

Если p{ а }q и q{ b }r, то выполняется p{ a;b }r.
или в другой форме записи
P{ А }Q и Q{ B }R

P{ A;B }R.
Т.е., если A таково, что его выполнение при верном P приводит к ситуации, в которой Q верно и выполнение B при верном Q приводит к ситуации, в которой верно R, то выполнение B вслед за A, отправляясь от ситуации, в которой верно P, приведет к конечной ситуации, где верно R.
Условие над чертой называется гипотезой, а условие под чертой – заключением. Аксиома говорит, что истинности всех гипотез достаточно для доказательства истинности заключения.
Рассмотрим пример.
Пример 3. Доказать формулу
{0 < X < 1} X:=1/X+Y; X:=X+1 {X>Y+2}.(3)
Доказательство. На основании примера 2 можно утверждать
{0<X<1} X:=1/X+Y {X>Y+1}.
Если обозначить n=Y+1, то на основании примера 1 можно заключить справедливость формулы
{X>Y+1} X:=X+1 {X>Y+2}.
Отсюда на основании аксиомы для последовательного выполнения (ведь все необходимые для аксиомы гипотезы справедливы) можно заключить справедливость формулы (3).
Аксиома ветвления.
Если B не имеет побочных эффектов, то доказательство
{P} if B then S1 else S2 {Q}
эквивалентно доказательству пары
{P&B} S1 и {P&~B} S2 {Q}
или более кратко
без побочных эффектов B, {P&B} S1, {P&~B} S2 {Q}
 .
.
{P} if B then S1 else S2 {Q}
Рассмотрим пример.
Пример 4. Доказать формулу
{(X=1) | (X=0)}
if X=1 then Y:=0 else X:=Y
{(Y=0)}
На основании аксиомы ветвления доказательство этой формулы сводится к доказательству трех условий:
без побочных эффектов (X=1);
{((X=1)|(X=0))&(X=1)} Y:=0 {(Y=0)};
{((X=1)|(X=0))&~(X=1)} Y:=X {(Y=0)};
Истинность первого условия следует из того, что операция сравнения (=) ничего не модифицирует.
Проектирование цикла с помощью инварианта Задача 1. Найти сумму величин 1/iот 1 до тех пор, пока она не станет больше некоторого наперед заданного числаa.
АНАЛИЗ ЗАДАЧИ. Прежде всего выясним, что дано (предусловие P) и, что надо получить (постусловие Q).
P: Подготовить вещественное число a.
Q: 1 + ½ + 1/3 + … + 1/i > a & 1 + ½ + 1/3 + … + 1/(i-1) a .
Разработаем стратегию решения задачи: будем последовательно накапливать n-ые частичные суммы, начиная от n=1.
СТРАТЕГИЯ РЕШЕНИЯ ЗАДАЧИ: Последовательное получение величин Sn = 1 + ½ + 1/3 + … + 1/n, начиная от n=1.
Ясно, что решение задачи будет представлять собой цикл с неопределенным количеством повторений. В этом цикле будут последовательно формироваться n-ые частичные суммы Sn. Номер частичной суммы будет определяться величиной n (параметр цикла). Сформулируем инвариант цикла.
4) ИНВАРИАНТ ЦИКЛА I: <Частичная сумма Sn> = 1 + ½ + 1/3 + … + 1/n.
Будем искать решение нашей задачи в виде цикла, имеющего следующий вид:
5) СТРУКТУРА ЦИКЛА:














ВЫХОД
Компоненты цикла будем искать, исходя из стратегии задачи и условия истинности инварианта:
А) перед первым входом в цикл;
Б) после завершения тела цикла;
В) после выхода из цикла.
Введем параметр цикла n – номер уже полученной частичной суммы. Частичную сумму обозначим переменной S. Исходя из стратегии решения задачи (суммирование от начала последовательности) присвоим n значение 0. Чтобы сохранить истинность инварианта необходимо переменной S также присвоить значение 0.
6) ПОДГОТОВКА ЦИКЛА: n:=0; S:=0;
Условие продолжения цикла (обозначим B) найдем, принимая во внимание постусловие Q.
7) УСЛОВИЕ ПРОДОЛЖЕНИЯ ЦИКЛА B: Sa.
В соответствии со стратегией решения задачи (последовательное получение частичных сумм) и смыслом параметра n (номер частичной суммы) будем продвигаться к цели, увеличивая значение n.
8) МОДИФИКАТОР ЦИКЛА: inc(n).
Заметим, что в этот момент условие инварианта цикла I нарушилось (номер частичной суммы n мы увеличили, а значение частичной суммы S осталось прежним. Восстановим это соответствие, добавив очередное слагаемое.
9) ТЕЛО ЦИКЛА: S:=S+1/n.
Теперь инвариант цикла восстановлен и можно вернуться к заголовку цикла с целью проверить условие выхода из цикла.
Соберем наши элементы программы вместе. Получим программу:
10) ТЕКСТ ПРОГРАММЫ:
<< Подготовить a (например, ввести) >>
n:=0; S:=0;
while Sa do begin
inc(i);
S:=S+1/n
end;
Теперь докажем правильность этой программы (ее соответствие спецификации).
11) ЧАСТИЧНАЯ КОРРЕКТНОСТЬ ЦИКЛА: Это следует из того, что мы выйдем из цикла только тогда, когда нарушится условие B, т.е. S станет больше a. Из условия истинности инварианта (он будет справедлив при выходе из цикла), учитывая стратегию решения задачи (последовательное получение всех частичных сумм) можно заключить, что это произойдет впервые (т. е. предыдущая частичная сумма еще была меньше a). А это и есть требования постусловия Q – ч.т.д.
12) ПОЛНАЯ КОРРЕКТНОСТЬ ЦИКЛА: Из теории рядов известно, что наш ряд расходится, т.е. последовательность частичных сумм стремится к бесконечности. Поэтому обязательно наступит такой момент, когда при некотором n наша частичная сумма станет больше любого наперед заданного числа a, что означает нарушение условия продолжения цикла – ч.т.д.
Таким образом доказательство полной корректности цикла гарантирует, что цикл обязательно завершится, а доказательство частичной корректности показывает, что цикл завершится именно в состоянии Q. Итак, мы доказали, что наша программа решает поставленную задачу.
Задача 2. Найти количество значащих цифр в натуральном числе n.
P: Подготовить натуральное число n.
Q: k = <Количество значащих цифр в числе n>.
СТРАТЕГИЯ РЕШЕНИЯ ЗАДАЧИ: Будем обрезать младшие цифры числа. Текущее обрезаемое число обозначим C, а количество уже отрезанных цифр будем хранить в переменной k.
ИНВАРИАНТ ЦИКЛА I:
< Количество значащих цифр в числе n> = < Количество значащих цифр в числе C> + < количество уже отрезанных цифр, т.е. k>.
5) СТРУКТУРА ЦИКЛА:











 ВЫХОД
ВЫХОД


ПОДГОТОВКА ЦИКЛА:
C:=n; { Начнем с исходного числа}
k:=0; { Из условия истинности инварианта}
УСЛОВИЕ ЦИКЛА: C<>0.
М
 ОДИФИКАТОР
ЦИКЛА:
ОДИФИКАТОР
ЦИКЛА:
C:=C div 10; { В соответствии со стратегией задачи }
9) ТЕЛО ЦИКЛА:
inc(i); { Из условия сохранения инварианта цикла }
ТЕКСТ ПРОГРАММЫ:
<< Подготовить n (например, ввести) >>
C:=n; k:=0;
while C<>0 do begin
C:=C div 10;
inc(i);
end;
11) ЧАСТИЧНАЯ КОРРЕКТНОСТЬ ЦИКЛА: Из условия выхода из цикла (C=0) следует, что в переменной k учтены все значащие цифры числа – ч.т.д.
12) ПОЛНАЯ КОРРЕКТНОСТЬ ЦИКЛА: В качестве функции декремента цикла можно взять значение < Количество значащих цифр в числе C>. Эта величина неотрицательна и конечная. При каждом выполнении тела цикла она убывает на 1. Когда она становится равной нулю срабатывает условие выхода из цикла (C=0) и цикл завершается.
Из доказательства частичной корректности цикла следует, что он завершается именно в состоянии Q (В k находится количество значащих цифр числа).
Задача 3. Найти сумму цифр натурального числа n.
P: Подготовить натуральное число n.
Q: S = <Сумма цифр числа n>.
СТРАТЕГИЯ РЕШЕНИЯ ЗАДАЧИ: Будем обрезать число справа. Текущее обрезаемое число обозначим C, а сумму уже отрезанных цифр будем хранить в переменной S.
ИНВАРИАНТ ЦИКЛА I:
< Сумма цифр числа n> = < Сумма цифр числа C> + < Сумма уже отрезанных цифр, т.е. S>.
СТРУКТУРА ЦИКЛА:









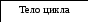

 ВЫХОД
ВЫХОД


6) ПОДГОТОВКА ЦИКЛА:
C:=n; { Начнем с исходного числа}
S:=0; { Из условия истинности инварианта}
УСЛОВИЕ ЦИКЛА: C<>0.
ТЕЛО ЦИКЛА:
S:=S+C mod 10; { В соответствии со стратегией задачи }
МОДИФИКАТОР ЦИКЛА:
C:=C div 10; { Из условия сохранения инварианта цикла }
ТЕКСТ ПРОГРАММЫ:
<< Подготовить n (например, ввести) >>
C:=n; S:=0;
while C<>0 do begin
S:=S+C mod 10;
C:=C div 10;
end;
11) ЧАСТИЧНАЯ КОРРЕКТНОСТЬ ЦИКЛА: Из условия выхода из цикла (C=0) следует, что в переменной S просуммированы все цифры числа – ч.т.д.
12) ПОЛНАЯ КОРРЕКТНОСТЬ ЦИКЛА: В качестве функции декремента цикла можно взять значение < Количество значащих цифр в числе C>. Эта величина неотрицательна и конечная. При каждом выполнении тела цикла она убывает на 1. Когда она становится равной нулю срабатывает условие выхода из цикла (C=0) и цикл завершается.
Из доказательства частичной корректности цикла следует, что он завершается именно в состоянии Q (В S находится сумма всех цифр числа).
Задача 4. Найти старшую цифру натурального числа n.
P: Подготовить натуральное число n.
Q: k = <Старшая цифра числа n>.
СТРАТЕГИЯ РЕШЕНИЯ ЗАДАЧИ: Будем обрезать число справа, пока не доберемся до старшей цифры числа.Текущее обрезаемое число обозначим C. Очередную отрезанную цифру будем хранить в переменной k.
ИНВАРИАНТ ЦИКЛА I:
< k есть старшая цифра числа n> ИЛИ C<>0
5) СТРУКТУРА ЦИКЛА:











 ВЫХОД
ВЫХОД


6) ПОДГОТОВКА ЦИКЛА:
C:=n; { Начнем с исходного числа}
7) УСЛОВИЕ ЦИКЛА: C<>0.
8) ТЕЛО ЦИКЛА:
k:=C mod 10; { В соответствии со стратегией задачи }
МОДИФИКАТОР ЦИКЛА:
C:=C div 10; { В соответствии со стратегией задачи }
ТЕКСТ ПРОГРАММЫ:
<< Подготовить n (например, ввести) >>
C:=n;
while C<>0 do begin
k:=C mod 10;
C:=C div 10;
end;
11) ЧАСТИЧНАЯ КОРРЕКТНОСТЬ ЦИКЛА: Из условия выхода из цикла (C=0) и условия сохранения инварианта следует, что в переменной k находится старшая цифра числа (один из операндов логической функции ИЛИ – ЛОЖЬ, тогда, чтобы инвариант остался истинным, необходимо, чтобы второй операнд стал истинным, т.е. k – старшая цифра числа) - ч.т.д.
12) ПОЛНАЯ КОРРЕКТНОСТЬ ЦИКЛА: В качестве функции декремента цикла можно взять значение < Количество значащих цифр в числе C>. Эта величина неотрицательна и конечная. При каждом выполнении тела цикла она убывает на 1. Когда она становится равной нулю срабатывает условие выхода из цикла (C=0) и цикл завершается.
Из доказательства частичной корректности цикла следует, что он завершается именно в состоянии Q (В k находится старшая цифра числа).
Понятие о типе данных.
Тип данных понимается как класс переменных , могут заменять друг друга в некоторых контекстах.
Понятие типовой безопасности: Цель контроля типов состоит в том, чтобы гарантировать, что фактическое использование объектов, как данных совместимо с установленным для них поведением, ассоциированных с типом их объекта.
Контроль типов должен обеспечит надежность программ.
Тип данных определяется по существу двумя свойствами:
поведением объекта, рассматриваемого типа;
структурным описанием, определяет представление объектов этого типа;
(не обязательно) множество объектов рассматриваемого типа;
Под типом объекта понимается:
само множество объектов;
существенные свойства, т.е. представление объектов этого множества;
набор операций обеспечивающий доступ к объектам и позволяющий использовать их свойства;
Тип – это не объект, а атрибут; или может быть объектом, существующим в период компиляции. Такой подход дает нам преимущества:
напоминает, что представление типов данных (в период компиляции) извлеченное из спецификации этого типа имеет решающее значение для эффективности (в период компиляции) контроля типов;
дает основу для классификации механизмов типов данных в ЯВУ.
Концепция типов данных в языке Паскаль.
Тип определяется тройкой:
множество допустимых значений;
набор операций;
внутреннее представление;
Если тип данных встроен в язык, то он обеспечивает:
описание переменных;
взятие значений и присваивание;
сравнение значений;
обозначение констант;
выбор компонент(для структурированных типов):
Организация данных в Паскале основана на теории структурной организации данных Хоара:
Тип определяется как класс значений, могут принимать переменные или выражения;
Каждое значение принадлежит только одному типу;
Тип значения, константы, переменной, выражения можно ввести либо из контекста, либо из вида самого операнда;
Каждой операции соответствует некоторый фиксированный тип ее операндов и результат;
Для каждого типа свойства значений и элементарных операций можно задать с помощью аксиомы;
Все это позволяет обнаруживать в программе бессмысленные конструкции (это контроль типов) и решать вопрос о представлении данных и преобразованиях в вычислительных машинах.
Классы операций воспринимаемых в Паскале:
неявные приведения;
приведение типа выражения;
приведение типа переменных;
Классификация средств определения данных в ЯВУ.
1)Средства структурирования данных;
(Алгол-60, Фортран);
а)существует набор встроенных типов данных:
integer;
real;
boolean;
characted;
б)средства структурирования:
array;
record;
union;
pointer;
2)Средства определения типов(Паскаль, Алгол-68); можно связать со структурой данных некоторое имя.
Type
Int Array = array[1..100] of integer;
Var
A,B:integer;
Два объекта считаются эквивалентными в языке Паскаль:
если описаны в одном операторе var;
если описаны одним идентификатором типа;
3)Абстрактные типы данных(АТД).
АТД – это, по существу, определение нового понятия в виде класса (одного или более) объектов с некоторыми свойствами и операциями. АТД предусматривает инкапсуляцию.
4)Средства ООП.
Симула 67 – язык программирования.
ООП – это методология программирования, основана на представлении программы в виде совокупности объектов, каждый из которых является реализацией некоторого класса, а классы образуют иерархию на принципах наследуемости.
Структурные единицы:
объекты;
каждый объект является реализацией некоторого класса;
классы организованы иерархически;
Поколения языков программирования.
Первое поколение ЯП: массивы, записи – не имели средств определения новых типов данных (Алгол-60, Фортран);
Второе поколение ЯП: появились средства определения новых типов данных, но не было средств связанных абстрактных типов (Алгол-68, Пасколь);
Третье поколение ЯП: связано с появлением АТД (Симула-67, Concurrent Pascal, CLU, Hephard, Modula);
Четвертое поколение ЯП: появились ООП языки (С++, Object Pascal).
Абстракция и декомпозиция.
Процесс разделения сложного на части, которые более простые, наз. декомпозицией.
Абстракция – создаются, в ходе программы, новые разработки, т.е. помогает осуществлять разумную декомбинацию.
Декомпозиция задачи предполагает разбиение задачи на подзадачи, причем:
каждая задача имеет один и тот же уровень рассмотрения;
каждая задача должна быть решена независимо от другой;
полученные решения могут быть объединены вместе и позволят решить исходную задачу.
Абстракция представляет собой эффективный метод декомпозиции, осуществляемый посредством изменения списка декомпозиции.
Абстракция – отвлечение от чего-то несущественного с целью лучше понять какую-то одну сторону изучаемого явления. Это метод создания новых понятий и обмена мыслями между людьми.
Абстрактные типы данных (АТД).
Абстрактные данные=<объекты, операции>
Новая языковая конструкция:
класс (Симула 67);
кластер (CLU);
форма (Alphard);
модуль (Modula);
пакет (Ada);
В памяти АТД в наиболее развитой форме входят следующие 4 части (Alphard):
внешность определяемого типа (имя, операции, функции и т.д.);
абстрактное описание операций и объектов, с которыми работает определенный тип на языке спецификации;
конкретное описание тех же объектов и операций средствами языка второго поколения;
описание связей между 2 и 3;
Инкапсуляция – это упрятывание.
Тип данных называется инкапсулированным, если предусмотрена защита; тип данных наз. абстрактным, если предусмотрено абстрактное описание; тип данных наз. пакетированным, если предусмотрено средство определения объектов и операций в одной языковой конструкции.
В языке CLU:
<Имя определяемого типа>=Cluster is<Список операций>
rep
<конкретное описание представления объектов определяемого типа>
<<конкретное описание операций определяемого типа>>
end;
Cluster – это средство абстракции т.к.:
новое понятие вводится через набор операций;
внешнюю по отношению к Cluster программу можно считать абстрактной программой, оперирующей с абстрактными объектами, с помощью операций кластеров;
абстрактная программа не зависит от представления;
защита представления класса;
Свойства CLU:
группировка операций в тип поведения;
фиксация уровней абстракции;
независимость от представления;
защита.
Нелинейные структуры данных (многоуровневые списки, деревья, сети). Изображение, представление, обход бинарных деревьев.
К нелинейным структурам относятся многоуровневые списки, деревья, сети. Среди нелинейных структур данных наиболее важными являются деревья, поэтому начнем рассмотрение нелинейных С.Д. с деревьев. Понятие деревьев естественно возникает при попытке классифицировать или структурировать какое – то подмножество объектов. Деревья очень важны при хранении информации. Теперь дадим определение дереву. Деревом называется конечное множество Т, состоящее из одного или более узлов, таких, что имеется один специально выделенный узел, называемый корнем этого дерева и остальные узлы (исключая корень) содержатся в m>=0 попарно непересекающихся множествах Т1, Т2, Т3,…..Тm, каждое из которых в свою очередь является деревом. Деревья Т1, Т2, Т3,…..Тmназываются поддеревьями данного корня. Это рекурсивное определение непустого дерева. Рекурсивность является естественной характеристикой деревьев как в информатике так ив природе. При работе с деревьями используется своя терминология. Степень узла – кол-во поддеревьев. Степень дерева – мах степень узлов. Концевой узел (лист) – узел нулевой степени. Регулярное дерево – все узлы разветвления имеют одну и ту же степень. Пустое дерево также будем считать деревом и обозначать егоNIL. Высотой дерева называется мах уровень узла –1, т.е. мах разность уровней. Если имеет значение относительный порядок поддеревьев, то дерево называется упорядоченным. Если порядок расположения поддеревьев данного узла не существенен, то дерево ориентированное, иначе – упорядоченное. Упорядоченные деревья, в которых для каждого узла м.б. 0,1,2 сына называется бинарным. Изображение деревьев. Существует много способов представления деревьев. Приведем самые распространенные.
1) 2)


3) 4) (A(B(D)(E))(C(F)(G(K))(I)))
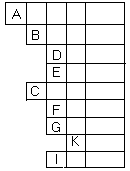
5)ABD.E..CF.GK..I… Такое изображение удобно при вводе из внешних носителей. Здесь точка ставится когда закончилось поддерево какого – то уровня. 6)Использование индексацииF-дерево;F[1]-первое поддерево;F[1][1]-первое поддерево первого поддерева. Представление дерева. 1)На базе массива или вектора. Это так называемое сплошное представление. Здесь удобно описывать плотные статические деревья (не имеющие внутри никаких пробелов). В случае, когда все же есть пустоты, то на место пустот в массиве ставится признак пустоты, но тогда теряется преимущество в экономии памяти. 2)Ссылочное представление. здесь возможны 2 варианта а)ссылка – относительный адрес б)ссылка – абсолютный адрес. Предположим, что мы имеем дерево
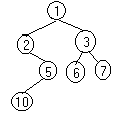
При описании обходов будем ссылаться на него, как на пример. Под обходом будем понимать обработку всех элементов дерева. Классифицируем обходы бинарных деревьев. 1)Левосторонний (инфиксный, обратный, симметричный).Сначала обходим левое поддерево, затем корень и правое поддерево. В нашем случае 2-10-5-1-6-3-7. 2)Правосторонний (инфиксный, обратный, симметричный). В нашем случае 7-3-6-1-5-10-2. 3)Прямой обход (обход в глубину сверху вниз или префиксный). В нашем случае 1-2-5-10-3-6-7 либо при обходе справа 1-3-7-6-2-5-10. 4)Концевой (обход снизу или постфиксный) 10-5-2-6-7-3-1 либо при обходе справа 7-6-3-10-5-2-1. 5)Горизонтальный обход. В нашем случае 1-2-3-5-6-7-10. Рассмотрим еще оду нелинейных структур данных – сеть. Введем понятие сети. Имеется сеть мелких объектов (узлов) и они соединены между собой дугами – это и есть С.Д. сеть. В математике сеть принято представлять как граф. Граф =<V,E>, гдеV– множество узлов,E– множество дуг =V*V. Граф может быть ориентированным и не ориентированным. Это ориентированный граф, если любому ребруl=(v,w) в графе есть реброl’=(w,v). Если эти пары считать за одну, то такой граф принято называть неориентированным. Представление графов (сетей). 1)Матрицы смежности. 2)Списки смежности. Под обходом, как и ранее, будем понимать обработку всех элементов графа. Существует два основных способа обхода графа. 1)Обход в глубину. 2)Обход в ширину. Оба способа ориентированы на то, чтобы сначала обходить близкие вершины, а потом уже дальше.
Линейные структуры данных, их представление и реализация.
Линейная структура данных – это С.Д. совокупность элементов которой является линейно упорядоченной. Линейными С.Д. являются : 1)Последовательность 2)Эластичная лента 3)Линейные списки а)стек б)дек в)очередь г)приоритетная очередь 4)Строки. Можно дать более полное определение линейной структуре данных. Это множество состоящее из n>=0 узловx1,x2,x3,,,xnструктурные(топологические) свойства которого по сути ограничиваются лишь линейным(одномерным) относительным положением узлов. Т.е. еслиn>0, тоx1– первый узел ; если 1<k<n, тоxk-1,xk,xk+1– порядок следования узлов, если к=n, тоxn – последний узел. Приведем операции, которые можно выполнять над линейными С.Д. 1)Создать 2)Получить доступ к узлу 3)Включить новый узел 4)Исключить узел 5)Объединить две структуры в одну 6)Разбить структуру на две 7)Сделать копию 8)Определить кол-во узлов в списке 9)Выполнить сортировку узлов 10)Найти узел, удовлетворяющий заданному условию 11)Уничтожить. Особую роль играют операции 2),3),4). Именно с помощью их можно последовательно конструировать, изменять и обрабатывать списки. Важными представляются случаи когда к=1 и к=n, т.е. операции, выполняемые с первым и последним элементами структуры. Дело в том, что в таких структурах получение доступа к первому и последнему элементу выполняется значительно проще, чем к другим элементам. Существуют различные способы представления линейных С.Д. и в зависимости от конкретного набора операций, то или иное представление будет эффективным. Видимо не существует единственного метода представления таких структур, при котором все эти операции реализовались бы эффективно. Поэтому имеет смысл классифицировать типы линейных структур по главным операциям, которые сними выполняются. Особую группу представляют списки, в которых включение, исключение и доступ почти всегда производится в первом или последнем узлах. Рассмотрим эти часто используемые С.Д. 1)Стек – линейный список, в котором все включения и исключения делаются в одном конце списка 2)Очередь– линейный список, в котором все включения на одном конце, а исключения на другом. 3)Дек – очередь с двумя концами, включ. и исключ. на обеих концах 4)Архив – дек с ограниченным входом 5)Реестр – дек с ограниченным выходом. В математике все эти структуры называются очередями с различными дисциплинами обслуживания. Наиболее часто используются стек и очередь. Стек организован по принципуLIFO(Last-In-First-Out), очередь по принципуFIFO(First-In-First-Out). Очереди в широком понимании слова, играют важную роль в теории массового обслуживания, которая определяет поведение реальной системы методом моделирования на ЭВМ.


Теперь рассмотрим другие линейные структуры данных. Последовательность. Элементы последовательности в каждый момент времени разделены на две части – прочитанную и непрочитанную. Можно провести аналогию между последовательностью и файлом.

После создания посл. прочитанная и непрочитанная часть являются пустыми. При добавлении элемента в посл. он добавляется в конец. При этом непрочитанная часть увеличивается, а прочитанная не изменяется. Запись в последовательность идет только в конец.По операции “встать в начало посл.” (Reset) прочитанная часть делается пустой, а непрочитанная часть совпадает со всей посл. Непрочитанная часть ведет себя как очередь. Строки. Строки состоят из символов, которые нужно кодировать. Возможны коды: 1)Фиксированной длинны ДКОИ – 6 бит ; КОИ – 7 бит;ASCII– 8, бит. сейчас реализуется 16 битовый код, он кодирует 65536 символов. 2)Коды переменной длинны. Рассмотрим специальные операции для строк: 1)Конкатенация 2)Дописывание одного символа в конец строки 3)Поиск вхождения подстроки в строку 4)Сопоставление с образцом 5)Удаление подстроки 6)Вставка подстроки в строку 7)Контекстная замена. Представление строк. строки могут быть представлены разными способами. 1)Строки фиксированной длинны с указанием длинны(TP) 2)последовательность символов до первого встретившегося нуля(Си) 3)Хранение в виде списка посимвольно 4)Хранение в виде списка многосимвольных звеньев фиксированной длинны 5) - || - переменной длинны.