

Описание задания по классификации.
Постановка задачи.
ДАНО:
Пусть состояние предприятия описывается совокупностью 4-х параметров: R1, R2, R3, R4.
Для оценки статуса (класса) предприятия будем использовать дискретную переменную TYPE, которая может принимать только 3 значения:
A, B, C.
Класс предприятия (значение переменной TYPE) определяется совокупностью 4-х переменных (R1, R2, R3, R4).
Известна целая выборка предприятий всех 3-х классов и соответствующие им 4 показателя.
Требуется:
-
по известным выборкам R1, R2, R3, R4, TYPE обучить нейронную сеть правильно определять класс предприятия, а именно:
- подавать на вход сети переменные R1, R2, R3, R4 и, изменяя веса нейронов сети, добиться того, чтобы на выходе сети получалось требуемое значение переменной TYPE.
2) Применить обученную сеть для определения класса предприятия по новым совокупностям 4-х переменных R1, R2, R3, R4.
Работа с пакетом SNN (Statistica Neural Networks).
Вход в пакет SNN:
Пуск – Программы – Статистика 7.
Загрузится программа STATISTICA.
Импорт данных из файлов EXCEL:
1. Окно Select Spreadsheeat – Files – Откроется окно для Выбора пути к нужному файл.
Выбрать нужный файл.
2) Можно после входа в программу STATISTICA загрузить нужный файл:
File – Open – выбираем путь к файлу (Если выбирается файл, сформированный не в программе STATISTICA, то указать Тип файлов All Files).

Выбрать нужную страницу файла EXCEL:
кнопка Import selected sheet to Spreadsheet
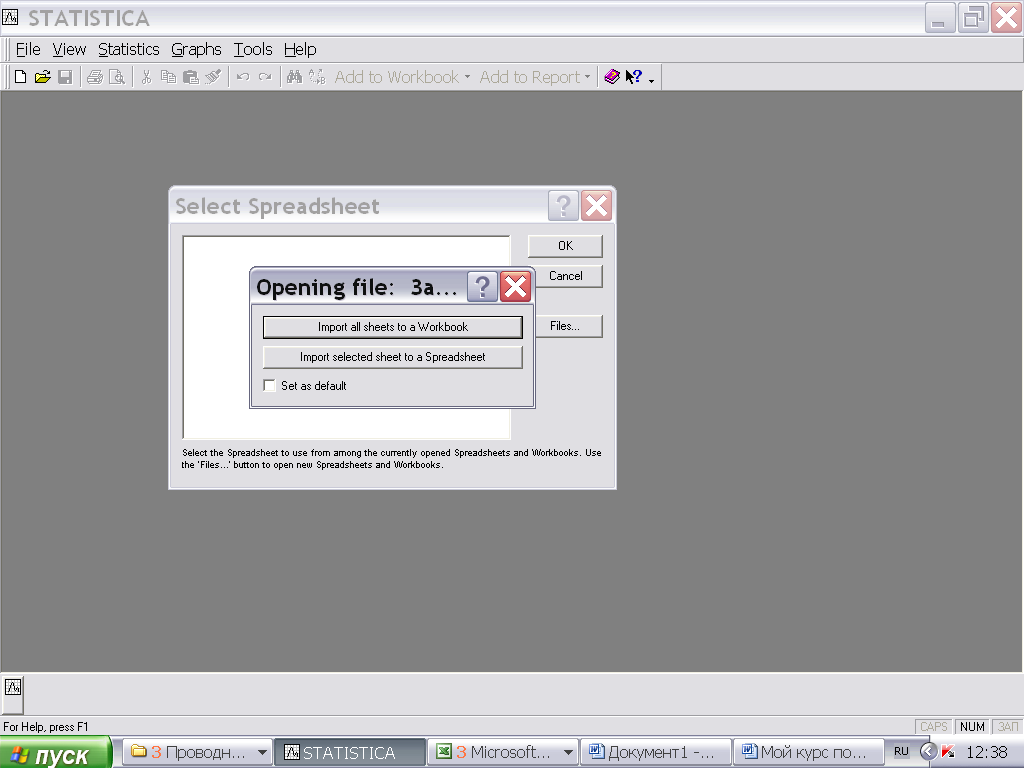
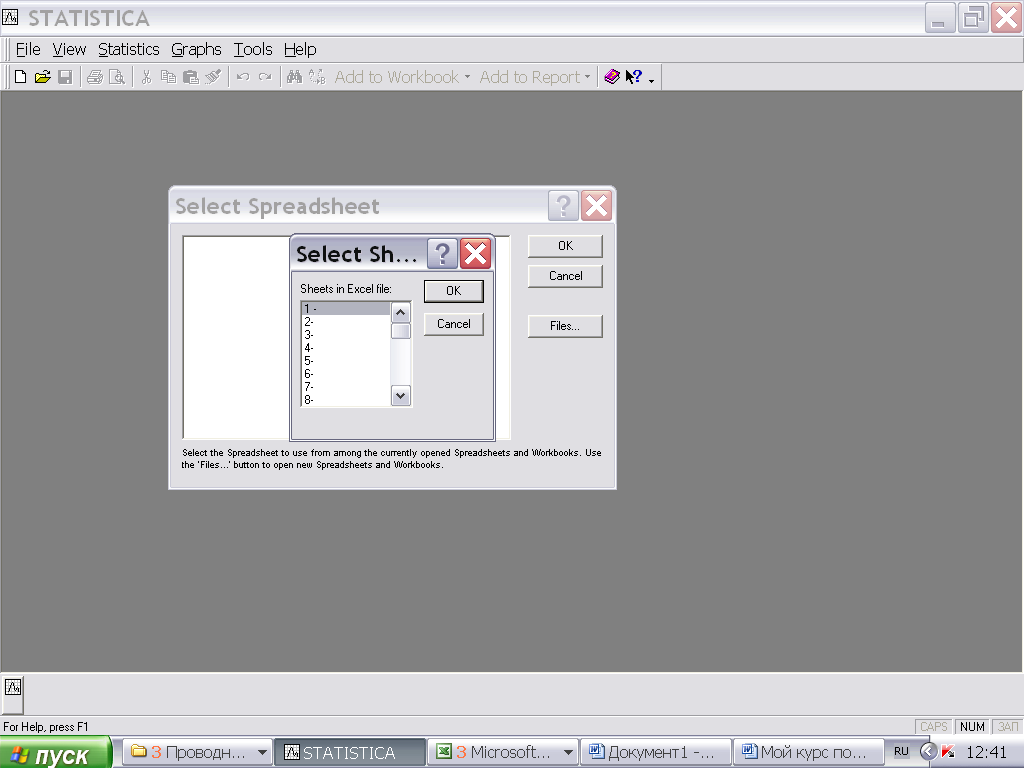
Выбираете нужную страницу, и она загружается в программу STATISTICA.
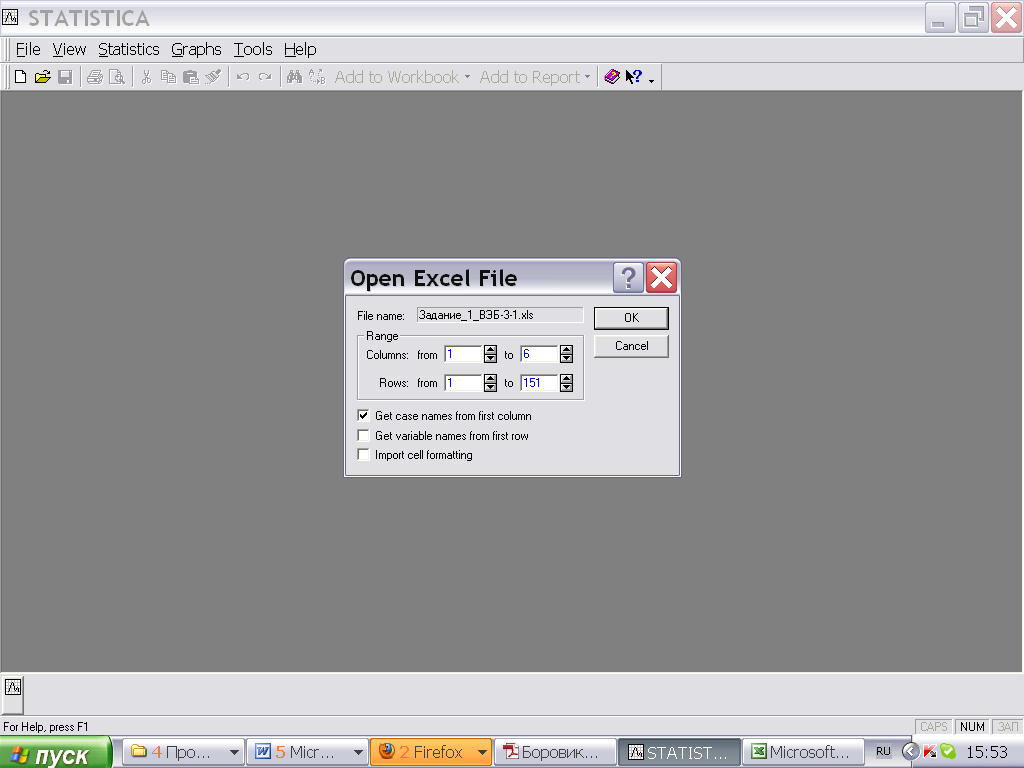
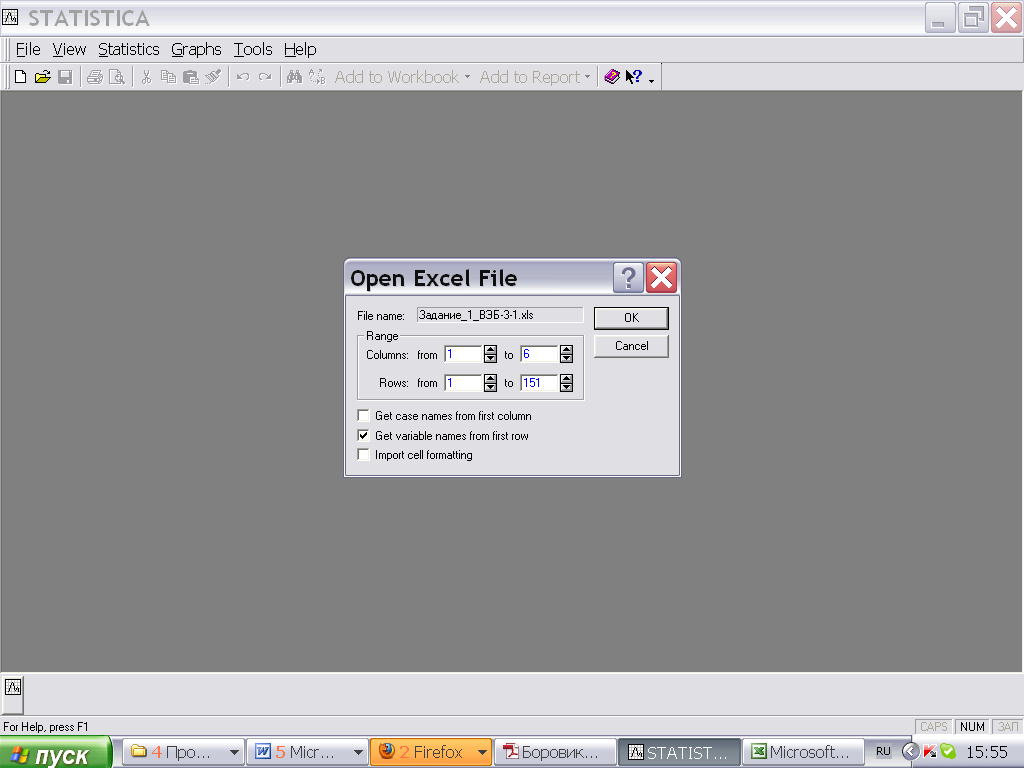
Если столбцы уже названы в EXCEL, то можно отметить пункты:
Get variable names From first row – дать название переменным по 1-й строке
Тогда загруженная Таблица данных (тип файла *.sta) будет выглядеть так:
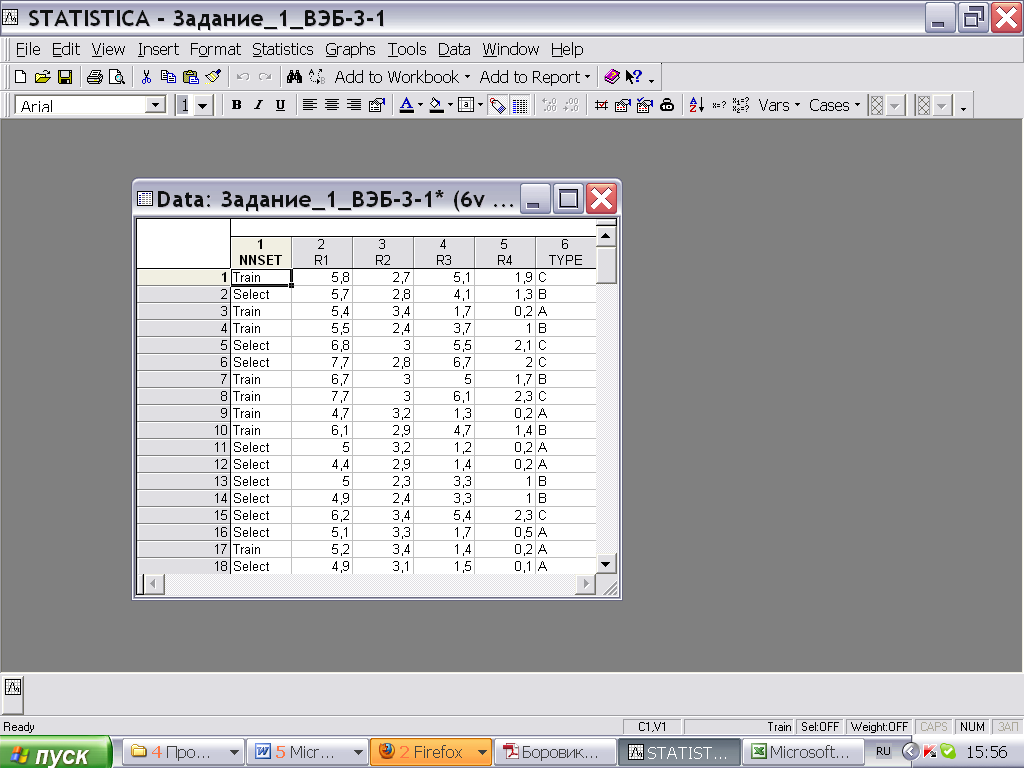
Если эти пункты не отмечать, то придётся называть столбцы и строки в программе STATISTICA.
Сохранить получившуюся в программе STATISTICA Таблицу данных обычным способом.
Запустить модуль Neural Networks:
Запуск модуля Neural Networks:
-
воспользуемся одноименной командой
-
основное меню системы STATISTICA - Statistics.
-
Команда Neural Networks
-
вызов стартовой панели модуля STATISTICA Neural Networks (SNN).
Statistics - Neural Networks -> Появится Стартовая панель модуля Neural Networks:
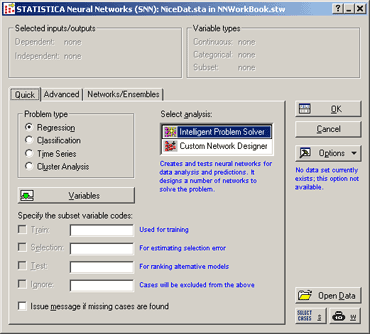
-
Во вкладке Quick - Быстрый доступны три, наиболее часто используемые опции.
-
В разделе Problem Type - Класс задач – выбрать класс задач.
доступны классы задач:
-
Regression - Регрессия
-
Classification – Классификация
-
Time series - Прогнозирование временных рядов
-
Cluster analysis - Кластерный анализ.
Выбрать - Classification – Классификация

Указать переменные для проведения Анализа:
-
кнопка Variables =>
-
появляется диалоговое окно Select input (independent), output (dependent) and selector variables =- Укажите входные (независимые), выходные (зависимые) и группирующие переменные.
Задать три списка переменных:
-
Categorial outputs - Категориальные выходящие (т.е. определяющие класс), в нашем случае, - это переменная Type.
-
Continuous inputs - Непрерывные входящие, в нашем примере, - это переменные R1, R2, R3, R4
-
Categorial inputs – в данном задании отсутствуют
-
Subset variables -
Раздел Subset variable - Разбиение на подмножества:
-
необязателен для заполнения
-
служит для выбора переменной, в которой содержатся коды для разбиения данных на:
-
обучающее – используется для обучения сети
-
контрольное – для проверки степени обученности сети
-
тестовое множества.
-
Даже если эта переменная не указана, мастер решений сам формирует 3 этих подмножества данных.
Чтобы задать эти 3 списка переменных, надо выделить требуемы переменные в больших окнах над соответствующими маленькими окошками, и их номера будут высвечены в маленьких окошках:
Categorial outputs
Continues inputs
Categorial inputs
Subset variables
1) Обучающая выборка - используется для обучения сети (т.е., чтобы оценить веса сети и другие параметры). Каждая подача обучающей выборки в сеть, исп-ся для корректировки весов и порогов, наз. Эпохой. Для этого считается ошибка сети.
2)Контрольная выборка. Наблюдения в контрольной выборке будут использованы для проведения "независимой проверки" качества сети во время обучения,
Общая ошибка также вычисляется для контрольной выборки (иногда ее называют проверочной выборкой).
Если ошибка на контрольных данных перестает уменьшаться или начинает расти, обучение останавливается.
Эти данные не принимают участия в корректировке порогов и весов, но во время обучения
качество сети постоянно проверяется на этой выборке
Использование контрольных данных важно, так как при неограниченном обучении нейронная сеть начинает "зазубривать" обучающие данные.
Использование контрольной выборки для остановки обучения в момент наилучшей обобщающей способности является важным моментом при обучении НС
-
Как правило, ошибка на контрольном множестве превышает ошибку на обучающем множестве, так как:
-
алгоритм обучения нацелен на минимизацию ошибки на выходе сети
Если наблюдается рост ошибки на контрольном множестве и её уменьшение на обучающем множестве:
-
сеть "зазубрила" предъявленные ей наблюдения
-
не способна к обобщению
-
такое состояние называется переобучением - переобучения надо избегать.
Алгоритм Intelligent Problem Solver:
-
самостоятельно отслеживает переобучение
-
при завершении обучения возвращает сеть в наилучшее состояние (Retain Best Network - Восстановить наилучшую сеть).
Тестовая выборка.
Может использоваться для сравнения альтернативных моделей.
-
не участвует в обучении вообще
-
после завершения обучения используется для:
-
расчета производительности полученной сети
-
её ошибки на данных, о которых "ей вообще ничего неизвестно".
-
Хорошая сеть:
-
ошибка одинаково мала на всех трех подмножествах.
Игнорировать. Наблюдения в выборке Игнорировать будут проигнорированы во время обучения или при окончательной оценке сети,
Выходим из вкладки Variables – возвратились к Стартовой панели:
Нажмем кнопку OK.
Раздел Select analysis - Выбор анализа – (Инструмента решения):
доступны 2 опции:
-
Intelligent Problem Solver (Мастер решения) – на 1-м этапе будем пользоваться им, устанавливается по умолчанию
-
Custom Network Designer – Конструктор решения – для продвинутых пользователей
Мастер решений - это сложный инструмент, помогающий создавать и тестировать сети для задач анализа данных и прогнозирования.
Конструирует множество сетей для решения задачи
Копирует их в текущий Набор сетей
Затем передает эти сети в окно Результаты, позволяя проверить их качество различными способами.
Выбрать Intelligent Problem Solver (Мастер решения).
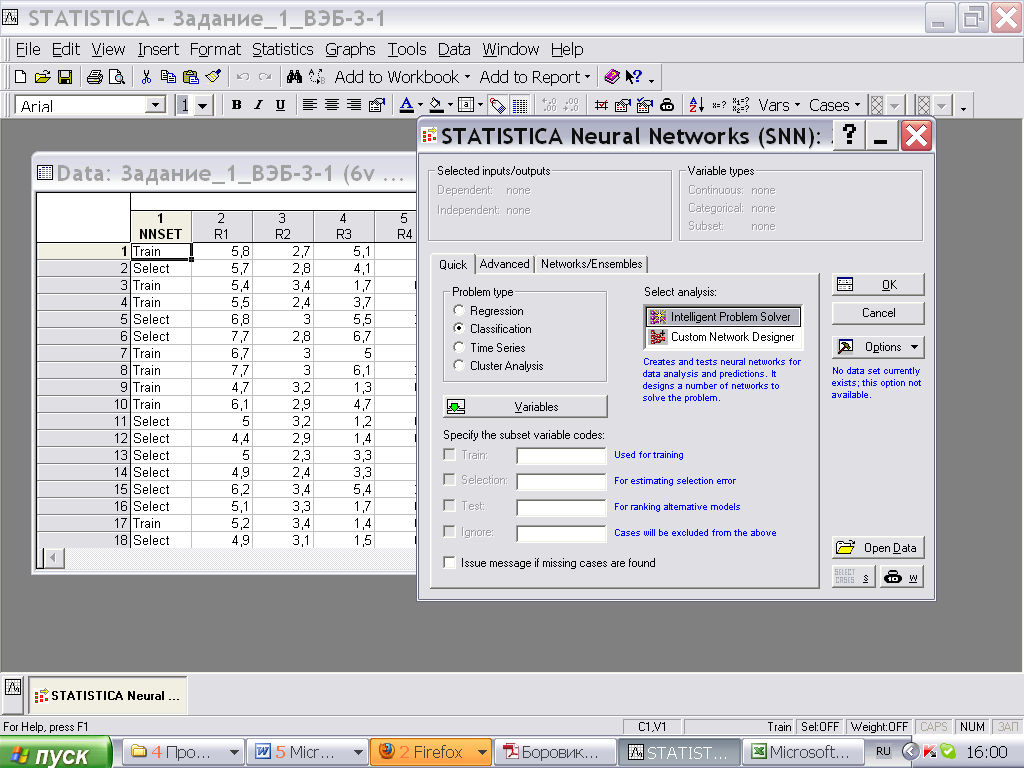
Появляется окно настройки процедуры Intelligent Problem Solver - Мастер решений SNN.
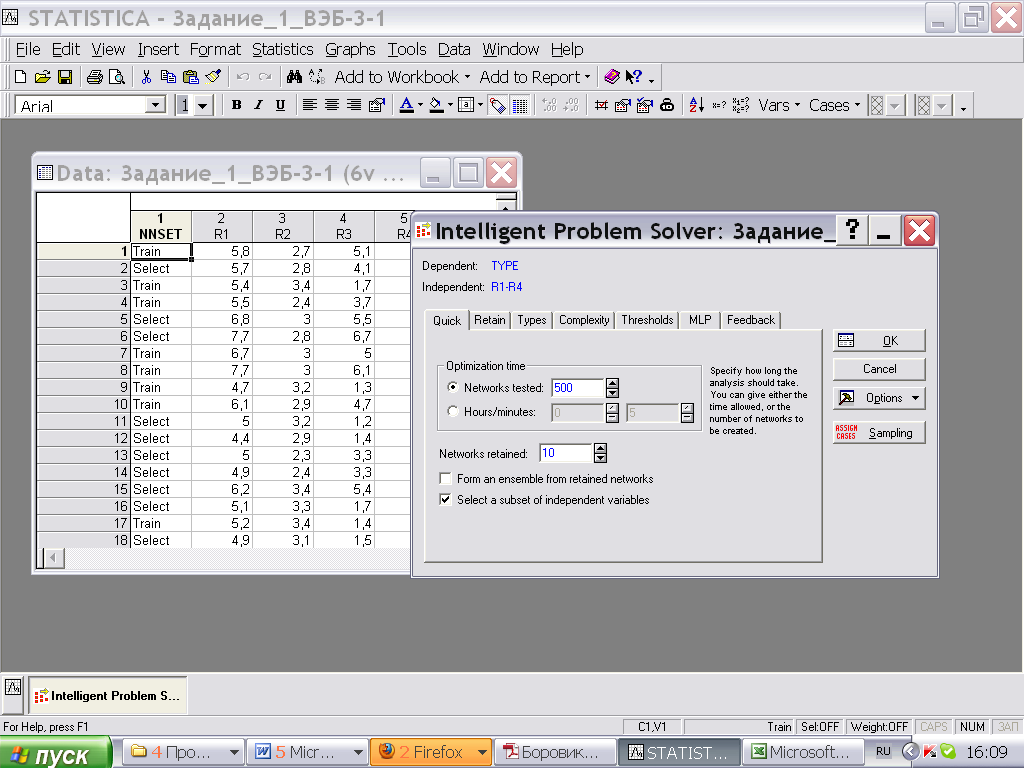
Окно содержит большое количество опций, распределенных в различных вкладках.
Основные опции:
Quik (быстрый) – задаётся количество обучаемых сетей – Network Tested
Retain (сохранить) – войдя в эту вкладку, можно ввести кол-во сохраняемых моделей сетей
Types (Типы сетей) – в этой вкладке можно выбрать типы тестируемых сетей
-
Linear – линейная сеть (в выходном слое содержит только линейные эл-ты)
-
GRNN – Обобщённо-регрессионная сеть
-
PNN- вероятностная нейронная сеть
-
Radial basis function – радиальная базисная сеть
-
Three layer perceptron – 3-х слойный персептрон
-
Four layer perceptron – 4-х слойный персептрон
Complexity (сложность) – можно задать кол-во нейронов на скрытом слое
-
нам понадобится вкладка Quick - Быстрый и её раздел Optimization Time - Время оптимизации (содержит группу опций, отвечающих за время исполнения алгоритма поиска нейронной сети)
-
2 возможности:
1)задать количество сетей, которые необходимо протестировать (подходят ли они для решения задачи);
2)вручную задать время выполнения алгоритма. Для этого необходимо воспользоваться опцией Hours/Minutes - Часы/Минуты.
Воспользуемся 1-й опцией.
1)В разделе Optimization Time - Время оптимизации:
в опции Networks tested - Количество тестируемых сетей укажем 200.
2)В разделе Networks Retained (Количество сохранённых сетей) укажем 10.
Запускаем Мастер в работу (ОК).
Состояние алгоритма поиска отображается в диалоговом окне IPS Training In Progress - Процесс поиска сети, см. Рис.6.
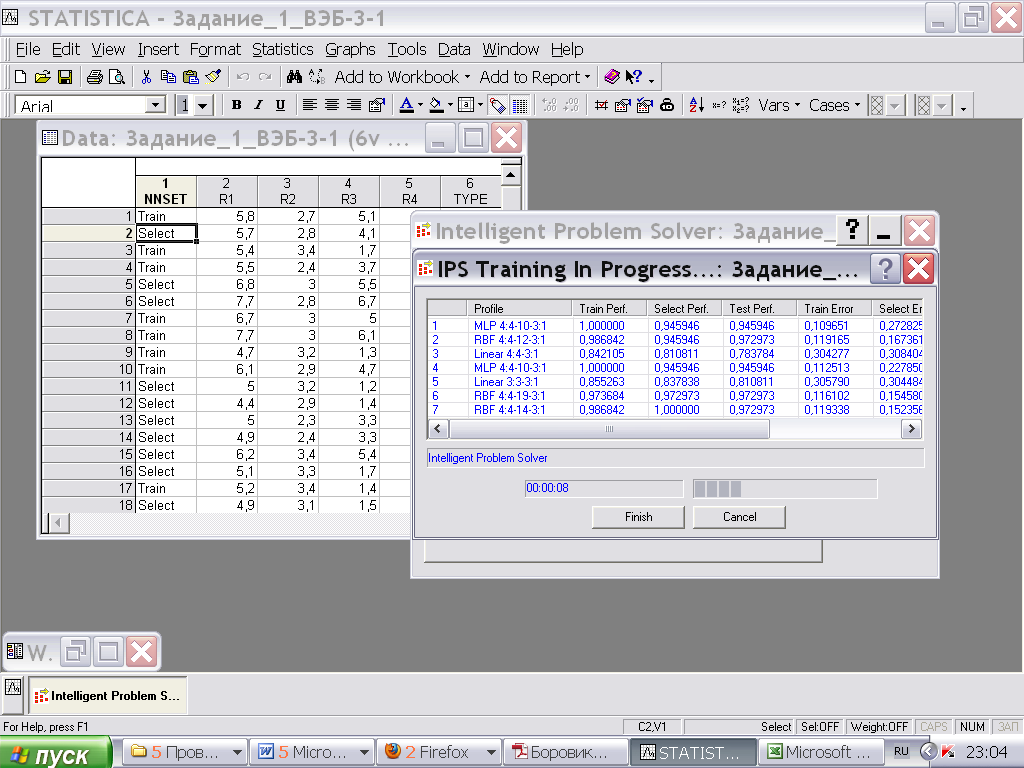
Рис.6. Процесс поиска сети.
-
информация о времени исполнения алгоритма
-
о рассмотренных нейронных сетях
Цель алгоритма поиска:
-
перебор ряда нейросетевых конфигураций
-
выбор наилучшей с точки зрения:
-
минимума ошибки на выходе сети и
-
максимума её производительности
-
Сети необходимо:
-
Обучать
-
рассчитывать их ошибки и производительности
-
эти показатели сравнивать
Получили результат – панель Results:
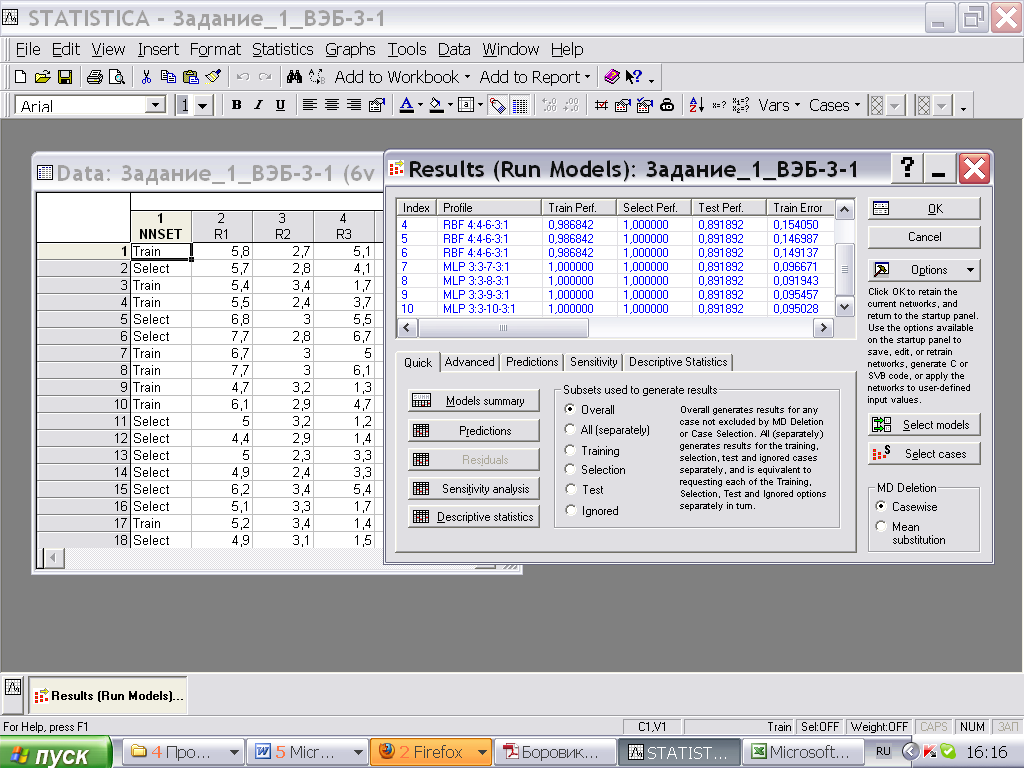
Структура Таблицы Results:
Каждая строка соответствует определённой конфигурации сети
Каждая нейронная конфигурация описывается строкой в информационном поле диалогового окна.
Столбцы:
-
Index – номер отобранной сети.
-
Profile - Тип сети
-
Train (Select, Test) Performance - Производительность сети на обучающем (контрольном, тестовом) множестве
-
Train (Select, Test) Error - Ошибка обучения (контроля, тестирования)
-
Training/members
-
Inputs – число входов
-
Hidden(1) – число нейронов на 1-м скрытом слое
-
Hidden(2)- число нейронов на 2-м скрытом слое
Раздел Profile - Тип сети описывает:
-
топология нейронной сети = её класс (персептрон (MLP), сеть RBF и т.д.)
-
количество входных и выходных переменных
-
количество скрытых слоев
-
число элементов на каждом скрытом слое
Формат строки:
<тип> <входы>: <слой1>-<слой2>-<слой3>: <выходы>
Например, архитектура MLP 4:4-7-3:1 обозначает:
многослойный персептрон с 4-мя входными и 1-й выходной переменными, и 3-мя слоями по 4, 7 и 3 элементов соответственно.
Производительность обуч./Контр. производительность /Тест. производительность.
Значение производительности зависит от типа сети.
Для сети классификации, это доля правильно классифицированных наблюдений в выборке.
Для регрессионной сети - это отношение стандартных отклонений ошибки прогноза и наблюдаемых значений
Эти столбцы дают производительность сети на обучающей, контрольной и тестовой выборках соответственно.
Не следует слишком доверять уровню производительности, который приводится для обучающей выборки, так как он зачастую обманчиво высок (что говорит о переобучении).
Контрольная производительность - это ключ к оценке сетей, показанных в окне итоги моделей.
(Контрольная производительность 1.0 означает, что все контрольные наблюдения классифицированы правильно.)
Ошибка обучения/Контрольная ошибка/Тестовая ошибка.
Алгоритмы обучения оптимизируют функцию ошибки.
Значение ошибки интерпретируется менее точно, чем значение производительности, но более значимо для алгоритмов обучения.
Training/members:
BP100, CG20, CG0b - значит "сто эпох обратного распространения, затем двадцать эпох метода сопряженных градиентов, после которых алгоритм был остановлен из-за переобучения и была восстановлена лучшая за время обучения сеть.
Основные вкладки окна результатов:
1)Models Summary – Результаты моделей
2)Predictions – Таблица предсказаний
3)Residuals – Таблица остатков
4)Sensitivity analysis –Таблица чувствительности
5)Descriptive statistics – (Описательные статистики) - Таблица классификации и Матрица ошибок
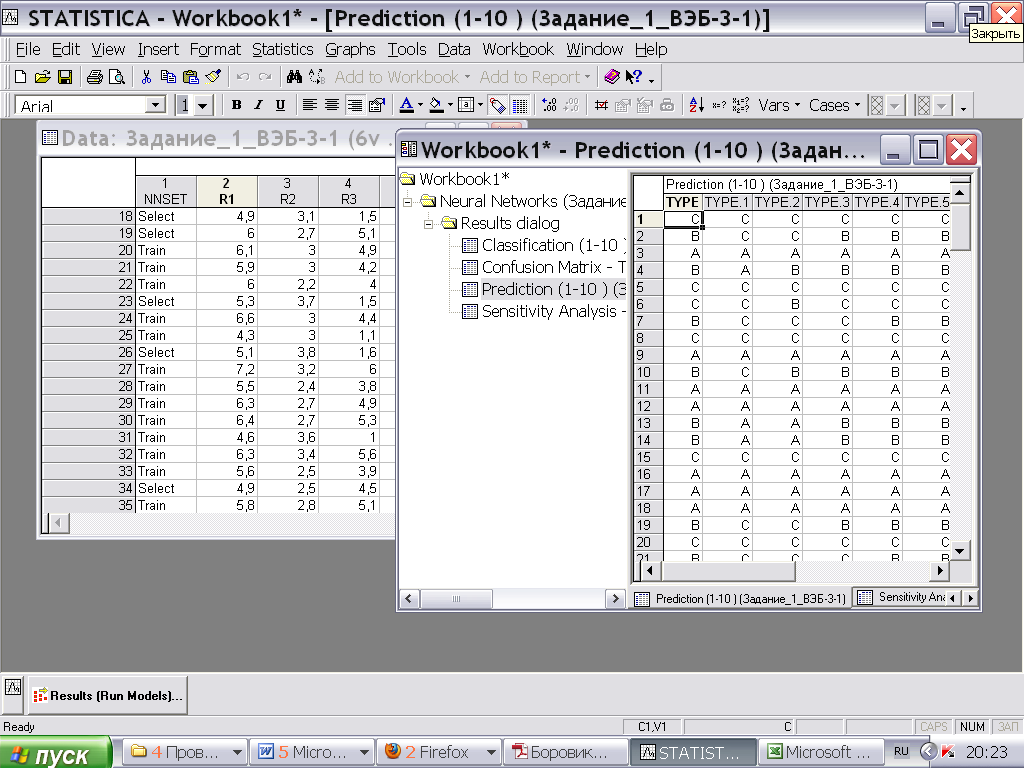
2)Вкладка Predictions (предсказание):
- Строки – какие классы должны получиться
- Столбцы – какие классы предсказала сеть в разных моделях
4)Вкладка Sensitivity analysis (Чувствительность сети к входным переменным).
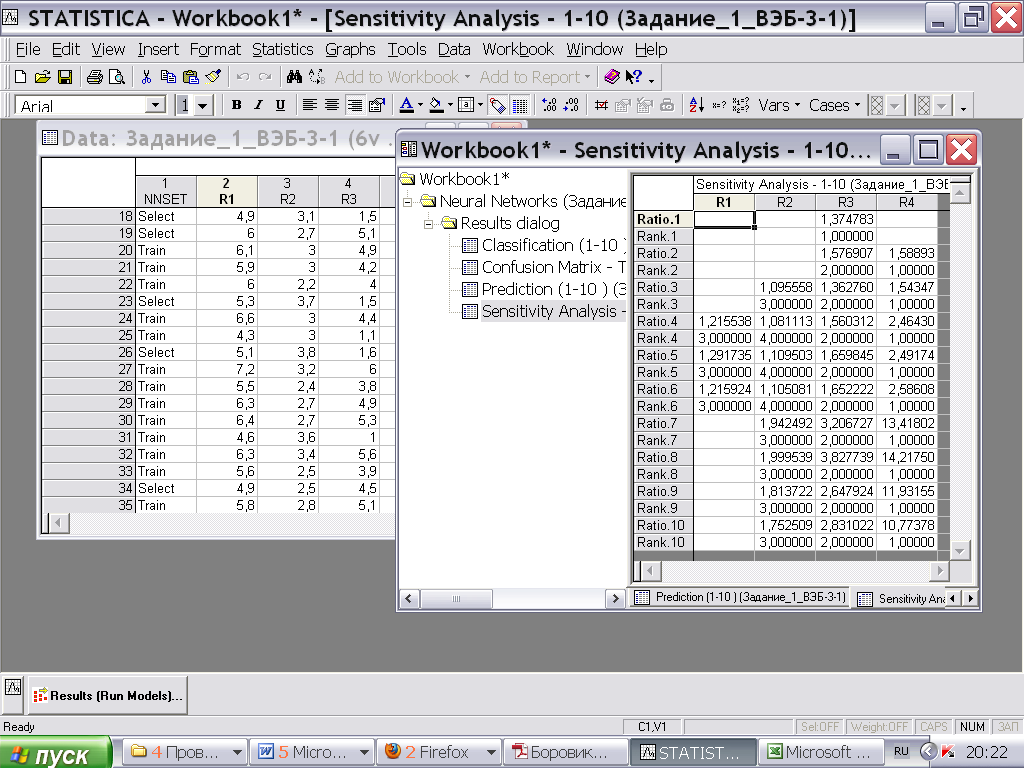
Позволяет сделать вывод об относительной важности входных переменных для конкретной НС (окно Результаты)
и при необходимости удалить входы с низким показателем чувствительности (Редактор моделей).
Т.е. показывает, какие переменные делают наиболее важный вклад в нейросетевую модель.
Процедура отключает каждую переменную по очереди, как если бы она была недоступна для анализа.
Общая ошибка сети с отключенной переменной делится на ошибку сети с включенной переменной, и полученное значение сравнивается с 1.0;
если оно больше 1, то переменная вносит вклад в решение задачи,
если меньше либо равно 1, то переменная либо не влияет, либо даже ухудшает производительность сети.
Столбцы – входные переменные.
Строки:
Для каждой входной переменной и каждой модели выводится 2 значения:
- Отношение = Общая ошибка сети с отключенной переменной делится на ошибку сети с включенной переменной
- ранговый порядок этих ошибок (чем больший вклад вносит переменная в рез-т, тем выше её ранг) для каждого входа, что позволяет расположить входные переменные в порядке значимости
Если величина ошибки равна 1 или меньше, то нейронная сеть функционирует лучше без удаленной переменной - значит соответствующую переменную можно исключить из анализа.
Анализ чувствительности не позволяет надежно определить "полезность" переменных в абсолютной шкале, и все выводы об их важности нужно делать с осторожностью.
Если исследуется целый ряд моделей, то имеет смысл выделить ключевые переменные, которые всегда важны и имеют высокий показатель чувствительности,
определить переменные с низкой чувствительностью и получить информацию о "сомнительных" переменных, которые меняют свой рейтинг и, возможно, содержат избыточную информацию.