

Кластеризация данных
Сформулируем задачу кластерного анализа:
имеется 200 объектов (по количество доступных для построения моделей наблюдений) в 4х-мерном пространстве (x, y, factor1, factor2).
переменную z мы отбросили (она зависит от всех остальных и заведомо не повлияет на качество кластеризации) Необходимо разбить эти объекты на ряд групп, таким образом:
внутри группы объекты максимально схожи между собой;
группы максимально между собой различаются.
скорее всего, ввиду однородности, внутри каждого кластера зависимость z = f(x, y, factor1, factor2) будет непрерывной функцией
построив для каждого из кластеров отдельную нейронную сеть, мы построим модель физического процесса.
Сравнение объектов.
в рассматриваемом пространстве (x, y, factor1, factor2) ввести количеств. меру сходства между объектами
кажется удобным введение евклидова расстояния - корень из суммы квадратов покоординатных разностей
Но различные независимые переменные могут измеряться в разных шкалах с различными диапазонами:
значения одной переменной измеряются в сотнях и изменяются в пределах десяти
другая переменная в среднем равна нулю и изменяется в пределах единицы =>
вклад последней в евклидово расстояние будет пренебрежительно малым =>
Нужна процедура стандартизации переменных - приведение всех переменных к единой шкале:
Стандартизация:
данные изменяются в пределах нуля в диапазоне ±3
большая часть всех значений будет принадлеж. интервалу (-1, 1)
процедура стандартизации не изменяет структуру взаимодействий между переменными =>
стандартизация не влияет на структуру кластеров
стандартизация применима к переменным, измеряемым в непрерывной шкале
Cтандартизация непрерывной переменной:
необходимо выделить соответствующий столбец
нажать правую кнопку мыши
из появившегося контекстного меню выбрать раздел Fill/Standardize Block - Заполнить/Стандартизовать Блок
выполнить команду меню Standardize Columns - Стандартизовать столбцы
=>Эту процедуру необходимо выполнить для переменных x и y.
Стандартизация категориальных переменных:
Переменная factor1 принимает значения только (s, m)
переменная factor2 - значения (l, d)
По умолчанию система STATISTICAуровням факторов этих переменных присвоила значения (101, 102)
надо перекодировать, чтобы диапазон их изменения соответствовал диапазону изменения непрерывных переменных
Перекодировка каждой категориальной переменной:
дважды кликнуть на ее названии в Таблице данных
в появившемся диалоговом окне спецификаций переменных нажать кнопку Text Labels - Текстовые метки.

Рис.12. Изменение значений уровней факторов категориальной переменной.
В разделе Numeric - Числодиалогового окнаText Labels Editor - Редактор текстовых метокнеобходимо поставить значения -1 и 1 =>
среднее категориальных переменных равно нулю
диапазон значений сравним с диапазоном изменения непрерывных переменных
Замечание:
округленный до целых результат формальной стандартизации категор. переменных приводит к тому же результату
Но если просто выполнить стандартизацию категор. переменных, текстовые значения будут утеряны, что может привести к некорректным результатам.
Число кластеров:
Эксперты, имеющие представление о природе процесса, могут предположительно указать на число кластеров
существует агломеративный метод иерархической классификации, или иерархический кластерный анализ
Иерархический кластерный анализ:
на первом шаге каждый объект выборки рассматривается как отдельный кластер
Процесс объединения происходит последовательно:
на основании матрицы расстояний объединяются наиболее близкие объекты
Если матрица сходства первоначально имеет размерность mxm, то полностью процесс кластеризации завершается за m-1 шагов =>
в итоге все объекты будут объединены в один кластер
Последоват-ть объединения м.б. представлена в виде графа - дерева (дендрограммы):
На оси абсцисс - имена наблюдений
по оси ординат, - расстояние объединения наблюдений в кластеры
чем выше расположена ветвь дерева на дендрограмме, тем позднее было проведено объединение объектов.
Проведем иерархический кластерный анализ на стандартизованных данных:
команды меню Statistics - Multivariate Exploratory Techniques - Cluster Analysis - Анализ - Многомерный разведочный анализ - Кластерный анализ
В появившемся окне Clustering method - Методы кластеризациивыберемJoining (tree clustering) - Иерархическая классификация
нажмем ОК
В окне Cluster Analysis: Joining (Tree Clustering) - Кластерный анализ: иерархическая классификациявыберем вкладкуAdvanced – Дополнительно
В качестве переменных для анализа выберем x, y, Factor1, Factor2
В разделе Cluster - ОбъектывыберемCases (Rows) - Наблюдения (строки)
В качестве меры сходства в разделе Distance measure - Мера близостиукажемEuclidian distances - Евклидово расстояние
Остальные параметры оставим по умолчанию
Вид диалогового окна со всеми нужными установками представлен на Рис.13.
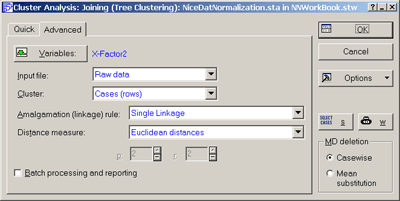
Рис.13. Диалоговое окно задания параметров иерархической классификации.
Нажмём ОК:
В появившемся окне результатов объединения:
отменим опциюRectangular Branches - Прямоугольные ветвии
нажмем кнопку Vertical icicle plot - Вертикальная дендрограмма
Результат построения графика -Рис.14.
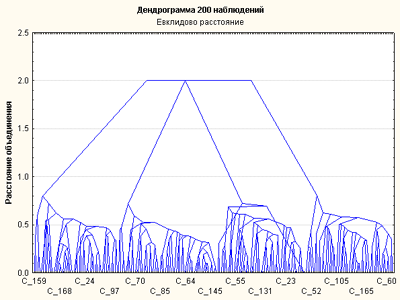
Рис.14. Вертикальная дендрограмма древовидной классификации для переменных x, y, factor1, factor2.
древовидная диаграмма:
отображает историю объединения объектов в кластеры
Чем выше ветви дерева - графа, тем позднее объекты были объединены
на Рис.14 отчетливо выделяются 4 ветви дерева, объединенные на одинаковой высоте
Каждая из этих ветвей имеет продолжение в виде скоплений ветвей меньшей высоты – кучностей
структура скоплений не обладает ярко выраженной иерархией.
можно утверждать, что все множество данных хорошо разделяется на 4 кластера
график показывает: однородность данных внутри кластера и максим. отдаленность самих кластеров достигнуты
Выявление переменных, "ответственных" за кластеризацию.
Чем меньше переменных ответственны за разбиения данных на кластеры, тем легче понять физический разбиения. Проведем иерархическую классификацию для переменных всех переменных, кроме x
Последовательность действий аналогична предыдущему анализу
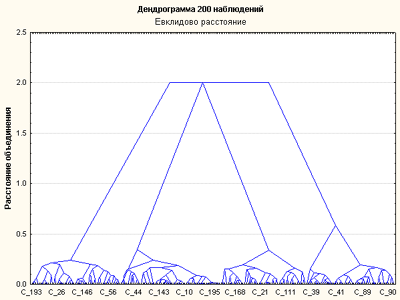
Результат кластеризации приведен в виде дендрограммы на Рис.15.
 4
4
Рис.15. Вертикальная дендрограмма древовидной классификации для переменных y, factor1, factor2.
Высота больших ветвей диаграммы осталась прежней ->расстояния между кластерами остались прежними.
высоты скоплений ветвей уменьшились ->внутриклассовые различия стали значительно меньше =>
в отсутствие переменной x получена более качественная кластеризация
Теперь необходимо разбить объекты по кластерам:
воспользуемся итеративной процедурой, методом к-средних
процесс классификации начинается с задания начальных условий:
количество образуемых кластеров
центры этих кластеров
каждое многомерное наблюдение совокупности относится к тому кластеру, центр которого ближе всех к этому наблюдению
Затем выполняется проверка на устойчивость классификации
Если классификация устойчива, процесс останавливается. В противном случае, происходит очередная процедура разбиения объектов по кластерам.
Выполним метод K-средних на стандартизованных данных:
воспользуемся командами меню Statistics - Multivariate Exploratory Techniques - Cluster Analysis - Анализ - Многомерный разведочный анализ - Кластерный анализ
В окне Clustering method - Методы кластеризациивыберемК-means clustering - Кластеризация методом К-средних
нажмем ОК
В окне Cluster Analysis: К-means clustering - Кластерный анализ: кластеризация методом К-среднихвыберем вкладкуAdvanced – Дополнительно
В качестве переменных для анализа выберем y, Factor1, Factor2
В разделе Cluster - ОбъектывыберемCases (Rows) - Наблюдения (строки)
В поле Number of Clusters - Число кластероввведем 4
Вид диалогового окна со всеми нужными установками представлен на Рис.16.
нажмем ОК
Вкладка Advanced - Дополнительноокна результатов - кнопкаSave classifications and distances - Сохранить результаты классификации и расстояния
В появившейся Таблице результатов скопируем переменную Cluster и добавим ее в исходный файл данных (Добавление переменных: дважды щёлкнуть мышью на пустой клетке строки названий переменных – окно - указать название)
В строках данной переменной содержатся номера кластеров, к которым были отнесены многомерные объекты.
Кластеризация проведена.

Рис.16. Диалоговое окно задания параметров кластеризации методом K-средних.