

Построение нейросетевого классификатора
В результате кластеризации все множество данных было разбито на четыре класса.
Внутри кластеров данные однородны
значит, поведение физического процесса в рамках одного кластера более предсказуемо, нежели поведение этого процесса в общем.
Чтобы новый элемент (x, y, Factor1, Factor2) отнести к к-л классу, надо создать инструмент, который:
по заданной четверке чисел выводил бы кластер, к которому данный объект принадлежит.
Т.е. решить задачу классификации
Решим задачу классификации с применением нейронных сетей.
Запуск модуля Neural Networks:
воспользуемся одноименной командой
основное меню системы STATISTICA - Statistics.
Команда Neural Networks
вызов стартовой панели модуля STATISTICA Neural Networks (SNN) =>
появл-ся стартовая панель модуля STATISTICA Neural Networks (SNN).

Рис.17. Стартовая панель модуля SNN.
Вкладка Quick - Быстрый- разделProblem Type = Класс задач выберем Classification – Классифика4ция.
выбрать переменные для анализа: кнопка Variables =>
появляется окно Select input (independent), output (dependent) and selector variables - Укажите входные (независимые), выходные (зависимые) и группирующие переменные
В данном окне задаём 3 списка переменных:
Categorical outputs - Категориальные выходящие, в нашем случае, - это переменная Cluster
Continuous inputs - Непрерывные входящие, в нашем примере, - это переменные x и y.
Categorical inputs - Категориальные входящие, у нас это переменные Factor1 и Factor2.
Раздел Subset variable - Разбиение на подмножестванеобязателенд/заполнения (выбор переменной, в которой содержатся коды для разбиения данных на обучающее контрольное и тестовое множества)
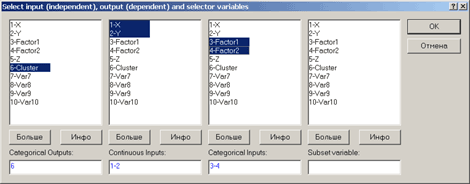
Рис.18. Выбор переменных для Анализа.
Раздел Select analysis - Выбор анализа:
нужна опцияIntelligent Problem Solver(устанавливается по умолчанию)
нажмем кнопку OK.
появляется окно настройки процедуры Intelligent Problem Solve
вкладка Quick - Быстрыйи её разделOptimization Time - Время оптимизации
в поле ввода Networks tested - Количество тестируемых сетейукажем 50
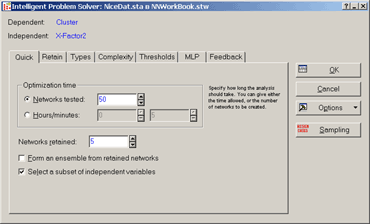
Рис.19. Вид диалогового окна поиска сети.
В диалоговом окне состояния алгоритма поиска сети:
выводится информация, что и в примере задачи регрессии
За исключением: производительность сейчас равна доле правильно классифицируемых наблюдений
чем ближе производительность к единице, тем лучше.
В итоге, отобрана сеть с наилучшей производительностью
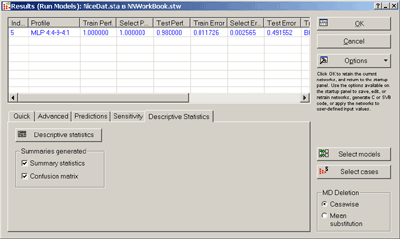
Рис.20. Параметры нейронной сети - классификатора.
Вкладка Descriptive Statistics - Описательные статистики:
нажмем одноименную кнопку
появится таблица статистик классификации
Столбцы этой таблицы - наблюдаемые классы
строки - предсказанные классы
В идеале в этой матрице диагональные эл-ты д.б. отличны от нуля, а все остальные ячейки – нулевые =>
производительность сети = 1 (В нашем случае, на одном из наблюдений нейронная сеть ошиблась)
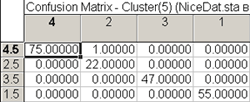
Рис.21. Статистики классификации.
Определить кластер многомерного наблюдения:
вкладка Advanced - Дополнительно- кнопкаUser defined case - Пользовательское значение
появл-ся диалоговое окно User defined case prediction - Прогноз значений пользователя -вкладкаQuick - Быстрый- кнопкаUser defined input - Задать входные значения.
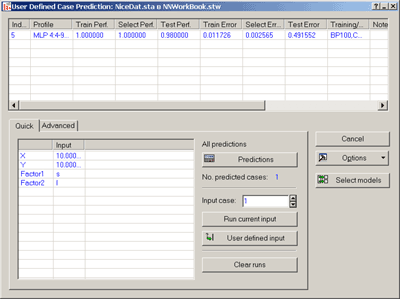
Рис.22. Вид диалогового окна User defined case prediction - Прогноз значений пользователя.
Ввести значения
нажать кнопку Predictions – Прогноз
нейронная сеть выдаст номер кластера, которому принадлежит заданный объект.
Классификатор построен.
Сохранение конфигурации нейронной сети, выполняющей классификацию:
в диалоговом окне результатов поиска нейронной сети необходимо нажать кнопку ОК
перейти в стартовую панель модуля
В стартовой панели модуля выберите вкладку Networks/Ensembles - Сети/Ансамбли -> кнопкаSave network file as ... - Сохранить файл нейронный сети как ...