

3. Программная реализация
При рассмотрении вышеописанной модели функционирования биологической нейронной сети в данной работе использовалась программная система Neuronet 2.x , написанная аспирантом Биологического факультета ННГУ Сергеем Лобовым на языке C++ в межплатформенной среде разработки QT. Данная система имеет графический интерфейс, позволяющий менять конфигурацию сетей в визуально-интерактивном режиме (добавлять и удалять нейроны и их соединения, менять положение нейронов простым перетаскиванием, менять параметры отдельных нейронов). В программе также имеются инструменты для автоматической генерации сетей и установки заданных параметров, имеющих нормальное распределение. Наблюдать за активностью сети в ходе симуляции можно также визуально – значком «молния» обозначаются спайки в нейронах, цветовой насыщенностью – выходной сигнал (выброс медиатора). В виде графиков можно наблюдать изменения переменных как отдельных нейронов (трансмембранный потенциал и выходной сигнал), так и характеристики всей сети (растровая диаграмма спайков, средняя частота, частота и амплитуда пачек, гистограмма весов).
Основными объектами в программе являются нейрон, реализованный в виде абстрактного класса CNeuron, а также производных от него классов CNeuronIF и CNeuronIzh, и сеть (класс CNet). Диграмма основных классов программы представлена на рис. 3.
Рис. 3. Диаграмма основных классов программы Neuronet 2.x
Класс CNet включает в себя нейроны в виде вектора указателей vector <CNeuron*> neurons. Переменные и методы класса созданы для операций, проводимых в рамках всей сети – выгрузка-загрузка файлов конфигураций, сбор статистик, хранение общих параметров и, собственно, организация вычислений (симуляции). Вычисления осуществляются методом Calculate(), который последовательно запускает одноименные методы всех нейронов.
11
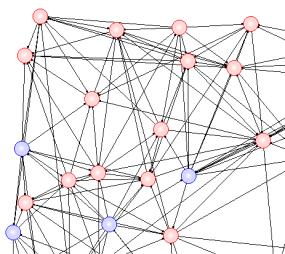
Следует отметить, что биологические нейроны имеют отростки 2-х типов – дендриты (входящие связи) и аксоны (исходящие связи), причем отростки, как правило, имеют сильное ветвление. В программе Neuronet 2.x принята упрощенная схема соединения нейронов – прямыми связями от одного нейрона к другому, которые не учитывают никакие дополнительные ветвления. То есть, с геометрической точки зрения такая сеть представляет собой граф с нейронами в узлах (рис. 4).
Рис. 4. Пример визуального представления нейронной сети в Neuronet 2.x
Межнейронные соединения представлены с помощью вектора указателей на нейроны, от которых данный нейрон получает входящие связи (vector <CNeuron*> in_neurons). Есть также вектор указателей на нейроны, получающие исходящие связи (vector<CNeuron*> to_neurons) – эти данные, по сути, являются избыточными и введены в качестве вспомогательных. Каждая связь характеризуется весом, имеющим значение от 0 до 1. Веса также представлены в виде вектора (vector <float> weights), члены которого строго соответствуют вектору in_neurons.
Каждый нейрон в программе имеет геометрические координаты (cx, cy). Так как сигнал от одного нейрона к другому должен приходить с задержкой, пропорциональной расстоянию между ними, нейрон имеет дек (deque <float> output_deque), в начало которого на каждом шаге вычислений помещается текущее значение выходного сигнала. Размер дека задается пропорциональным расстоянию до максимально удаленного нейрона и обратно пропорциональным скорости передачи импульса и временному шагу моделирования.
В программе реализована универсальная система решения дифференциальных уравнений (класс C_ODE_Solver), что позволяет использовать по желанию один из трех числовых методов решения (Эйлера, Рунге-Кутта 2-го и 4-го порядка), а также скомпоновать правые части уравнений в одном участке кода. Концептуально такая система близка к аналогичной реализации в MATLAB.
12
4.Повышение производительности вычислений
Входе анализа участков кода программной системы Neuronet 2.x, отвечающих за вычисления параметров нейронной сети, было установлено, что наиболее трудоёмкими для
каждого составляющего её нейрона являются вычисления синаптического тока Isyn , а также
вычисление изменений весов связей пресинаптических нейронов с постсинаптическим при реализации STDP. Это обусловлено наличием циклов по числу нейронов, посылающих входящие импульсы, для каждого отдельно взятого элемента нейронной сети, в то время как при моделировании кратковременной синаптической пластичности такие циклы не используются.
Поэтому вычисления синаптического тока и STDP были реализованы на CUDA и OpenCL в виде соответствующих ядер:
1.Calculate_Input_Sum – для вычисления синаптического тока,
2.STDP_first, STDP_second – для коррекции значений весов связей между пре- и
постсинапсами.
Реализация каждого из ядер приведена в Приложении.
В рамках данной работы была проведена серия вычислительных экспериментов для сравнения производительности вычислений, полученных с использованием технологий CUDA и OpenCL, с последовательной реализацией рассмотренных участков кода программы Neuronet 2.x. Эксперименты проводились на PC со следующими характеристиками:
•CPU: Intel Core 2 Duo E6750 2.66 GHz;
•GPU: NVidia GForce 8800 GTS.
Рассматривались тестовые насыщенные нейронные сети разного размера N, генерируемые случайным образом средствами программы Neuronet 2.x. Замерялось только непосредственно время вычислений, имеющих отношение к кускам кода, рассмотренным в предыдущем разделе. Для получения более точных результатов для каждого N замерялось время выполнения целой серии из 10 экспериментов, каждый из которых состоял в изменении значений выходных сигналов нейронов и их связей с другими нейронами сети. Результаты серий экспериментов приведены в Таблице 2 в расчёте на 1 нейрон. Графики результатов отображены на рис. 5.
13
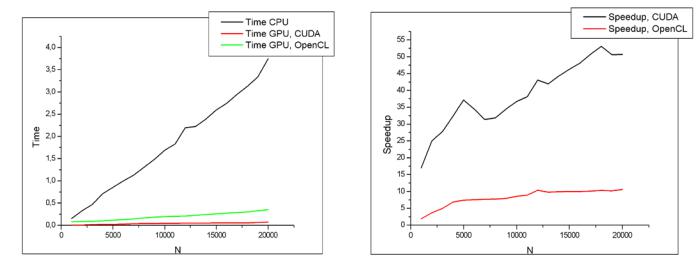
Таблица 2. Замеры времени работы реализаций в секундах
N |
Time, CPU |
Time, GPU, CUDA |
Time, GPU, OpenCL |
Speedup, CUDA |
Speedup, OpenCL |
1000 |
0.153 |
0.009 |
0.080 |
17 |
1,9125 |
2000 |
0.325 |
0.013 |
0.089 |
25 |
3,651685 |
3000 |
0.472 |
0.017 |
0.095 |
27,764706 |
4,968421 |
4000 |
0.712 |
0.022 |
0.104 |
32,363636 |
6,846154 |
5000 |
0.856 |
0.023 |
0.115 |
37,217391 |
7,443478 |
6000 |
1.000 |
0.029 |
0.132 |
34,482759 |
7,575758 |
7000 |
1.131 |
0.036 |
0.147 |
31,416667 |
7,693878 |
8000 |
1.305 |
0.041 |
0.168 |
31,829268 |
7,767857 |
9000 |
1.481 |
0.043 |
0.187 |
34,44186 |
7,919786 |
10000 |
1.690 |
0.046 |
0.197 |
36,73913 |
8,57868 |
11000 |
1.831 |
0.048 |
0.205 |
38,145833 |
8,931707 |
12000 |
2.197 |
0.051 |
0.212 |
43,078431 |
10,36321 |
13000 |
2.225 |
0.053 |
0.227 |
41,981132 |
9,801762 |
14000 |
2.391 |
0.054 |
0.241 |
44,277778 |
9,921162 |
15000 |
2.595 |
0.056 |
0.260 |
46,339286 |
9,980769 |
16000 |
2.745 |
0.057 |
0.274 |
48,157895 |
10,01825 |
17000 |
2.947 |
0.058 |
0.291 |
50,810345 |
10,12715 |
18000 |
3.131 |
0.059 |
0.304 |
53,067797 |
10,29934 |
19000 |
3.341 |
0.066 |
0.329 |
50,621212 |
10,15502 |
20000 |
3.750 |
0.074 |
0.353 |
50,675676 |
10,62323 |
а) |
б) |
Рис. 5. Графики результатов экспериментов: а) – времена, б) – ускорения
14