


352 Глава 10. Глубокое обучение на временных последовательностях
10.2. ПРИМЕР ПРОГНОЗИРОВАНИЯ ТЕМПЕРАТУРЫ
Все.дальнейшие.примеры.в.этой.главе.будут.нацелены.на.решение.одной.задачи:. прогнозирование.температуры.на.ближайшие.24.часа.с.помощью.временной.последовательности.ежечасных.измерений.атмосферного.давления.и.влажности,. зарегистрированных.в.недавнем.прошлом.набором.датчиков.на.крыше.здания.. Как.вы.убедитесь,.это.довольно.сложная.задача!
Мы.покажем,.какие.принципиальные.отличия.имеют.временные.последовательности.от.наборов.данных,.с.которыми.вы.сталкивались.до.сих.пор..Вы.увидите,. что.плотно.связанные.и.сверточные.сети.плохо.подходят.для.обработки.таких. наборов.данных,.но.с.ними.блестяще.справляются.модели.машинного.обучения. другого.вида.—.рекуррентные.нейронные.сети.
Мы.будем.использовать.временные.последовательности.данных.о.погоде,.записанных.на.гидрометеорологической.станции.в.Институте.биогеохимии.Макса. Планка.в.Йене,.Германия1..В.этот.набор.данных.включены.замеры.14.разных. характеристик.(таких.как.температура,.атмосферное.давление,.влажность,.направление.ветра.и.т..д.),.выполнявшиеся.каждые.10.минут.в.течение.нескольких. лет..Cбор.данных.был.начат.в.2003.году,.но.в.этот.пример.включены.только. данные.за.2009–2016.годы.
Давайте.загрузим.и.распакуем.архив.с.данными:
!wget https://s3.amazonaws.com/keras-datasets/jena_climate_2009_2016.csv.zip !unzip jena_climate_2009_2016.csv.zip
А.потом.посмотрим,.что.у.нас.имеется.
Листинг 10.1. Обзор набора метеорологических данных Jena
import os
fname = os.path.join("jena_climate_2009_2016.csv")
with open(fname) as f: data = f.read()
lines = data.split("\n") header = lines[0].split(",") lines = lines[1:] print(header) print(len(lines))
1 . Адам.Эриксон.и.Олаф.Колле,.www.bgc-jena.mpg.de/wetter.

10.2. Пример прогнозирования температуры 353
Этот.код.выведет.420.551.строку.с.данными.(каждая.строка.соответствует.одному.замеру.и.содержит.дату.замера.и.14.значений.разных.параметров,.имеющих. отношение.к.погоде),.а.также.следующий.заголовок:
["Date Time", "p (mbar)", "T (degC)", "Tpot (K)",
"Tdew (degC)", "rh (%)", "VPmax (mbar)", "VPact (mbar)", "VPdef (mbar)", "sh (g/kg)",
"H2OC (mmol/mol)", "rho (g/m**3)", "wv (m/s)",
"max. wv (m/s)", "wd (deg)"]
Теперь.преобразуем.все.420.551.строку.с.данными.в.массивы.NumPy:.один.для. температуры.(в.градусах.Цельсия),.а.другой.для.остальных.данных.—.признаков,. которые.будут.использоваться.для.прогнозирования.температуры.в.будущем..
Обратите.внимание,.что.мы.отбросили.столбец.Date .Time .(Дата.и.время).
Листинг 10.2. Преобразование данных
import numpy as np
temperature = np.zeros((len(lines),))
raw_data = np.zeros((len(lines), len(header) - 1)) for i, line in enumerate(lines):
values = [float(x) for x in line.split(",")[1:]] temperature[i] = values[1] 
raw_data[i, :] = values[:]
Столбец 1 сохраняется в массиве temperature
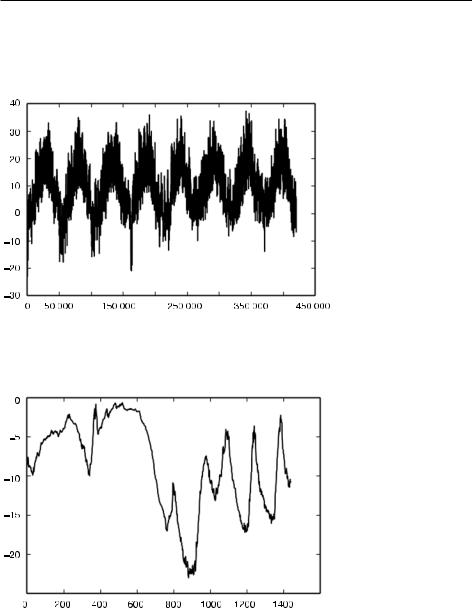
На.рис..10.1.показан.график.изменения.температуры.(в.градусах.Цельсия).с.течением.времени..На.этом.графике,.охватывающем.восьмилетний.период,.ясно. виден.годовой.цикл.изменения.температуры.
Листинг 10.3. Создание графика изменения температуры
from matplotlib import pyplot as plt plt.plot(range(len(temperature)), temperature)
На.рис..10.2.показан.более.короткий.график.изменения.температуры.—.за.первые. десять.дней..Поскольку.данные.записываются.каждые.десять.минут,.за.сутки. накапливается.24.×.6.=.144.замера.
354 Глава 10. Глубокое обучение на временных последовательностях
Листинг 10.4. Создание графика изменения температуры по данным за первые десять дней
plt.plot(range(1440), temperature[:1440])
Рис. 10.1. График изменения температуры (°C), построенный по полному набору данных
Рис. 10.2. График изменения температуры (°C) по данным за первые десять дней
На.этом.графике.можно.видеть.суточный.цикл.изменения.температуры,.который. особенно.четко.наблюдается.на.отрезке,.соответствующем.последним.четырем. дням..Также.отметьте,.что.этот.десятидневный.отрезок.соответствует.довольно. холодному.зимнему.месяцу.

10.2. Пример прогнозирования температуры 355
ВСЕГДА ИЩИТЕ ЦИКЛИЧНОСТЬ В ВАШИХ ДАННЫХ
Цикличность — важное и очень распространенное свойство временны´ х последовательностей. Независимо от того, какие данные вы рассматриваете — погоду, количество свободных мест на парковке в торговом центре, посещаемость веб-сайта, продажи в продуктовом магазине или количество шагов, подсчитанных шагомером, — вы неизменно будете наблюдать суточные и годовые циклы (данные, генерируемые человеком, также имеют недельные циклы). Поэтому при исследовании данных обязательно ищите подобные закономерности.
Если.бы.мы.предсказывали.среднюю.температуру.на.следующий.месяц.по.данным.за.несколько.предыдущих.месяцев,.это.не.составило.бы.большого.труда. благодаря.устойчивой.периодичности.в.масштабах.года..Однако.изменение. температуры.в.масштабе.нескольких.дней.выглядит.более.хаотичным..Можно.ли. с.высокой.надежностью.предсказать.временную.последовательность.в.масштабе. суток?.Давайте.посмотрим.
В.дальнейших.экспериментах.мы.будем.использовать.первые.50.%.данных.для. обучения,.следующие.25.%.—.для.проверки.и.последние.25.%.—.для.контроля..
При.работе.с.временными.последовательностями.важно,.чтобы.проверочные. и.контрольные.данные.были.более.свежими,.чем.обучающие..Мы.прогнозируем. будущее.на.основе.прошлого,.а.не.наоборот,.поэтому.проверочная.и.контрольная. выборки.должны.отражать.это..Некоторые.задачи.оказываются.значительно. проще,.если.перевернуть.ось.времени!
Листинг 10.5. Вычисление количества образцов в каждой выборке
>>>num_train_samples = int(0.5 * len(raw_data))
>>>num_val_samples = int(0.25 * len(raw_data))
>>>num_test_samples = len(raw_data) - num_train_samples - num_val_samples
>>>print("num_train_samples:", num_train_samples)
>>>print("num_val_samples:", num_val_samples)
>>>print("num_test_samples:", num_test_samples)
num_train_samples: 210225 num_val_samples: 105112 num_test_samples: 105114
10.2.1. Подготовка данных
Вот.точная.формулировка.вопроса,.на.который.нам.нужно.ответить.в.рамках. задачи: .можно .ли .предсказать .температуру .на .следующие .24 .часа .по .данным .замеров, .выполнявшихся .один .раз .в .час .и .охватывающих .предыдущие. пять .дней?

356 Глава 10. Глубокое обучение на временных последовательностях
Для.начала.преобразуем.данные.в.формат,.понятный.нейронной.сети..Это.легко:. они.уже.представлены.в.числовом.виде,.поэтому.нам.не.придется.их.как-то.век- торизовать..Однако.временные.последовательности.разных.параметров.в.данных. имеют.разный.масштаб.(например,.атмосферное.давление,.измеряемое.в.миллибарах,.изменяется.около.значения.1000,.а.концентрация.CH2O,.измеряемая. в.миллимолях.на.моль,.колеблется.около.тройки)..Мы.должны.нормализовать. временные.последовательности.независимо.друг.от.друга,.чтобы.все.они.состояли.из.небольших.по.величине.значений.примерно.одинакового.масштаба.. В.качестве.обучающих.данных.мы.будем.использовать.первые.210.225.замеров,. поэтому.вычислим.среднее.значение.и.стандартное.отклонение.только.для.этой. части.данных.
Листинг 10.6. Нормализация данных
mean = raw_data[:num_train_samples].mean(axis=0) raw_data -= mean
std = raw_data[:num_train_samples].std(axis=0) raw_data /= std
Затем.создадим.объект.Dataset,.возвращающий.пакеты.данных.за.последние. пять.дней.вместе.с.целевой.температурой.через.24.часа.в.будущем..Поскольку. образцы.в.наборе.данных.избыточны.(образцы.N.и.N.+.1.будут.иметь.много. общего),.весьма.расточительно.явно.выделять.каждый..Вместо.этого.мы.будем. генерировать.образцы.на.лету,.используя.только.исходные.массивы.raw_data . и.temperature.
Для.этого.мы.могли.бы.написать.генератор.Python,.но.в.Keras.уже.есть.готовая. утилита,.которая.как.раз.генерирует.нужные.нам.образцы.(timeseries_dataset_ from_array()),.поэтому.можно.сэкономить.силы.и.время..Кстати,.она.подходит. практически.для.любых.задач.прогнозирования.временных.последовательностей.
УТИЛИТА TIMESERIES_DATASET_FROM_ARRAY()
Чтобы понять, что делает timeseries_dataset_from_array(), рассмотрим простой пример. Идея этой утилиты заключается в получении массива данных, составляющих временну´ю последовательность (аргумент data), и возвращении окна, извлеченного из исходных временны´ х последовательностей (будем называть их просто «последовательности»).
Например, для data = [0 1 2 3 4 5 6] и sequence_length=3 утилита timeseries_ dataset_from_array() сгенерирует следующие выборки: [0 1 2], [1 2 3], [2 3 4], [3 4 5], [4 5 6].
Также в timeseries_dataset_from_array() можно передать аргумент targets (массив). Первый элемент targets должен соответствовать желае-

10.2. Пример прогнозирования температуры 357
мой цели для первой последовательности, которая будет сгенерирована из массива данных. Поэтому при прогнозировании временны´ х последовательностей цели должны быть таким же массивом, что и data, но со смещением на некоторую величину.
Например, для data = [0 1 2 3 4 5 6 ...] и sequence_length=3 можно создать набор данных для прогнозирования следующего шага в последовательности, передав targets = [3 4 5 6...]. Давайте попробуем:
import numpy |
as |
np |
|
Генерируется |
Сгенерированные |
|
|
||||||
from tensorflow |
import keras |
|
отсортированный массив |
последовательности будут |
||
int_sequence |
= np.arange(10) |
|
|
целых чисел от 0 до 9 |
выбираться из [0 1 2 3 4 5 6] |
|
|
|
|||||
dummy_dataset = keras.utils.timeseries_dataset_from_array(
data=int_sequence[:-3], |
|
|
|
|
|
|||
|
|
|
Целью для последовательности, |
|||||
targets=int_sequence[3:], |
|
|
|
|
||||
|
|
|
|
которая начинается с data[N], |
||||
sequence_length=3, |
|
|
|
|
|
|||
|
|
|
|
должна быть data[N + 3] |
||||
|
|
|
|
|||||
batch_size=2, |
|
|
|
Длина последовательности |
||||
|
|
|
||||||
) |
|
|
|
|
|
|||
|
|
|
|
|
должна быть равна 3 |
|||
|
|
|
|
|
|
|||
for inputs, targets in dummy_dataset: |
|
Последовательности будут |
||||||
for i in range(inputs.shape[0]): |
|
собираться в пакеты по две |
||||||
|
||||||||
print([int(x) for x in inputs[i]], int(targets[i]))
Данный блок кода выведет следующий результат:
[0, 1, 2] 3 [1, 2, 3] 4 [2, 3, 4] 5 [3, 4, 5] 6 [4, 5, 6] 7
С.помощью.timeseries_dataset_from_array() .мы.создадим.три.набора.данных:. для.обучения,.для.проверки.и.для.контроля.
Для.этого.используем.следующие.параметры:
.sampling_rate = 6 .—.наблюдения.будут.извлекаться.по.одному.за.каждый. час,.то.есть.по.одному.замеру.из.шести;
.sequence_length = 120 .—.наблюдения.будут.возвращаться.в.прошлое.на. пять.суток.(120.часов);
.delay = sampling_rate * (sequence_length + 24 - 1) .—.целью.для.последова- тельности.должна.быть.температура.через.24.часа.после.конца.последовательности.
При.создании.набора.обучающих.данных.передадим.start_index = 0 .и.end_ index = num_train_samples,.чтобы.использовать.только.первые.50.%.данных..

358 Глава 10. Глубокое обучение на временных последовательностях
Для.получения.проверочного.набора.данных.передадим.start_index = num_train_ samples .и.end_index = num_train_samples + num_val_samples,.чтобы.включить. в.него.следующие.25.%.данных..Наконец,.для.получения.контрольного.набора. данных.передадим.start_index = num_train_samples + num_val_samples,.чтобы. включить.оставшиеся.образцы.
Листинг 10.7. Создание наборов данных: обучающего, проверочного и контрольного
sampling_rate = 6 sequence_length = 120
delay = sampling_rate * (sequence_length + 24 - 1) batch_size = 256
train_dataset = keras.utils.timeseries_dataset_from_array( raw_data[:-delay],
targets=temperature[delay:], sampling_rate=sampling_rate, sequence_length=sequence_length, shuffle=True, batch_size=batch_size, start_index=0, end_index=num_train_samples)
val_dataset = keras.utils.timeseries_dataset_from_array( raw_data[:-delay],
targets=temperature[delay:], sampling_rate=sampling_rate, sequence_length=sequence_length, shuffle=True, batch_size=batch_size, start_index=num_train_samples,
end_index=num_train_samples + num_val_samples)
test_dataset = keras.utils.timeseries_dataset_from_array( raw_data[:-delay],
targets=temperature[delay:], sampling_rate=sampling_rate, sequence_length=sequence_length, shuffle=True, batch_size=batch_size,
start_index=num_train_samples + num_val_samples)
Каждый.набор.данных.возвращает.кортеж.(образцы, целевые значения),.где. образцы.—.это.пакет.из.256.образцов,.каждый.из.которых.включает.120.после- довательных.замеров.за.каждый.час,.а.целевые значения.—.соответствующий. массив.из.256.целевых.температур..Обратите.внимание,.что.образцы.перемешиваются.случайным.образом,.поэтому.два.соседних.образца.в.пакете.(например,. samples[0] .и.samples[1]).не.обязательно.близки.во.времени.