

otvety / 22-28 21-26
.pdf1 вопрос
22. Асинхронные линейные вычислительные конвейеры Фото 22 Ватутин Типикин:
Структура асинхронного конвейера
|
|
|
|
Sk |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Орj Ор,,j+1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
Tk |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Tk |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Кв. |
|
|
|
|
|
|
|
|
|
ФБ1 |
|
|
|
|
|
|
|
|
ФБ2 |
|
|
|
|
|
ФБк |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Тс1 |
Тс2 |
Тск |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
l2 |
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
очередь |
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∑ Tc |
|
|
|
|
|
|
|
|
||
Несколько уменьшается время загрузки Тнз = i = 1 |
i< КТсмах. Синхронизация применяется |
||||||||||||||||||||||||
только на входе. Операнды загружаются в конвейер периодически с конвейерным тактом, задаваемым стробами приема во входной регистр ФБ1.
Подобрана следующая эмпирическая формула для оценки требуемого конвейерного такта:
Тка ³ max {min {Tci}, {Tci/li}}, |
(3) |
где из второго множества исключается элемент по Tj=min {Tci}, так как на входе ФБj сразу целесообразно выбрать минимальную длину очереди lj = 1. Отсюда следует, что длины очередей li имеет смысл увеличивать только до тех пор, когда все элементы второго множества станут меньше, чем tj:
Tci/li<tj=min{Tci}, i=1,k , i¹j.
После этого их увеличение уже не приводит к уменьшению Тка и повышению пропускной способности, так как они будут определяться самыми быстрыми из ФБ. Следовательно, если оптимально подобрать длины очередей, то пропускная способность асинхронного конвейера будет определяться самыми быстрыми из ФБ, а не самыми медленными, как это наблюдается в синхронных конвейерах. На основании формулы (3) показано, что спектр требуемых длин очередей целесообразно выбирать по формулам:
li³ Tci/Tk, i¹j, i=1,k ,
где j=arg min {Tci}, a lj=1;
Тк – требуемое значение конвейерного такта, которое должно подчиняться неравенству:
Tk ³ ti = min {Tci}.
23. Нелинейные вычислительные конвейеры (принципы организации, конфликты за доступ к функциональным блокам, статическое и динамическое планирование запуска)
Фото 23 Ватутин не все Типикин: Нелинейные конвейеры
Линейные конвейеры ускоряют обработку линейных ветвей программ при большой степени параллелизма данных. Чаще всего на линейных участках программируется вычисление одной
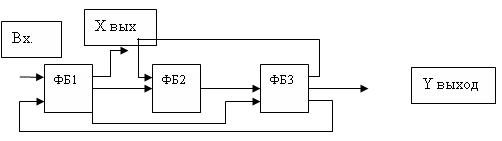
функции. В тоже время в наследуемых последовательных программах, подлежащих распараллеливанию при обработке на современных суперскалярных процессорах, до их появления применялось совмещение на линейных участках последовательного вычисления нескольких функций от аргументов, найденных ранее. В суперскалярных и многопроцессорных системах вычисления на таких участках распараллеливаются на несколько функциональных блоков или процессоров. Однако при высокой степени параллелизма аргументов ускорение обработки возможно и с меньшими затратами аппаратных средств, если совместить параллельно - последовательное вычисление нескольких функций в одном многофункциональном конвейере с использованием одних и тех же его функциональных блоков в режиме разделения времени для выполнения разных этапов формирования разных функций. В этом случае линейная последовательная цепь ФБ не подходит и приходится применять пропуски некоторых ФБ обходными линиями связи и цепи с обратными связями. Такие многофункциональные конвейеры называются нелинейными.
Структура нелинейного конвейера с совмещением вычисления двух функций Х и У.
Для разрешения конфликтов между функциями за владение одним и тем же ФБ и исключения гонок необходимо синтез структуры конвейера (распределение операций между ФБ и проведение связей между ФБ) одновременно верифицировать по таблицам последовательного использования ФБ в процессе вычисления функций, а далее – по временным диаграммам. Например, в приведенной выше структуре конфликты удастся исключить, если таблицы использования ФБ будут следующими
NTk |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|||||||||||||||
ФБ1 |
x . |
|
, |
|
х |
. |
х |
|
у . |
|
, |
у . |
|||
ФБ2 |
|
х |
. |
х |
. , |
|
, |
|
|
|
|
у |
. |
|
, |
ФБ3 |
|
|
х |
. |
х |
. , |
х |
. , |
|
|
у . |
у |
. , |
у |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NTk – номер конвейерного такта в процедуре вычисления функции.
Если не совмещать вычисление двух функций, то запуск очередного конвейерного вычисления функции Х на новом наборе аргументов можно было бы выполнять или на 2-ом (обозначено точками), или на 4-м (обозначено запятыми), или на 7-ом такте; а функции У-или на 2-ом, или на 4- ом такте, или 6-ом такте, или позже. Запуск совместного параллельного с Х вычисления функции У можно было бы начинать или на 3-ем, или на 5-ом такте. Однако следующий конвейерный запуск совместного вычисления функций Х и У на новых наборах их входных аргументов можно выполнять только на каждом 7-ом такте от их начальных запусков. Иначе возникают конфликты между ними за владение одними и теми же ФБ. Например, совместный начальный запуск можно выполнять так: Х – на 1-ом такте, У – на 5-ом такте, а далее выполнять их конвейерные запуски в следующей последовательности: Х – на 7-ом, 13-ом, 19-ом, и т.д. тактах; У – на 11-ом, 17-ом, 23-ем и т.д. тактах. Следовательно, минимальный конвейерный такт в данном нелинейном конвейере приходится увеличивать в 6 раз по сравнению с линейным. На это можно пойти при высоком быстродействии элементной базы с целью снижения аппаратной сложности.
2
24. Применение конвейеров в современных процессорах (вычислительный конвейер и его стадии, FPU)
В современных микропроцессорах широко используются арифметические конвейеры. Функциональные узлы, реализующие операции с плавающей запятой, все конвейеризованы. Распределение процедур между ФБ ступеней конвейеров соответствует естественной последовательности фаз в алгоритмах выполнения операций.
Структура линейного синхронного конвейера сложения (вычитания) с плавающей запятой:
ПЭ |
|
ВП |
|
смт |
|
ПП |
|
зэ |
|
|
|
|
|
|
|
|
|
ПЭ – подготовительный этап (распаковка чисел с ПЗ на знак, порядок и мантиссу; проверка на нуль всех разрядов порядка по IEEE754 как признак равенства нулю операнда).
ВП – выравнивание порядков (сдвиг мантиссы числа с меньшим порядком вправо). СМТ – суммирование мантисс, определение знака результата.
ПП – проверка переполнения поля порядка результат.
ЗЭ – заключительный этап (нормализация мантиссы результата сдвигом и проверка потери значимости мантиссы или порядка).
Структура линейного конвейера умножения с плавающей запятой
ПЭ |
|
СПР |
|
ППП |
|
УМТ |
|
ЗЭ |
|
|
|
|
|
|
|
|
|
ПЭ – подготовительный этап (распаковка чисел с ПЗ на знак, порядок и мантиссу; проверка на равенство нулю сомножителей).
СПР – сложение порядков (для смещенных порядков вычитание величины смещения).
ППП – проверка переполнения порядка и потери значимости.
УМТ – умножение мантисс как чисел с фиксированной запятой (округление до длины поля мантиссы).
ЗЭ – заключительный этап (нормализация мантиссы результата, проверка переполнения порядка и потери значимости).
Подвергаются конвейеризации также функциональные узлы целочисленного умножения и деления. В современных микропроцессорах эти операции выполняются в однотактных (одношаговых) узлах сверхпараллельной аппаратной избыточной арифметики. Широко применяются матричные умножители и делители, построенные на матричном массиве одноразрядных сумматоров, соединенных цепями переносов и имитирующих процедуру умножения в столбик. К сожалению, в большинстве вариантов матричных умножителей (делителей) требуется большая глубина массива сумматоров (число строк матрицы). Так как матричный умножитель – это многослойная комбинационная схема, задержка ее сравнительно велика. Из-за этого приходится увеличивать длительность такта между соседними парами входных сомножителей, что приводит к снижению производительности. Если схему умножителя разрезать на несколько слоев и между слоями поместить буферные регистры, то образуется многоступенчатый конвейер, который при параллелизме данных (длинном потоке пар сомножителей) позволит уменьшить такт между соседними их парами, так как он станет конвейерным. Последний, как известно, при этом выбирается по формуле
∑Tci |
|
Tk ‘ = max {Tci}< i |
, где Тсi – задержка i-го слоя комбинационной схемы матричного |
умножителя. |
|
|
3 |
Конечно, в конвейерном такте нужно учесть еще и задержку буферных регистров: Тк = Тк’ + Тбр = Тсmax + Тбр.
Однако при числе ступеней в конвейерном умножителе, равном К, сомножители могут подаваться на вход с интервалом в К раз меньшим, чем в случае отсутствия конвейеризации. Настолько же повысится темп появления результатов на выходе.
4

Схема конвейеризованного матричного умножителя Брауна для четырехразрядных сомножителей
a3 |
a2 |
a1 |
a0 |
b0
& |
|
& |
|
& |
|
& |
b1 |
|
|
|
|
|
БР1 |
|
|
|
|
|
|
|
& |
|
& |
|
& |
|
& |
|
Пс |
|
Пс |
|
Пс |
|
|
С |
5 |
С |
5 |
С |
5 |
b2 |
|
|
|
|
|
БР2 |
|
|
|
|
|
|
|
& |
|
& |
|
& |
|
& |
|
См |
|
См |
|
См |
|
|
С |
5 |
С |
5 |
С |
5 |
|
|
|
|
|
|
БР3 |
b3 |
|
|
|
|
|
|
& |
|
& |
|
& |
|
& |
См |
|
|
См |
|
См |
|
С |
5 |
|
С |
5 |
С |
5 |
БР4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
См |
|
|
|
|
|
См |
|
|
|
|
|
|
|
пс |
|
|
||
|
С |
5 |
|
|
|
С |
5 |
|
|
|
С |
5 |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
P7 |
P6 |
P5 |
P4 |
P3 P2 |
P1 |
P0 |
ПС – полусумматор, имеющий два входа для слагаемых (используется в младших разрядах, где перенос С-1 = 0).
5

СМ – полный сумматор, имеющий все необходимые три входа, в том числе для единицы переноса из соседнего младшего разряда.
- условные обозначения триггеров – защелок соответственно первого, второго, третьего и четвертого буферных регистров (БР) между соседними ступенями конвейера. Так как ступени представляют собой параллельно включенные комбинационные схемы с разными величинами задержек по разным входам, для синхронизации и продвижения результатов предыдущих ступеней в следующие без потерь и гонок целесообразно применить БР с двойной памятью, где каждый разряд «триггер - защелка» - это два последовательно соединенных триггера, управляемых по записи и перезаписи одним синхроимпульсом. Вначале по переднему фронту импульса стробируется запись в первый триггер результатов логической обработки на предыдущей ступени, где обработка началась по заднему фронту предыдущего синхроимпульса. Затем по заднему фронту импульса содержимое первого триггера переписывается во второй на вход следующей ступени, где начинается логическая обработка. Тем самым исключаются гонки между логическими цепями разной длины в каждой из ступеней конвейера.
Заметим, что такой конвейерный умножитель можно применить в качестве функционального блока на пятой ступени описанного выше конвейерного умножителя с плавающей запятой. Это позволит удлинить последний на число ступеней этого конвейера и выровнять времена обработки Tci во всех образовавшихся ступенях умножителя с плавающей запятой. При реальной длине разрядной сетки сомножителей, равной n=32; 64 разряда, расходы оборудования на буферные регистры очень усложняют схему. Тогда идут на компромисс, и число ступеней конвейера уменьшают вдвое – втрое по сравнению с разрядностью.
С целью дальнейшего повышения производительности в операционной части процессора может применяться множество параллельных конвейеров, обрабатывающих как согласные, так и встречные, и ортогональные потоки данных. Процессор, построенный на параллельных синхронных конвейерах, называется систолическим, а на параллельных асинхронных конвейерах
– волновым.
25. Классификация параллельных вычислительных систем (Флинн)
Простейший и наиболее широко используемый способэто макроклассификация ВС, введенная американским ученым Флинном. Различные способы организации ВС подразделяются по числу потоков команд и потоков данных:
1.Системы с одиночным потоком команд и одиночным потоком данных (ОКОD - SISD). Сюда относятся однопроцессорные ЭВМ.
2.Системы с множественным потоком команд и одиночным потоком данных (MKOD - MISD). Сюда относятся ВС с программируемыми конвейерами процессоров.
3.Системы с одиночным потоком команд и множественным потоком данных (OKMD - SIMD). Сюда относятся векторно - конвейерные супер - ЭВМ, матричные ВС с общим управлением, ассоциативные однородные вычислительные среды.
4.Системы с множественным потоком команд и множественным потоком данных (MKMD - MIMD). Это наиболее представительный класс, включающий фон Неймановские ММВК, МПВК, МПВС, ФРВС, ГлВС и ЛВС, транспьютерные сети, кластерные ВС, а также не фон Неймановские потоковые и редукционные ВС.
26. Понятие и типы вычислительных зависимостей (RAW, RAR, WAW, WAR) Левый сайт
Все виды зависимостей по данным могут быть классифицированы по типу ассоциаций: RAR — “чтение после чтения”, WAR — “запись после чтения” и WAW — “запись после записи”, RAW — “чтение после записи”.
6
RAR, по сути дела, соответствует отсутствию зависимостей, поскольку в данном случае порядок выполнения команд не имеет значения. Действительной зависимостью является только “чтение после записи” (RAW), так как необходимо прочитать предварительно записанные новые данные, а не старые.
Лишние зависимости по данным появляются в результате “записи после чтения” (WAR) и “записи после записи” (WAW).
После удаления лишних зависимостей по управлению и данным команды могут исполняться параллельно. Формирование расписания параллельного выполнения команд возлагается на аппаратные средства микропроцессора. Это расписание учитывает существующие зависимости между командами и имеющиеся функциональные модули процессора.
27. Закон Амдала Типикин:
Ускорение – это отношение времени Ts, затрачиваемое однопроцессорной ЭВМ, ко времени Tp решения той же задачи на n – процессорной параллельной ВС:
S = Ts/Tp.
Амдал принял допущение, что увеличение числа процессоров не сопровождается увеличением объема (сложности) решаемой задачи, т.е. одна и та же задача, обрабатываемая на однопроцессорной ЭВМ за время Ts и имеющая относительную последовательную долю f, допускает распараллеливание оставшейся ее доли (1-f) на любое число процессоров n.
Тогда можно грубо оценить время Tp решения этой же задачи на n – процессорной системе через известное время Ts и заданную величину f:
Tp = f Ts + ((1-f) *Ts))/n. Формула Амдала для ускорения S = Ts/Tp = n / (1+ f (n-1)),
Lim n→∞ S = 1/f.
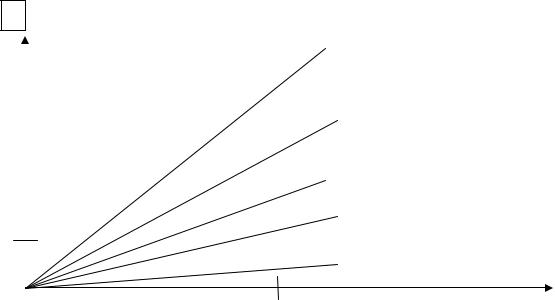
Это означает, что, если в программе имеется 10% нераспараллеливаемых последовательных операций (f=0.1), то сколько бы процессоров мы не применяли и как бы не уменьшали системные и коммуникационные издержки, ускорения более, чем в 10 раз не удастся получить. Наблюдаются большие отклонения от линейного ускорения
S
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
F=0 |
|
|
|
|
|
||
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
F=0.05 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
F=0.1 |
|
|
|
||||
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
F=0.2 |
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
F=0.5 |
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
4 |
|
|
8 |
|
12 |
|
16 |
|
|
20 |
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7

28. Основы метрической теории проектирования параллельных вычислительных средств Типикин:
Метрическая теория ВС основана на теории дискретных случайных процессов (цепях Маркова), теории сетей Петри, теории систем массового обслуживания, имитационном моделировании случайных процессов функционирования ВС методом Монте – Карло. Глубокое научное исследование позволяет получить достоверные оценки показателей эффективности ВС. В инженерной практике используются приближенные оценочные и асимптотические формулы, позволяющие принять решение при выборе варианта архитектуры и структуры создаваемой ВС на начальных этапах эскизного системотехнического проектирования. Для оценки эффективности параллельных вычислений используют систему метрик параллельных ВС.
2 вопрос
21* проблема повышения степени интеграции средств ВТ Нужно написать что то умное на основе этих тезисов
Повышение степени интеграции микросхем и связанное с этим уменьшение размеров элементов имеет определенные пределы. [1]
Повышение степени интеграции микросхем и связанное с этим уменьшение размеров элементов имеют определенные пределы. Интеграция свыше нескольких десятков тысяч элементов оказывается экономически нецелесообразной и технологически трудно выполнимой. Поэтому весьма перспективным направлением дальнейшего развития электронной техники является функциональная микроэлектроника, позволяющая реализовать определенную функцию аппаратуры без применения стандартных базовых элементов. [2]
Повышение степени интеграции микросхем и связанное с этим уменьшение размеров элементов имеет определенные пределы. Интеграция свыше нескольких десятков тысяч элементов на одном кристалле оказывается экономически нецелесообразной и технологически трудно выполнимой. Сложными становятся проблемы топологии и теплоотвода. [3] С повышением степени интеграции микросхем энергетический уровень информационных
сигналов имеет тенденцию к уменьшению. В то же время энергетический уровень внешних помех с ростом энерговооруженности предприятий непрерывно увеличивается. Полезные сигналы Sc ( t) и сигналы помех Sn ( t) могут восприниматься аппаратурой в виде суммарной величины. [4]
Зависимость выхода го
Важнейшей тенденцией развития интегральной микроэлектроники является повышение степени интеграции микросхем. Однако увеличение числа элементов в микросхеме существенно зависит от достигнутого уровня технологии, характеризуемого выходом годных структур на кремниевых пластинах. [5] По мере развития интегральной технологии, повышения степени интеграции
микросхем усложняется, а также удорожается процедура тестирования БИС и схемных плат. Чтобы осуществить тестирование, требуется много разнообразной аппаратуры для контроля, диагностики и отыскания неисправностей. При этом необходим большой набор программных
8
средств. В значительной мере сказанное относится и к тестированию сложных цифровых устройств, особенно содержащих микропроцессорные системы. [6] Интегральная микроэлектроника продолжает развиваться в направлении повышения степени
интеграции микросхем как за счет увеличения размеров кристалла, так и в основном за счет уменьшения размера элементов ИМС. В современных БИС и СБИС размеры элементов составляют 3 - 2 мкм. В ближайшем будущем размеры элементов топологии СБИС достигнут 1 мкм. Ведутся исследования по освоению субмикронных размеров. Эти исследования показали, что пределом уменьшения размеров элемента топологии ( ширина линий, зазоров между ними и др.) является значение 0 2 мкм. Однако при достижении таких размеров элементов возникнут определенные технологические ограничения. [7] Развитие интегральной техники характеризуется тенденцией к повышению степени интеграции микросхем. [8]
Прослежены тенденции развития процессов и оборудования ХОГФ функциональных слоев при повышении степени интеграции микросхем, изготавливаемых как по стандартной КМОП технологии, так и по технологии с трехмерной интеграцией и вертикальными полевыми транзисторами. [9] Интегральные микросхемы широкого применения выпускаются специальными заводами-
изготовителями для продажи заводам-изготовителям аппаратуры, В большинстве случаев это малые интегральные схемы, выполняющие функции однокаскадных либо двухкаскад-ных функциональных узлов. Микросхем широкого применения на уровне БИС пока мало. Это объясняется тем, что с повышением степени интеграции микросхемы все более теряется ее универсальность и повышается специализация. [10]
22* проблема снижения себестоимости производства средств ВТ
Хз
23* проблема автоматизации распараллеливания вычислений Подозреваю что много затрат на расчеты для распределения, могу ошибаться
24* проблема повышения быстродействия памяти Сложность совмещения частоты работы процессора шины и памяти(возможно, лишь я так думаю)
25* алмазные полупроводники На сколько правда не знаю
Чип на основе алмаза-полупроводника может работать при частоте до 81 ГГц, что в несколько раз выше, чем кремниевые аналоги. При этом теплоотдача у алмазных полупроводников ниже, следовательно их можно будет компоновать с более высокой плотностью размещения компонент и потребуется значительно меньшие затраты на охлаждение алмазного чипа.
Как утверждают эксперты из европейской компании по производству алмазных полупроводников Carbon Power Electronics Сonsortium, благодаря постоянно снижающейся стоимости искусственных алмазов к 2011 году на рынке появятся первые электронные устройства на их основе.
В то время как классические микросхемы и чип переживут еще 4–5 итераций закона Мура, «алмазные микросхемы» могут продлить этот закон еще на 10–20 итераций, при использовании технологий лазерных соединений между микросхемами, трехмерным построением архитектуры и т.п. Через время, при развитой молекулярной нанотехнологии, можно будет создать алмазоид, который заменит большинство традиционных материалов. Это открытие еще в несколько раз продлит закон Мура из-за перехода к механоэлектрическим компьютерам с высокой плотностью вычислительной мощности.
Скорее всего, что алмазные чипы будут использоваться, в первую очередь, в космической и военной микроэлектронике из-за высокой природной устойчивости алмаза к резким перепадам температур и высокому давлению.
9
26* молекулярные компьютеры педивикия
Молекулярные компьютеры — вычислительные системы, использующие вычислительные возможности молекул (преимущественно, органических). Молекулярными компьютерами используется идея вычислительных возможностей расположения атомов в пространстве.
Под молекулярным компьютером обычно понимают такие системы, которые используют отдельные молекулы в качестве элементов вычислительного тракта. В частности, молекулярный компьютер может представлять логические электрические цепи, составленные из отдельных молекул; транзисторы, управляемые одной молекулой, и т. п.
Также молекулярным компьютером могут назвать ДНК-компьютер, вычисления в котором соответствуют различным реакциям между фрагментами ДНК. От классических компьютеров такие отличаются тем, что химические реакции происходят сразу между множеством молекул независимо друг от друга.
10