

Числовые интервалы шкалы Харрингтона
|
Лингвистическая оценка |
Интервалы значений функции желательности d(x) |
|
Очень хорошо |
1,00-0,80 |
|
Хорошо |
0,80-0,63 |
|
Удовлетворительно |
0,63-0,37 |
|
Плохо |
0,37-0,20 |
|
Очень плохо |
0,20-0,00 |
При таком шкалировании значения функции желательности d(x) изменяются в интервале от 0 до 1, причем значение di0 соответствует абсолютно неприемлемой величине i-го показателя качества жизни, di1 – идеальной величине.
Практически часто ограничиваются тремя градациями шкалы Харрингтона, отвечающим лингвистическим категориям «плохо», «удовлетворительно», «хорошо». В этом случае область, соответствующая уровню «удовлетворительно», расширяется от 0,37 до 0,69, а области «плохо» и «хорошо» характеризуются интервалами (0,00-0,37) и (0,69-1,00) соответственно.
Аналитически для монотонных по предпочтениям критериев, характерных, например, для показателей качества жизни, функция желательности Харрингтона задается следующей формулой:
di = d (zi) = exp (-exp (-zi)), (1.3)
zi = (хi – хi0)/( хi1 – хi0), (1.4)
где zi – кодированные значения i-го показателя, представляющие собой безразмерные величины; хi – значение i-го информативного показателя; хi0 и хi1 – границы области «удовлетворительно» в исходной шкале:
di0 = d (zi (хi0)) = 0,37; di1 = d (zi (хi1)) = 0,69. (1.5)
Функция желательности Харрингтона представляет собой монотонно возрастающую функцию, изменяющуюся от 0 до 1.
При кодированном значении информативного показателя z=0 (нижняя граница области «удовлетворительно») функция желательности принимает значение 0,368, при z=1, т.е. нижняя граница области «удовлетворительно», d(z)=0,692. Для ее построения достаточно, чтобы эксперты указали границы исходных показателей хi0 и хi1, внутри которых качество жизни можно считать удовлетворительным. В частности, можно эти значения положить равными хi1=хmax и хi0=хmin, т.е. соответственно максимальному и минимальному значению показателя по массиву региональных данных.
Приведем пример. Максимальная величина показателя «Число студентов на 1000 населения» в 1998 г. по выборке регионов Центрального федерального округа, исключая данные для г. Москвы, наблюдалась для Орловской области: хmax=26,9, минимальная хmin=12,2 – для Владимирской. Принимая вышеприведенное определение границ области «удовлетворительно», получаем: хi1=26,9 и хi0=12,2. Тогда безразмерная переменная z будет представлять собой не что иное, как определенный по методике Программы развития ООН, модифицированной для регионов, индекс образования, вычисляемый по формуле:
индекс = (х – хmin)/( хmax – хmin), (1.6)
где х – значение информативного показателя для региона; хmax и хmin – соответственно максимальное и минимальное значения показателя по массиву региональных данных.
Значения функции желательности для Владимирской и Орловской областей примут значения d(z)=0,368 и 0,692 соответственно. В то же время для Москвы как субъекта Федерации, для которой безразмерная переменная z=4,21, функции желательности составляет d(4,21)=0,985 – значение, достаточно близкое к единице.
На рис. 1.2 представлены результаты сопоставления значений частного индекса образования и соответствующих величин функции желательности для регионов ЦФО, включая г. Москву (метки регионов проставлены лишь для некоторых из них).
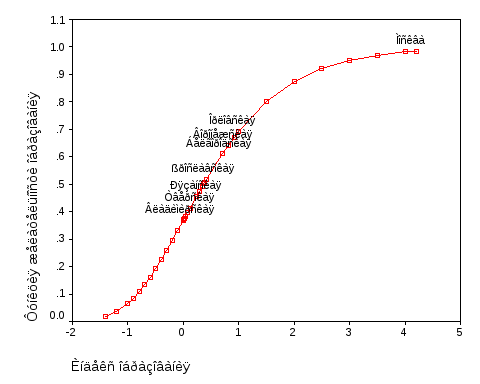
Рис. 1.2. Функция желательности Харрингтона для индекса образования
Из рис. 1.2 видно, что значения индекса образования практически линейно связаны с реально достижимыми величинами функции желательности, отвечающими интервалу значений индекса образования от 0 до 1, и лишь выше и существенно ниже интервала «удовлетворительно» четко просматривается нелинейность этой взаимосвязи. Заметим также, что крутизна зависимости функции желательности от индекса образования в области «плохо» заметно больше крутизны кривой в области «хорошо». Этот факт является отражением математических свойств функции Харрингтона, важных в аспекте ее использования в целях управления.
Введение шкалы желательности позволяет свести исходную многокритериальную задачу принятия решения с разноразмерными критериями к многокритериальной задаче с критериями, измеряемыми в одной и той же шкале, поэтому следующим этапом является свертка частных функций желательности di в обобщенный критерий D.
Обобщенный критерий рекомендуется выбирать из семейства средних по Колмогорову, задаваемых монотонными функциями . Выбор этих функций осуществляется с привлечением суждений экспертов о связи обобщенного критерия с величинами частных функций желательности. Так, логично предположить, что совершенно неудовлетворительная ситуация по одному критерию (di0) влечет за собой неудовлетворительную оценку ситуации в целом (D0). В математической форме это суждение находит свое отражение с помощью функций вида:
1 = ln d, (1.7)
2 = -ln (-ln d), (1.8)
Соответствующие обобщенные критерии равны среднему геометрическому
D1 = DG = exp (1/n* ln di) = (d1 d2 … dn)1/n, (1.9)
и среднему логарифмическому
D1 = DL = exp [-(-ln d1) (-ln d2)… (-ln dn)1/n] . (1.10)
Если частные критерии неравноценны, то их весовые коэффициенты различны между собой, и обобщенные критерии имеют следующий вид:
D1 = DG = exp (1/n* ln di) = d11 d22 … dnn, (1.11)
D1 = DL = exp [-(-ln d1)1 (-ln d2)2… (-ln dn)n] . (1.12)
Сравнение критериев DG и DL показывает, что обобщенный критерий DG дает более жесткую оценку, чем DL: DG DL во всей области определения частных функций желательности.
Помимо выбора вида свертки частных функций желательности в обобщенный критерий, важной задачей является назначение весовых коэффициентов. Один из эффективных методов экспертного оценивания весов – метод аналитических иерархий, логические и алгоритмические основы которого будут рассмотрены в cледующем разделе.
В эмпирической социологии преимущественно применяются два типа шкал – номинальная и порядковая. Примеры переменных, измеренных в номинальной шкале – пол, место проживания, факультет обучения и т.п., измеренных в порядковой шкале – возраст, степень предпочтения (одобряю; скорее одобряю, чем не одобряю; скорее не одобряю, чем одобряю; не одобряю), оценки в баллах и т.п. Следует предостеречь от естественного желания исследователей «усилить» информативность порядковых переменных. Так, довольно часто оценки в баллах, которые принципиально измерены в порядковой шкале, считают измеренными в количественных шкалах и производят над ними арифметические действия, что, по крайней мере, некорректно с точки зрения теории измерений.
Таким образом, шкалы измерения переменных в эмпирической социологии, как правило, малоинформативны, что не позволяет производить над переменными большинство преобразований. Однако имеется реальная возможность от исходных переменных перейти к переменным, измеренным в абсолютной шкале. Речь идет о вероятностях тех или иных вариантов ответов респондентов, оцениваемых по их частостям.
Рассмотрим технику такого перехода на примере разработки модели здоровья населения орловского региона [158]. В качестве эмпирической базы моделирования использовались результаты социологических исследований «Изучение отношения населения Орловской области к своему здоровью», которые охватывали население города Орла и Орловской области, а в качестве инструмента количественного представления данных и моделирования – пакет анализа данных общественных наук SPSS Base. Общий объем выборки составил 793 респондента, из них 492 – проживающих в г. Орле, 301 – в Орловской области. При моделировании факторов здоровья особое внимание уделялось гендерному аспекту данной проблемы, и в этой связи модели разрабатывались отдельно для мужского и женского населения Орловского региона.
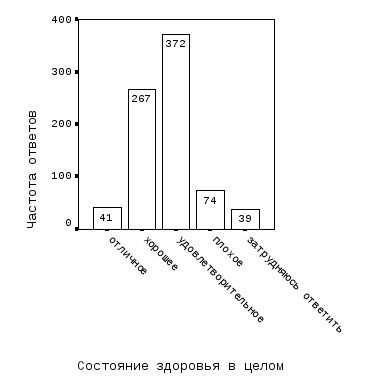
Выше отмечалось, что наиболее информативными являются данные, измеренные на абсолютной шкале. Применительно к социологическим опросам данными, измеренными на абсолютной шкале, являются частости тех и иных вариантов ответов респондентов. Как правило, при обработке данных социологических опросов строят так называемые «линейки распределения», которые представляют как в частотах, так и в частостях (процентах). Пример таких «линеек» приведен на рис. 1.2. В этом примере речь идет о частостях каждого из пяти вариантов ответов в целом по выборке, однако, переходя к генеральной совокупности (всему населению орловского региона), их можно интерпретировать как вероятности оценки населением своего здоровья как «отличное», «хорошее» и т.д. Далее, при построении таблиц сопряженности можно получить оценки этих вероятностей для групп населения, различающихся по статусным и иным признакам. А это – уже переход к переменным, измеренным на абсолютной шкале постольку, поскольку вероятность определена на множестве [0, 1], или, если выражать вероятность в процентах, на множестве [0, 100%].
|
а |
б |
|
|
|
|
Рис. 1.2. Оценка респондентами состояния здоровья в целом: а – частота; б – частость ответов |
|

При формировании подобных переменных, однако, существуют определенные ограничения, вызванные ограниченным объемом выборки. Продемонстрируем эти ограничения на конкретном примере построения количественной переменной, отражающей здоровье мужского населения орловского региона. Задача формулируется следующим образом: построить модель, отражающую влияние двух статусных признаков – группы возраста и уровня доходов – на вероятность хорошего здоровья населения.
Решение сформулированной выше задачи требует выполнения следующих этапов: 1) укрупнение категорий статусных признаков базы данных социологических опросов с целью выравнивания частот категорий; 2) выбор результативной переменной, отражающей хорошее здоровье населения; 3) создание таблицы сопряженности двух статусных признаков, укрупнение их категорий с целью выравнивания частот по ячейкам таблицы; 4) определение значений результативной переменной для групп респондентов, соответствующих ячейкам таблицы сопряженности.
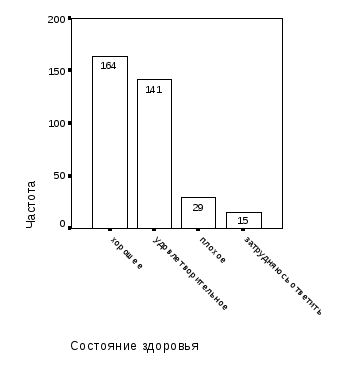
Необходимость реализации первого и третьего этапа построения модели определяется требованием к надежности оценок вероятностей. Простой пример – если мы располагаем подвыборкой респондентов мужского пола объемом n=349, то при восьми исходных возрастных групп на каждую из них приходится в среднем около 44 респондентов. Из них отличным и хорошим здоровьем обладают 164 респондента, т.е. на каждую возрастную группу приходится уже не 44, а только 20 «статистических единиц». А если учесть градацию респондентов еще и по шести группам доходов, то на одну «ячейку» таблицы сопряженности в среднем «придется» в среднем всего лишь по 3-4 респондента. Понятно, что надежность оценки вероятности отличного и хорошего здоровья мужского населения Орловского региона при этом невысока.
Приведем технологию создания эмпирической базы для построения модели хорошего здоровья мужского населения Орловского региона.
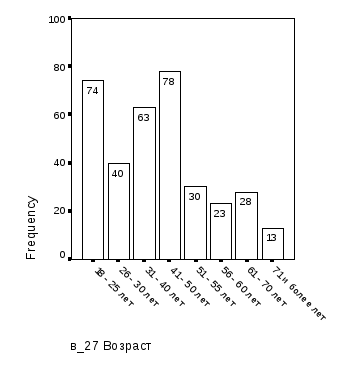
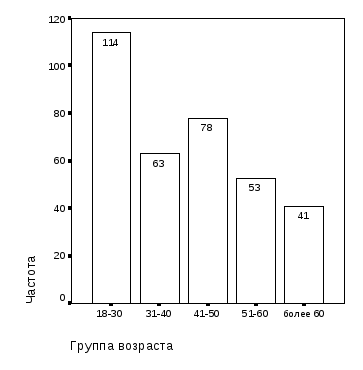
Первый этап – укрупнение категорий статусных признаков базы данных социологических опросов с целью выравнивания частот категорий – выполняется путем анализа «линеек» распределения респондентов по этим признакам. Так как в исходной базе данных имеются категории признаков «Возраст» и «Уровень доходов» с малыми частотами, устанавливаем, помимо существующих, новые категории возраста: «18-30»=«18-25 лет»+«26-30 лет», «51-60»=«51-55 лет»+«56-60 лет», «более 60»=«61-70 лет»+«71 и более лет» и новые категории уровня доходов: «до 2000»=«до 1000 руб.»+«1001-2000 руб.».
Результаты представлены на рис. 1.3 и 1.4.
|
Существующая градация |
Предлагаемая градация |
|
|
|
|
Рис. 1.3. Градация признака «Группа возраста» (мужчины) |
|
|
Существующая градация |
Предлагаемая градация |
|
|
|
|
Рис. 1.4. Градация признака «Уровень доходов» (мужчины) |
|
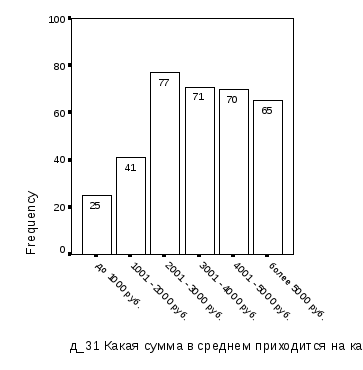
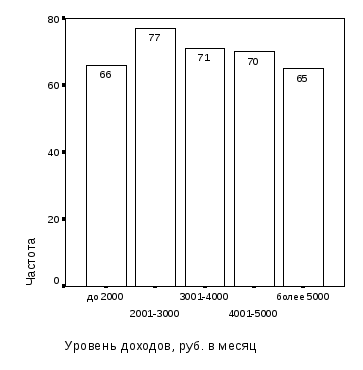
Из сравнения диаграмм рис. 1.3 и 1.4 следует, что предлагаемая градация признаков «Группа возраста» и «Уровень доходов» обеспечивает более равномерное распределение частот по категориям: минимальная наполненность категорий признака «Группа возраста» – 41 респондент мужского пола вместо 13, признака «Уровень доходов» – 65 респондентов мужского пола вместо 25.
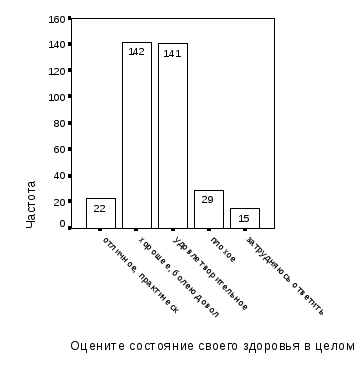
Следующий этап – выбор результативной переменной. На основании анализа базы данных в качестве результативного признака, отражающего здоровье населения, принимаем признак «Состояние здоровья», соответствующий вопросу анкеты «Оцените состояние своего здоровья в целом». Поскольку категория «Отличное, практически не болею» малонаполненная, включаем ее в категорию «Хорошее, болею довольно редко» и даем новой категории название «Хорошее» – рис. 1.5.
В соответствие с теорией статистических выводов, суммарная частость выбора респондентами мужского пола вариантов ответов «Отличное, практически не болею» и «Хорошее, болею довольно редко» интерпретируется как вероятность хорошего здоровья всего мужского населения Орловского региона.
|
Существующая градация |
Предлагаемая градация |
|
|
|
|
Рис. 1.5. Градация результативного признака «Состояние здоровья» (мужчины) |
|
Третий этап предполагает построение таблицы сопряженности признаков «Уровень доходов» – «Группа возраста» – табл. 1.2.
Таблица 1.2