные супер - ЭВМ, матричные ВС с общим управлением, ассоциативные однородные вычислительные среды.
4. Системы с множественным потоком команд и множественным потоком данных (MKMD - MIMD). Это наиболее представительный класс, включающий фон Неймановские ММВК, МПВК, МПВС, ФРВС, ГлВС и ЛВС, транспьютерные сети, кластерные ВС, а также не фон Неймановские потоковые и редукционные ВС.
26. Понятие и типы вычислительных зависимостей (RAW, RAR, WAW, WAR)
Левый сайт
Все виды зависимостей по данным могут быть классифицированы по типу ассоциаций: RAR — “чтение после чтения”, WAR — “запись после чтения” и WAW — “запись после записи”, RAW — “чтение после записи”.
RAR, по сути дела, соответствует отсутствию зависимостей, поскольку в данном случае порядок выполнения команд не имеет значения. Действительной зависимостью является только “чтение после записи” (RAW), так как необходимо прочитать предварительно записанные новые данные, а не старые.
Лишние зависимости по данным появляются в результате “записи после чтения” (WAR) и “записи после записи” (WAW).
После удаления лишних зависимостей по управлению и данным команды могут исполняться параллельно. Формирование расписания параллельного выполнения команд возлагается на аппаратные средства микропроцессора. Это расписание учитывает существующие зависимости между командами и имеющиеся функциональные модули процессора.