

2_9
 осточноукраинский
национальный университет имени Владимира
Даля
осточноукраинский
национальный университет имени Владимира
Даля
Хеширование
Информатика и компьютерная техника
© Велигура А.В., кафедра экономической кибернетики, 2004
Ранне был рассмотрен алгоритм интерполяционного поиска, который использует интерполяцию, чтобы быстро найти элемент в списке. Сравнивая искомое значение со значениями элементов в известных точках, этот алгоритм может определить вероятное положение искомого элемента. В сущности, он создает функцию, которая устанавливает соответствие между искомым значением и индексом позиции, в которой он должен находиться. Если первое предположение ошибочно, то алгоритм снова использует эту функцию, делая новое предположение, и так далее, до тех пор, пока искомый элемент не будет найден.
Хеширование(hashing) использует аналогичный подход, отображая элементы вхеш‑таблице(hashtable). Алгоритм хеширования использует некоторую функцию, которая определяет вероятное положение элемента в таблице на основе значения искомого элемента.
Например, предположим, что требуется запомнить несколько записей, каждая из которых имеет уникальный ключ со значением от 1 до 100. Для этого можно создать массив со 100 ячейками и проинициализировать каждую ячейку нулевым ключом. Чтобы добавить в массив новую запись, данные из нее просто копируются в соответствующую ячейку массива. Чтобы добавить запись с ключом 37, данные из нее просто копируются в 37 позицию в массиве. Чтобы найти запись с определенным ключом, просто выбирается соответствующая ячейка массива. Для удаления записи ключу соответствующей ячейки массива просто присваивается нулевое значение. Используя эту схему, можно добавить, найти и удалить элемент из массива за один шаг.
К сожалению, в реальных приложениях значения ключа не всегда находятся в небольшом диапазоне. Обычно диапазон возможных значений ключа достаточно велик. База данных сотрудников может использовать в качестве ключа идентификационный номер социального страхования. Теоретически можно было бы создать массив, каждая ячейка которого соответствовала одному из возможных девятизначных чисел; но на практике для этого не хватит памяти или дискового пространства. Если для хранения одной записи требуется 1 килобайт памяти, то такой массив занял бы 1 терабайт (миллион мегабайт) памяти. Даже если можно было бы выделить такой объем памяти, такая схема была бы очень неэкономной. Если штат вашей компании меньше 10 миллионов сотрудников, то более 99 процентов массива будут пусты.
Чтобы справиться с этой проблемой, схемы хеширования отображают потенциально большое число возможных ключей на достаточно компактную хеш‑таблицу. Если в вашей компании работает 700 сотрудников, вы можете создать хеш‑таблицу с 1000 ячеек. Схема хеширования устанавливает соответствие между 700 записями о сотрудниках и 1000 позициями в таблице. Например, можно располагать записи в таблице в соответствии с тремя первыми цифрами идентификационного номера в системе социального страхования. При этом запись о сотруднике с номером социального страхования 123‑45‑6789 будет находиться в 123 ячейке таблицы.
Очевидно, что поскольку существует больше возможных значений ключа, чем ячеек в таблице, то некоторые значения ключей могут соответствовать одним и тем же ячейкам таблицы. Например, оба значения 123‑45‑6789 и 12399‑9999 отображаются на одну и ту же ячейку таблицы 123. Если существует миллиард возможных номеров системы социального страхования, и таблица имеет 1000 ячеек, то в среднем каждая ячейка будет соответствовать миллиону записей.
Чтобы избежать этой потенциальной проблемы, схема хеширования должна включать в себя алгоритм разрешения конфликтов(collisionresolutionpolicy), который определяет последовательность действий в случае, если ключ соответствует позиции в таблице, которая уже занята другой записью. Рассмотрим несколько различных методов разрешения конфликтов.
Все обсуждаемые здесь методы используют для разрешения конфликтов примерно одинаковый подход. Они вначале устанавливают соответствие между ключом записи и положением в хеш‑таблице. Если эта ячейка уже занята, они отображают ключ на какую‑либо другую ячейку таблицы. Если она также уже занята, то процесс повторяется снова о тех пор, пока в конце концов алгоритм не найдет пустую ячейку в таблице. Последовательность проверяемых при поиске или вставке элемента в хеш‑таблицу позиций называется тестовой последовательностью(probesequence).
В итоге, для реализации хеширования необходимы три вещи:
1. Структура данных (хеш‑таблица) для хранения данных;
2. Функция хеширования, устанавливающая соответствие между значением ключа и положением в таблице;
3. Алгоритм разрешения конфликтов, определяющий последовательность действий, если несколько ключей соответствуют одной ячейке таблицы.
Рассмотрим некоторые структуры данных, которые можно использовать для хеширования. Каждая из них имеет соответствующую функцию хеширования и один или более алгоритмов разрешения конфликтов. Так же, как и в большинстве компьютерных алгоритмов, каждый из этих методов имеет свои преимущества и недостатки.
Связывание
Один из методов разрешения конфликтов заключается в хранении записей, которые занимают одинаковое положение в таблице, в связных списках. Чтобы добавить в таблицу новую запись, при помощи функции хеширования выбирается связный список, который должен его содержать. Затем запись добавляется в этот список.
На рис. 1 показан пример связывания хеш‑таблицы, которая содержит 13 ячеек. Функция хеширования отображает ключ Kна ячейкуKMod13 в массиве. Каждая ячейка массива содержит указатель на первый элемент связного списка. При вставке элемента в таблицу он помещается в соответствующий список.
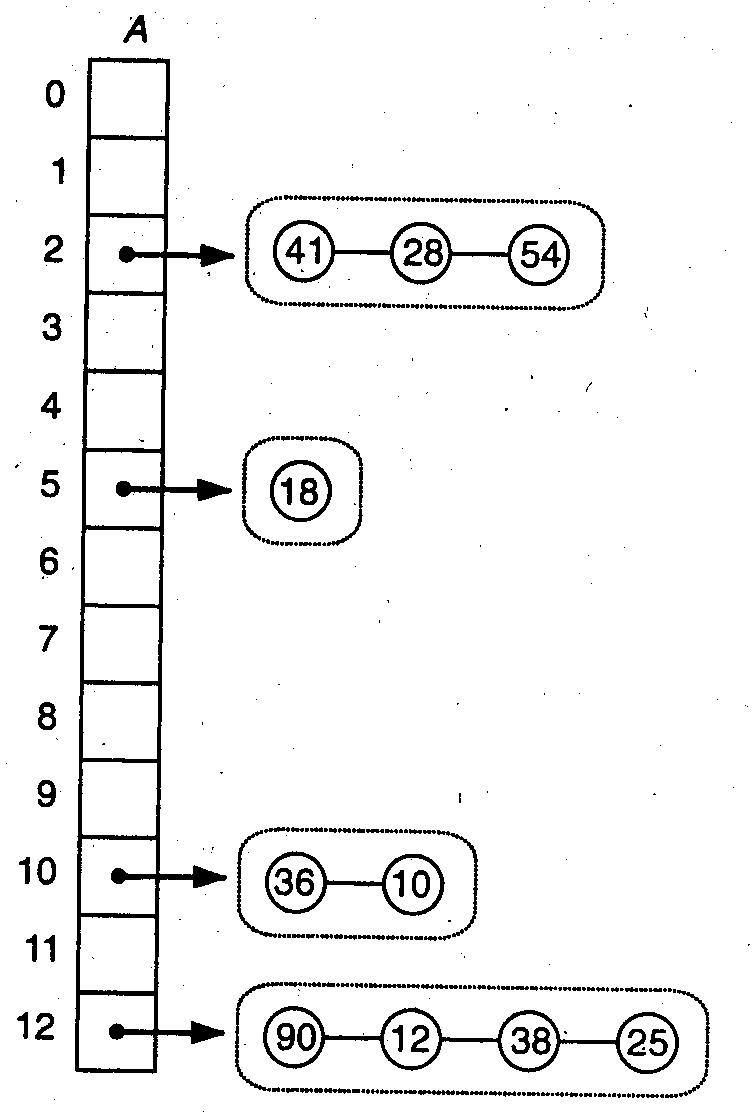
Рис. 11.1. Связывание
Чтобы создать хеш‑таблицу в VisualBasic, используйте операторReDimдля размещения сигнальных меток начала списков. Если вы хотите создать в хеш‑таблицеNumListsсвязных списков, задайте размер массиваListTopsпри помощи оператораReDim ListTops(0 To NumLists - 1). Первоначально все списки пусты, поэтому указательNextCellкаждой метки должен иметь значениеNothing. Если вы используете для изменения массива меток операторReDim, тоVisualBasicавтоматически инициализирует указателиNextCellзначениемNothing.
Чтобы найти в хеш‑таблице элемент с ключом K, нужно вычислитьK Mod NumLists, получив индекс метки связного списка, который может содержать искомый элемент. Затем нужно просмотреть список до тех пор, пока искомый элемент не будет найден или процедура не дойдет до конца списка.
Global Const HASH_FOUND = 0
Global Const HASH_NOT_FOUND = 1
Global Const HASH_INSERTED = 2
Private Function LocateItemUnsorted(Value As Long) As Integer
Dim cell As ChainCell
' Получить вершину связного списка.
Set cell = m_ListTops(Value Mod NumLists).NextCell
Do While Not (cell Is Nothing)
If cell.Value = Value Then Exit Do
Set cell = cell.NextCell
Loop
If cell Is Nothing Then
LocateItemUnsorted = HASH_NOT_FOUND
Else
LocateItemUnsorted = HASH_FOUND
End If
End Function
Функции для вставки и удаления элементов из связных списков аналогичны функциям, описанным ранее.
Преимущества и недостатки связывания
Одно из преимуществ этого метода состоит в том, что при его использовании хеш‑таблицы никогда не переполняются. При этом вставка и поиск элементов всегда выполняется очень просто, даже если элементов в таблице очень много. Для некоторых методов хеширования, описанных ниже, производительность значительно падает, если таблица почти заполнена.
Из хеш‑таблицы, которая использует связывание, также просто удалять элементы, при этом элемент просто удаляется из соответствующего связного списка. В некоторых других схемах хеширования удалить элемент непросто или невозможно.
Один из недостатков связывания состоит в том, что если число связных списков недостаточно велико, то размер списков может стать большим, при этом для вставки или поиска элемента необходимо будет проверить большое число элементов списка. Если хеш‑таблица содержит 10 связных списков и к ней добавляется 1000 элементов, то средняя длина связного списка будет равна 100. Чтобы найти элемент в таблице, придется проверить порядка 100 ячеек.
Можно немного ускорить поиск, если использовать упорядоченные списки. Тогда можно использовать для поиска элементов в упорядоченных связных списках методы, описанные в 10 главе. Это позволяет прекратить поиск, если во время его выполнения встретится элемент со значением, большим искомого. В среднем потребуется проверить только половину связного списка, чтобы найти элемент или определить, что его нет в списке.
Private Function LocateItemSorted(Value As Long) As Integer
Dim cell As ChainCell
' Получить вершину связного списка.
Set cell = m_ListTops(Value Mod NumLists).NextCell
Do While Not (cell Is Nothing)
If cell.Value >= Value Then Exit Do
Set cell = cell.NextCell
Loop
If cell Is Nothing Then
LocateItemSorted = HASH_NOT_FOUND
ElseIf cell.Value = Value Then
LocateItemSorted = HASH_FOUND
Else
LocateItemSorted = HASH_NOT_FOUND
End If
End Function
Использование упорядоченных списков позволяет ускорить поиск, но не снимает настоящую проблему, связанную с переполнения таблицы. Лучшим, но более трудоемким решением будет создание хеш‑таблицы большего размера и повторное хеширование элементов в новой таблице так, чтобы связные списки в ней имели меньший размер. Это может занять довольно много времени, особенно если списки записаны на диске или каком‑либо другом медленном устройстве, а не в памяти.
В программе Chainв архиве с примерами реализована хеш‑таблица со связыванием. Введите число списков в поле областиTable Creation(Создание таблицы) на форме и установите флажокSort Lists(Упорядоченные списки), если вы хотите, чтобы программа использовала упорядоченные списки. Затем нажмите на кнопкуCreate Table(Создать таблицу). Затем вы можете ввести новые значения и снова нажать на кнопкуCreate Table, чтобы создать новую хеш‑таблицу.
Так как интересно изучать хеш‑таблицы, содержащие большое число значений, то программа Chainпозволяет заполнять таблицу случайными элементами. Введите число элементов, которые вы хотите создать и максимальное значение элементов в областиRandom Items(Случайные элементы), затем нажмите на кнопкуCreate Items(Создать элементы), и программа добавит в хеш‑таблицу случайно созданные элементы.
И, наконец, введите значение в области Search(Поиск). Если вы нажмете на кнопкуAdd(Добавить), то программа вставит элемент в хеш‑таблицу, если он еще не находится в ней. Если вы нажмете на кнопкуFind(Найти), то программа выполнит поиск элемента в таблице.
После завершения операции поиска или вставки, программа выводит статус операции в нижней части формы — была ли операция успешной и число проверенных во время ее выполнения элементов.
В строке статуса также выводится средняя длина успешной (если элемент есть в таблице) и безуспешной (если элемента в таблице нет) тестовых последовательностей. Программа вычисляет эти значения, выполняя поиск для всех чисел между единицей и наибольшим числом в хеш‑таблице, и затем подсчитывая среднее значение длины тестовой последовательности.
На рис. 2 показано окно программы Chainпосле успешного поиска элемента 804.
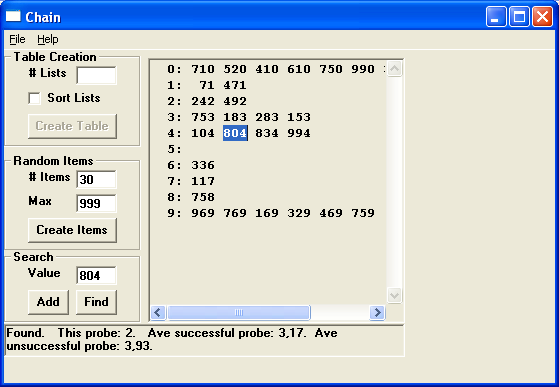
Рис. 2. Программа Chain
Блоки
Другой способ разрешения конфликтов заключается в том, чтобы выделить ряд блоков, каждый из которых может содержать несколько элементов. Для вставки элемента в таблицу, он отображается на один из блоков и затем помещается в этот блок. Если блок уже заполнен, то используется обработка переполнения.
Возможно, самый простой метод обработки переполнения состоит в том, чтобы поместить все лишние элементы в специальные блоки в конце массива «нормальных» блоков. Это позволяет при необходимости легко увеличивать размер хеш‑таблицы. Если требуется больше дополнительных блоков, то размер массива блоков просто увеличивается, и в конце массива создаются новые дополнительные блоки.
Например, чтобы добавить новый элемент Kв хеш‑таблицу, которая содержит пять блоков, вначале мы пытаемся поместить его в блок с номеромKMod5. Если этот блок заполнен, элемент помещается в дополнительный блок.
Чтобы найти элемент в таблице, вычислим KMod5, чтобы найти его положение, и затем выполним поиск в этом блоке. Если элемента в этом блоке нет, и блок не заполнен, значит элемента в хеш‑таблице нет. Если элемента в блоке нет и блок заполнен, необходимо проверить дополнительные блоки.
На рис. 11.3 показаны пять блоков с номерами от 0 до 4 и один дополнительный блок. Каждый блок может содержать по 5 элементов. В этом примере в хеш‑таблицу были вставлены следующие элементы: 50, 13, 10 ,72, 25, 46, 68, 30, 99, 85, 93, 65, 70. При вставке элементов 65 и 70 блоки уже были заполнены, поэтому эти элементы были помещены в первый дополнительный блок.
Чтобы реализовать метод блочного хеширования в VisualBasic, можно использовать для хранения блоков двумерный массив. Если требуетсяNumBucketsблоков, каждый из которых может содержатьBucketSizeячеек, выделим память под блоки при помощи оператораReDim TheBuckets(0 To BucketSize -1, 0 To NumBuckets - 1). Второе измерение соответствует номеру блока. ОператорVisualBasicReDimпозволяет изменить только размер массива, поэтому номер блока должен быть вторым измерением массива.
Чтобы найти элемент K, вычислим номер блокаK Mod NumBuckets. Затем проведем поиск в блоке до тех пор, пока не найдется искомый элемент, или пустая ячейка блока, или блок не закончится. Если элемент найден, поиск завершен. Если встретится пустая ячейка, значит элемента в хеш‑таблице нет, и процесс также завершен. Если проверен весь блок, и не найден искомый элемент или пустая ячейка, требуется проверить дополнительные блоки.
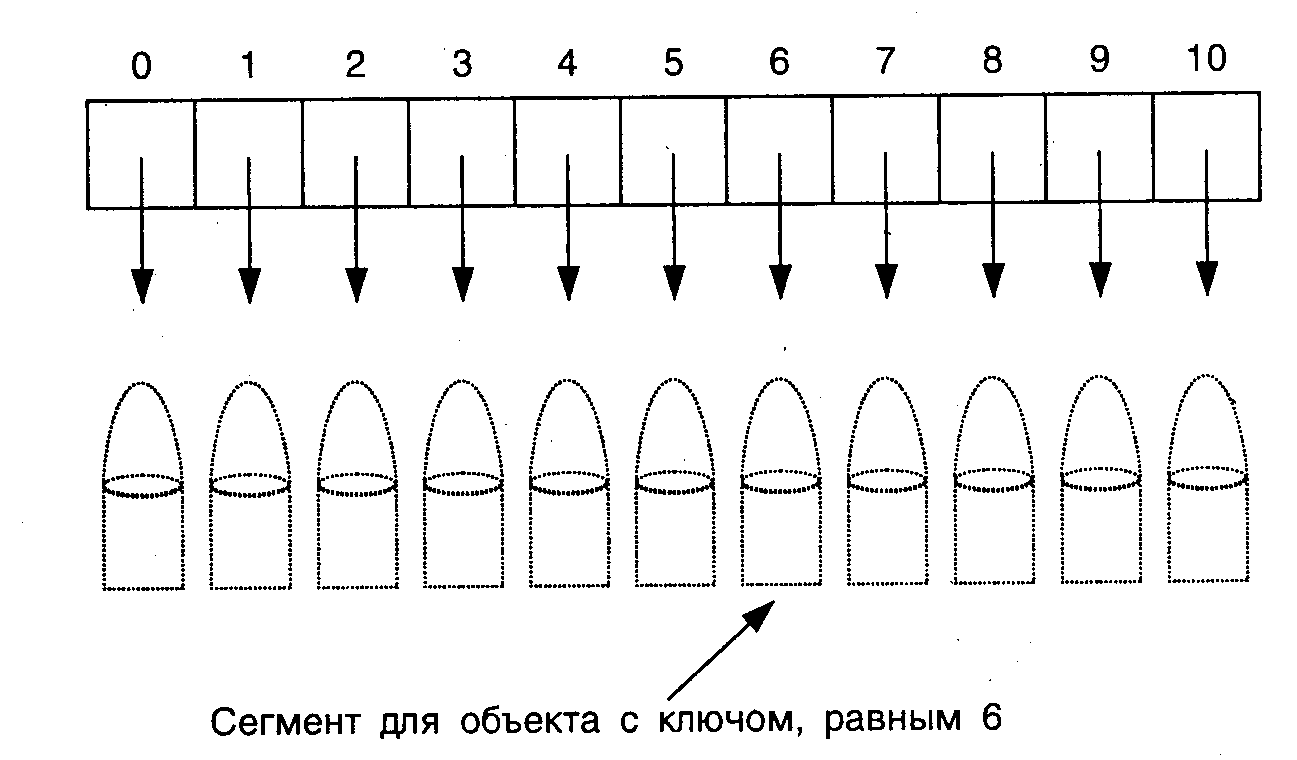
Рис. 3. Иллюстрация массива блоков
Public Function LocateItem(Value As Long, _
bucket_probes As Integer, item_probes As Integer) As Integer
Dim bucket As Integer
Dim pos As Integer
bucket_probes = 1
item_probes = 0
' Определить, к какому блоку он относится.
bucket = (Value Mod NumBuckets)
' Поиск элемента или пустой ячейки.
For pos = 0 To BucketSize - 1
item_probes = item_probes + 1
If Buckets(pos, bucket).Value = UNUSED Then
LocateItem = HASH_NOT_FOUND 'Элемент отсутствует.
Exit Function
End If
If Buckets(pos, bucket).Value = Value Then
LocateItem = HASH_FOUND 'Элемент найден.
Exit Function
End If
Next pos
' Проверить дополнительные блоки.
For bucket = NumBuckets To MaxOverflow
bucket_probes = bucket_probes + 1
For pos = 0 To BucketSize - 1
item_probes = item_probes + 1
If Buckets(pos, bucket).Value = UNUSED Then
LocateItem = HASH_NOT_FOUND ' Not here.
Exit Function
End If
If Buckets(pos, bucket).Value = Value Then
LocateItem = HASH_FOUND 'Элемент найден.
Exit Function
End If
Next pos
Next bucket
' Если элемент до сих пор не найден, то его нет в таблице.
LocateItem = HASH_NOT_FOUND
End Function
Программа Bucketв архиве с примерами демонстрирует этот метод. Эта программа очень похожа на программуChain, но она использует блоки, а не связные списки. Когда эта программа выводит длину тестовой последовательности, она показывает число проверенных блоков и число проверенных элементов в блоках. На рис. 4 показано окно программы после успешного поиска элемента 661 в первом дополнительном блоке. В этом примере программа проверила 9 элементов в двух блоках.
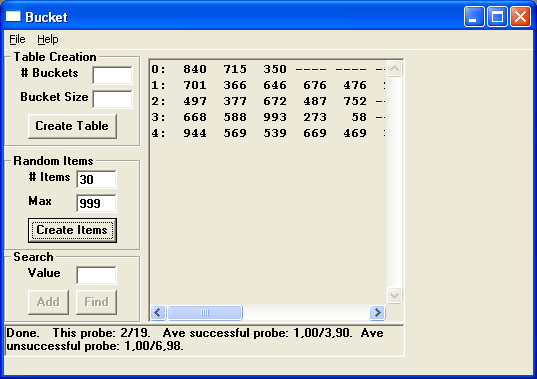
Рис. 4. Программа Bucket