

Yuristy_magistry_statistika / моно_2012_Шуметов_Крюкова / Добавление / Анти_Герасенко
.doc
МЕТОДОЛОГИЧЕСКИЕ АСПЕКТЫ МНОГОМЕРНОГО СТАТИСТИЧЕСКОГО АНАЛИЗА: ТЕОРИЯ И ПРАКТИКА
В.Г. Шуметов, доктор экономических наук,
Орловская региональная академия государственной службы,
Казалось бы, роль методов статистического анализа данных в научных исследованиях не подлежит сомнению. Однако, возникает вопрос: насколько корректно эти методы используются на практике. Распространение среди исследователей «мощных» программ статистического анализа данных, таких как Statistica, SPSS, предоставило широкие возможности использования самых разнообразных статистических процедур – корреляционно-регресионного, факторного, кластерного, дискриманантного анализа. Имеются прекрасные книги, в которых дана не только теория, но и методика применения этих методов [1-3]. Однако практика показывает, что использование исследователями весьма эффективных статистических процедур, при формальном подходе, не только приводит к ошибочным выводам, но и наносит ощутимый вред статистической методологии.
К сожалению, анализ работ, опубликованных в последних номерах журнала «Вопросы статистики» за 2004 год, демонстрирует явно недостаточный уровень понимания сути статистического метода некоторыми исследователями, претендующими на высокое право публикации в столь уважаемом издании. Не претендуя на широкие обобщения, обратимся, в качестве конкретного примера, к публикации [4] в ноябрьском номере журнала. – Cсылки не верны!
Автор публикации [4] охватил широкий круг проблем. Здесь и методологические аспекты постановки задач, и проблема классификации, и анализ факторов развития человеческого потенциала, и статистическое моделирование на основе регрессионного анализа. Первые три проблемы изложены конспективно, что не позволяет «реконструировать» исходные данные, поэтому в данной публикации остановимся только на последней задаче – построении регрессионной модели, отражающей зависимость уровня рентабельности региона Белоруссии от определяющих факторов: доли занятого экономически активного населения, структуры уровня образования населения, соотношения начисленной среднемесячной заработной платы и минимального потребительского бюджета, уровня безработицы и доли расходов на оплату труда в себестоимости. Не подвергая сомнению рациональность выбора именно этого набора показателей (это является предметом отдельного обсуждения), рассмотрим методологические ошибки и неточности, относящиеся к предмету общей теории статистики.
1. Общеизвестно, что в регрессионную модель в качестве предикторов не могут быть включены сильно коррелирующие переменные. Эффект мультиколлинеарности, вероятность проявления которого значительно возрастает при значениях коэффициента корреляции между переменными более 0,8 (по модулю), может кардинально исказить интерпретацию коэффициентов регрессионной модели [6].
Автор не утруждает себя проверкой коррелированности исходных предикторов, в то время как корреляционный анализ показывает, что в модель не могут быть включены одновременно такие переменные, как доли занятого экономически активного населения и уровень безработицы, с одной стороны, и все без исключения показатели структуры уровня образования, в сумме равные единице, с другой (табл. 1): коэффициент корреляции между уровнем занятости и уровнем безработицы составляет величину -0,969, а доля лиц со средним и «базовым» образованием (с неполным средним образованием), коррелирует с долей лиц с высшим образованием с коэффициентом линейной корреляции, соответственно, -0,899 и -0,803.
Тем самым, в уравнение регрессии принципиально не могут быть включены все восемь выбранных автором переменных.
Обращает также на себя внимание тот факт, что выбранный автором результативный признак – уровень рентабельности – довольно слабо коррелирует практически со всеми входными переменными: наибольшее по абсолютной величине значение коэффициент корреляции уровень рентабельности составляет с долей лиц со специальным профессиональным образованием, а также с долей оплаты труда в себестоимости (-0,520 и -0,259 соответственно – табл. 1).
Таблица 1
Корреляционная матрица показателей развития человеческого потенциала по регионам Белоруссии (1998-2001 гг.)
|
Показатель, обозначение |
y |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
x8 |
|
Рентабельность, y |
1,000 |
0,053 |
0,204 |
-0,520 |
-0,126 |
0,027 |
0,122 |
-0,122 |
-0,259 |
|
Занятость населения, x1 |
0,053 |
1,000 |
0,608 |
-0,736 |
-0,425 |
-0,427 |
0,478 |
-0,969 |
0,598 |
|
Доля лиц с высшим образованием, x2 |
0,204 |
0,608 |
1,000 |
-0,551 |
-0,899 |
-0,803 |
0,824 |
-0,572 |
0,183 |
|
Доля лиц со специальным профессиональным образованием, x3 |
-0,520 |
-0,736 |
-0,551 |
1,000 |
0,293 |
0,305 |
-0,440 |
0,801 |
-0,363 |
|
Доля лиц со средним общим образованием, x4 |
-0,126 |
-0,425 |
-0,899 |
0,293 |
1,000 |
0,556 |
-0,654 |
0,398 |
0,019 |
|
Доля лиц с с «базовым» образованием, x5 |
0,027 |
-0,427 |
-0,803 |
0,305 |
0,556 |
1,000 |
-0,802 |
0,335 |
-0,264 |
|
Отношение зарплаты к минимальному потребительскому бюджету, x6 |
0,122 |
0,478 |
0,824 |
-0,440 |
-0,654 |
-0,802 |
1,000 |
-0,403 |
0,439 |
|
Уровень безработицы, x7 |
-0,122 |
-0,969 |
-0,572 |
0,801 |
0,398 |
0,335 |
-0,403 |
1,000 |
-0,553 |
|
Доля оплаты труда в себестоимости, x8 |
-0,259 |
0,598 |
0,183 |
-0,363 |
0,019 |
-0,264 |
0,439 |
-0,553 |
1,000 |
2. Современные программы анализа данных позволяют проводить отбор переменных, входящих в регрессионную модель, и в автоматическом режиме, без предварительного корреляционного анализа. Мы не сторонники подобного формализованного подхода, поскольку отбор предикторов, на наш взгляд, необходимо выполнять, прежде всего, с учетом их информативности. Например, из пары коррелирующих показателей «уровень занятости – уровень безработицы» предпочтительнее использовать предиктор «уровень безработицы», поскольку коэффициент вариации этого показателя значительно превышает аналогичную характеристику для уровня занятости (196 и 0,56 % соответственно).
Пакет программ анализа данных общественных наук SPSS, использованный автором для кластерного анализа, позволяет выполнить отбор переменных, входящих в регрессионную модель, в автоматическом режиме [7]. Нами выполнена «реконструкция» регрессионного анализа по данным табл. 8 работы [4], предварительно «очищенным» от имеющихся в них ошибок (уровень занятости населения для одного из наблюдений превышает 100 %, сумма составляющих структуры уровня образования в нескольких случаях не равна 100 %). Результатом явилась следующая регрессионная модель:
y = 29,122 – 1,132 x3 + 1,468 x7 – 0,252 x8, (1)
где x3 – доля лиц со средним профессиональным образованием, %; x7 – уровень безработицы, %; x8 – доля оплаты труда в себестоимости, %. Данная модель объясняет 59,2 % дисперсии и характеризуется стандартной ошибкой аппроксимации 0,92 %, что отвечает средней погрешности предсказания 23,8 %.
Полученная модель существенно отличается от модели, приведенной в работе [4]:
y = -5,084 + 0,083 x1 + 0,199 x2 – 0,910 x3 + 0,233 x4 + 0,463 x5 + 0,023 x6 +
+ 1,317 x7 – 0,288 x8 , (2)
где, в дополнении к предыдущим, присутствуют новые предикторы: x1 – уровень занятости населения, %; x2 – доля лиц с высшим образованием, %; x4 – доля лиц со средним общим образованием, %; x5 – доля лиц с неполным средним образованием, %; x8 – доля оплаты труда в себестоимости, %. Следует, тем не менее, отметить, что знаки коэффициентов регрессии при предикторах x3, x7 и x8 обеих моделей совпадают. Расчет показывает, что обе модели дают близкие результаты прогноза значений уровня рентабельности. Данных по точности аппроксимации модели (2) в работе [4] не приводятся, указывается лишь, что она объясняет 63,8 %, что не на много превышает значение 59,2 % для модели (1). Однако, если даже допустить, что модель (2) является корректной, ей следует предпочесть, как более простую, модель (1).
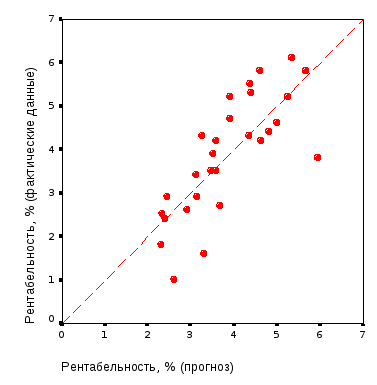
С формальной точки зрения, модель (1) является адекватной (остатки распределены по закону, близкому к нормальному, критерий Фишера значим на уровне не хуже 0,0005), но ее прогностические свойства, как и модели (2), оставляют желать лучшего, о чем свидетельствует рис. 1, представляющий взаимосвязь предсказанных и фактических значений рентабельности.
|
|
|
Рис. 1. Взаимосвязь предсказанных и фактических значений рентабельности |
3. Сравнение приоритетов изучаемых факторов по степени их влияния на результативный признак непосредственно по величине коэффициентов регрессии можно проводить лишь в некоторых частных случаях. В общем случае для этого необходимо рассчитывать коэффициенты эластичности, либо, что проще, сравнивать бета-коэффициенты, нормированные на величину стандартных отклонений соответствующих переменных. Поэтому интерпретация в работе [4] коэффициентов регрессии как «сравнительная сила влияния факторного признака на рентабельность региона» не является обоснованной. Как следует из значений бета-коэффициентов модели (1), наибольшее влияние на рентабельность оказывает не уровень безработицы, а доля лиц со средним специальным образованием: с повышением этого показателя уровень рентабельности уменьшается. На втором месте по значимости находится уровень безработицы, причем ее рост сопровождается увеличением уровня рентабельности. На третьем месте по значимости – доля оплаты труда в себестоимости продукции, увеличение которой сопровождается снижением уровня рентабельности.
4. Выявление статистических закономерностей не является основанием для содержательных выводов: наличие корреляции не означает наличия причинной связи. Казалось бы, это – аксиома, которую не следует даже напоминать. Тем не менее, в работе [4] приводится экономическое обоснование каждого коэффициента регрессии модели (2). Так, увеличение уровня рентабельности с ростом безработицы объясняется тем, что «уменьшение численности слабо занятых работников способствует повышению рентабельности» (видимо, имеется в виду переход скрытой безработицы в официально регистрируемую?), а положительный знак коэффициента регрессии при предикторе x5 – «доля лиц с неполным средним образованием» – связывается с тем, что «повышение образования работников с уровня начального общего (4 класса) до базового всеобщего (9 классов) способствует повышению рентабельности» и т.п.
Мы оставляет в стороне объяснение выявленных статистических закономерностей не только по вышеназванной причине, но еще и потому, что обсуждаемая модель получена на весьма ограниченных данных: наблюдения охватывают семь регионов, а период наблюдений – четыре года, с 1998 по 2001 г. включительно. Использование такого приема увеличения объема выборки, в принципе, возможно, но при этом увеличивается опасность получения смещенных оценок коэффициентов регрессии из-за коррелированности данных во времени.
Редакция журнала «Вопросы статистики» имеет хорошую традицию публикации обстоятельных работ, посвященных уточнению методологии и методов анализа. Таковы, например, статьи М.М. Юзбашева, в которых обращается внимание на правильность терминологии в статистике и эконометрике [8], уточняется методика расчета объема выборки для надежного установления связи [9]. Хочется надеяться, что эта традиция не только будет продолжена в дальнейшем, но и дополнена новой – критическим анализом публикаций, содержащих методологические ошибки и неточности. Учитывая широкую читательскую аудиторию журнала, статьи, содержащие подобный критический анализ, будут способствовать повышению научного уровня российских исследователей, применяющих в своей деятельности статистические методы.
Литература
-
Шуметов В.Г. Статистика и статистические методы в познании социальных процессов: региональный аспект // Региональная политика как фактор стабилизации и устойчивости развития. Матер. круглого стола. Под ред. Ю.С. Васютина, В.С. Огневой, О.И. Федорищевой. – Орел: ОРАГС, 2000.
-
SPSS Base 8.0 для Windows. Руководство пользователя. — М.: СПСС Русь, 1998; SPSS Base 8.0 для Windows. Руководство по применению. – М.: СПСС Русь, 1998.
-
Neural Connection 2.0 User’s Guide. — Chicago, SPPS Inc. and Recognition Systems Inc., 1997; Neural Connection 2.0 Application Guide. – Chicago, SPPS Inc. and Recognition Systems Inc., 1997.
-
Шуметов В.Г., Кузнецов А.И. Алгоритмы и пользовательский интерфейс системы поддержки принятия решений Expert Decide // Интеллектуальные системы: Труды Четвертого межд. симп. – М.: МГТУ, 2000.
-
Саати Т. Принятие решений. Метод анализа иерархий. – М.: Радио и связь, 1993.
-
Шуметов В.Г. Классификация многокритериальных задач, решаемых с помощью экспертной компьютерной системы поддержки принятия решений Expert Decide // Компьютерные технологии в обучении и научных исследованиях. Сб. статей и докл. н.-метод. конф. ОрелГАУ. – Орел: ОрелГАУ, 1999.
-
Шуметов В.Г. Прогнозирование социального поведения на региональном уровне: экспертные методы и системы. – Орел: ОРАГС, 2001.
-
Васютин Ю.С., Шуметов В.Г. Федеральные и региональные структуры управления: проблемы взаимодействия и соотношения // Политические трансформации в условиях становления российской государственности: история, теория и современная практика. – Орел: ОРАГС, 1998.
-
Шуметов В.Г. Кластерный анализ в региональном управлении: учебное пособие. — Орел: ОРАГС, 2001.
-
Кузнецов А.И., Шуметов В.Г. Expert Decide для Windows 95, 98, NT, 2000, Ме. Версия 2.2. Руководство пользователя. – Орел: ОРАГС, 2001.
-
Уварова В.И., Шуметов В.Г., Афонина Т.Н., Иваненко Т.А. Социально-психологическая и профессиональная адаптация студентов вузов Центрального региона России (по материалам социологического исследования) / Под ред. В.И. Уваровой. – Орел: ОрелГАУ, 2001.
-
Шуметов В.Г. О научной студенческой работе по направлению «Математическое моделирование в социологии» // Образование и общество. – 2001. – №5(11).
-
Моделирование и прогнозирование социально-политических и экономических явлений и процессов: региональный аспект. Материалы круглого стола. – Орел: ОРАГС, 2002.