


276 Глава 8. Введение в глубокое обучение в технологиях зрения
Листинг 8.6. Копирование изображений в обучающий, проверочный и контрольный каталоги
import os, shutil, pathlib |
|
|
Путь к каталогу с распакованным |
||||||
|
|||||||||
|
|
|
|
исходным набором данных |
|||||
original_dir = pathlib.Path("train") |
|
|
|
|
|
|
|
Каталог для сохранения |
|
|
|
|
|
|
|
|
|||
new_base_dir = pathlib.Path("cats_vs_dogs_small") |
|
|
|
выделенного небольшого |
|||||
|
|
|
|||||||
|
|
|
|
|
|
|
|
набора |
|
def make_subset(subset_name, start_index, end_index): |
|||||||||
Создать обучающий |
|||||||||
for category in ("cat", "dog"): |
|
|
|
|
|||||
|
|
|
|
поднабор, включающий |
|||||
dir = new_base_dir / subset_name / category |
|||||||||
первые 1000 изображений |
|||||||||
os.makedirs(dir) |
|
|
|
|
|||||
|
|
|
|
из каждой категории |
|||||
fnames = [f"{category}.{i}.jpg" |
|
|
|
|
Создать |
||||
for i in range(start_index, end_index)] |
|||||||||
проверочный |
|||||||||
for fname in fnames: |
|
|
|
|
|||||
|
|
|
|
поднабор, |
|||||
shutil.copyfile(src=original_dir / fname, |
|||||||||
включающий |
|||||||||
dst=dir / fname) |
|
|
|
|
|||||
|
|
|
|
следующие |
|||||
|
|
|
|
|
|
|
|
500 изображений |
|
make_subset("train", start_index=0, end_index=1000) |
|
из каждой категории |
|||||||
|
|||||||||
make_subset("validation", start_index=1000, end_index=1500)  make_subset("test", start_index=1500, end_index=2500)
make_subset("test", start_index=1500, end_index=2500) 
Вспомогательная функция для копирования изображений кошек (и собак) с индексами от start_index до end_index в подкаталог new_base_dir/{subset_name}/cat (и /dog). В параметре subset_ name будет передаваться строка "train", "validation" или "test"
Создать контрольный поднабор, включающий следующие 1000 изображений из каждой категории
Теперь.у.нас.имеется.2000.обучающих,.1000.проверочных.и.2000.контрольных. изображений..Каждый.поднабор.содержит.одинаковое.количество.образцов. каждого.класса:.это.сбалансированная.задача.бинарной.классификации,.соответственно,.мерой.успеха.может.служить.точность.классификации.
8.2.3. Конструирование сети
Далее.мы.вновь.реализуем.модель.с.той.же.общей.структурой,.что.и.в.первом. примере:.сверточная.нейронная.сеть.будет.организована.как.стек.чередующихся. слоев.Conv2D .(с.функцией.активации.relu).и.MaxPooling2D.
Однако,.так.как.мы.имеем.дело.с.большими.изображениями.и.решаем.более. сложную.задачу,.мы.сделаем.сеть.больше,.добавив.еще.одну.пару.слоев.Conv2D . и.MaxPooling2D..Это.увеличит.емкость.модели.и.обеспечит.дополнительное.снижение.размеров.карт.признаков,.чтобы.они.не.оказались.слишком.большими,. когда.достигнут.слоя.Flatten..Учитывая,.что.мы.начнем.с.входов,.имеющих. размер.180.×.180.(выбор.был.сделан.совершенно.произвольно),.в.конце,.точно. перед.слоем.Flatten,.получится.карта.признаков.размером.7.×.7.
ПРИМЕЧАНИЕ
Глубина.карт.признаков.в.сети.будет.постепенно.увеличиваться.(с.32.до.256),.а.их. размеры.—.уменьшаться.(со.180.×.180.до.7.×.7)..Этот.шаблон.вы.будете.видеть.почти. во.всех.сверточных.нейронных.сетях.

8.2. Обучение сверточной нейронной сети с нуля 277
Так.как.перед.нами.стоит.задача.бинарной.классификации,.сеть.должна.заканчиваться.единственным.признаком.(слой.Dense.размером.1.и.функцией.активации. sigmoid)..Этот.признак.будет.представлять.вероятность.принадлежности.рассматриваемого.изображения.одному.из.двух.классов.
И.еще.одно.небольшое.отличие:.модель.будет.начинаться.со.слоя.Rescaling,. преобразующего.входные.данные.(значения.которых.изначально.находятся. в.диапазоне.[0,.255]).в.диапазон.[0,.1].
Листинг 8.7. Создание небольшой сверточной нейронной сети для классификации изображений кошек и собак
|
Модель принимает |
|
|
||
|
|
|
|||
from tensorflow import keras |
изображения в формате RGB |
|
Привести |
||
from tensorflow.keras import layers |
размерами 180 × 180 |
|
|||
|
|
|
|
|
входные данные |
inputs = keras.Input(shape=(180, 180, 3)) |
|
|
|
к диапазону [0, 1] |
|
|
|
|
делением на 255 |
||
x = layers.Rescaling(1./255)(inputs) |
|
|
|
|
|
|
|
|
|
|
|
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x) x = layers.Flatten()(x)
outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs=inputs, outputs=outputs)
Посмотрим,.как.изменяются.размеры.карт.признаков.с.каждым.последующим. слоем:
>>> model.summary() Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) [(None, 180, 180, 3)] 0
_________________________________________________________________
rescaling (Rescaling) (None, 180, 180, 3) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 178, 178, 32) 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 89, 89, 32) |
0 |
_________________________________________________________________
conv2d_7 (Conv2D) (None, 87, 87, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 43, 43, 64) |
0 |
_________________________________________________________________
conv2d_8 (Conv2D) (None, 41, 41, 128) 73856
_________________________________________________________________

278 Глава 8. Введение в глубокое обучение в технологиях зрения
max_pooling2d_4 (MaxPooling2 (None, 20, 20, 128) |
0 |
_________________________________________________________________
conv2d_9 (Conv2D) (None, 18, 18, 256) 295168
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 9, 9, 256) |
0 |
_________________________________________________________________
conv2d_10 (Conv2D) (None, 7, 7, 256) 590080
_________________________________________________________________
flatten_2 (Flatten) (None, 12544) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 12545
=================================================================
Total params: 991,041 Trainable params: 991,041 Non-trainable params: 0
_________________________________________________________________
На.этапе.компиляции,.как.обычно,.используем.оптимизатор.RMSprop..Так.как. модель.заканчивается.единственным.сигмоидным.выходом,.используем.функцию. потерь.binary_crossentropy.(для.напоминания:.в.табл..6.1.приводится.шпаргалка. по.использованию.разных.функций.потерь.в.разных.ситуациях).
Листинг 8.8. Настройка модели для обучения
model.compile(loss="binary_crossentropy", optimizer="rmsprop", metrics=["accuracy"])
8.2.4. Предварительная обработка данных
Как.вы.уже.знаете,.перед.передачей.в.модель.данные.должны.быть.преобразованы.в.тензоры.с.вещественными.числами..В.настоящее.время.данные.хранятся. в.виде.файлов.JPEG,.поэтому.их.нужно.подготовить,.выполнив.следующие.шаги.
1.. Прочитать.файлы.с.изображениями.
2.. Декодировать.содержимое.из.формата.JPEG.в.матрицы.пикселей.RGB. 3.. Преобразовать.их.в.тензоры.с.вещественными.числами.
4.. Привести.к.единому.размеру.(в.нашем.случае.180.×.180).
5.. Организовать.в.пакеты.(мы.будем.использовать.пакеты.по.32.изображения. в.каждом).
Этот.порядок.действий.может.показаться.немного.сложным,.но,.к.счастью,. в.Keras.имеются.утилиты,.способные.выполнить.его.автоматически..В.частности,.вспомогательная.функция.image_dataset_from_directory(),.которая. позволит.быстро.настроить.конвейер.обработки.для.автоматического.преобразования.файлов.с.изображениями.в.пакеты.готовых.тензоров..Именно.ее. мы.и.возьмем.

8.2. Обучение сверточной нейронной сети с нуля 279
Вызов.image_dataset_from_directory(directory) .сначала.составит.список.подкаталогов.в.каталоге.directory.и.предположит,.что.каждый.содержит.изображения,. принадлежащие.одному.из.классов..Затем.проиндексирует.файлы.изображений. в.каждом.подкаталоге.и,.наконец,.создаст.и.вернет.объект.tf.data.Dataset,.подготовленный.для.чтения.файлов,.перемешивания,.преобразования.в.тензоры,. приведения.к.общему.размеру.и.упаковки.в.пакеты.
Листинг 8.9. Чтение изображений с помощью функции image_dataset_from_directory from tensorflow.keras.utils import image_dataset_from_directory
train_dataset = image_dataset_from_directory( new_base_dir / "train",
image_size=(180, 180), batch_size=32)
validation_dataset = image_dataset_from_directory( new_base_dir / "validation",
image_size=(180, 180), batch_size=32)
test_dataset = image_dataset_from_directory( new_base_dir / "test",
image_size=(180, 180), batch_size=32)
ОБЪЕКТ DATASET В TENSORFLOW
В библиотеке TensorFlow имеется модуль tf.data, позволяющий создавать эффективные конвейеры ввода для моделей машинного обучения. Его основу составляет класс tf.data.Dataset.
Объект Dataset — это итератор: его можно использовать в цикле for. Обычно он возвращает пакеты входных данных и меток. Dataset можно также передавать непосредственно в вызов метода fit() модели Keras.
Класс Dataset предлагает множество важных функций, избавляя вас от сложностей их реализации вручную: в частности, асинхронную предварительную выборку данных (подготовку следующего пакета данных, пока предыдущий обрабатывается моделью, что обеспечивает непрерывность потока выполнения).
Класс Dataset также поддерживает API в функциональном стиле для изменения наборов данных. Вот короткий пример. Создадим экземпляр Dataset из массива NumPy случайных чисел с набором из 1000 образцов, каждый из которых является вектором, содержащим 16 чисел:
import numpy as np import tensorflow as tf
random_numbers = np.random.normal(size=(1000, 16))
dataset = tf.data.Dataset.from_tensor_slices(random_numbers)

280 Глава 8. Введение в глубокое обучение в технологиях зрения
По умолчанию наш набор данных dataset возвращает образцы поодиночке:
>>>for i, element in enumerate(dataset):
>>>print(element.shape)
>>>if i >= 2:
>>>break
(16,)
(16,)
(16,)
Но если добавить вызов метода .batch(), образцы будут возвращаться пакетами:
>>>batched_dataset = dataset.batch(32)
>>>for i, element in enumerate(batched_dataset):
>>>print(element.shape)
>>>if i >= 2:
>>>break
(32, 16) (32, 16) (32, 16)
Более того, в вашем распоряжении есть целый ряд удобных методов для работы с набором данных, таких как:
•.shuffle(buffer_size) — перемешивает элементы в буфере;
•.prefetch(buffer_size) — выполняет предварительную выборку буфера элементов в памяти GPU для большей эффективности;
•.map(callable) — применяет произвольное преобразование к каждому элементу в наборе данных (функцию callable, которая должна принимать один элемент из набора данных).
Особенно часто вам будет нужен метод .map(). Вот пример его использования для преобразования элементов с формой (16,) в нашем наборе данных в элементы с формой (4, 4):
>>>reshaped_dataset = dataset.map(lambda x: tf.reshape(x, (4, 4)))
>>>for i, element in enumerate(reshaped_dataset):
>>>print(element.shape)
>>>if i >= 2:
>>>break
(4, 4) (4, 4) (4, 4)
Далее в этой главе вы увидите еще несколько примеров использования метода map().
Рассмотрим.вывод.одного.из.таких.объектов.Dataset:.он.возвращает.пакеты.изображений.180.×.180.в.формате.RGB.(с.формой.(32, 180, 180, 3)).и.целочисленные.
8.2. Обучение сверточной нейронной сети с нуля 281
метки.(с.формой.(32,))..В.каждом.пакете.содержится.32.образца.(в.соответствии. с.параметром.batch_size).
Листинг 8.10. Вывод форм данных и меток, возвращаемых объектом Dataset
>>>for data_batch, labels_batch in train_dataset:
>>>print("data batch shape:", data_batch.shape)
>>>print("labels batch shape:", labels_batch.shape)
>>>break
data batch shape: (32, 180, 180, 3) labels batch shape: (32,)
Давайте.обучим.модель.на.нашем.наборе.данных.и.возьмем.аргумент.validation_ data .метода.fit() .для.наблюдения.за.изменением.метрик.на.этапе.проверки. с.использованием.отдельного.объекта.Dataset.
Кроме.того,.применим.обратный.вызов.ModelCheckpoint,.сохраняющий.модель. после.каждой.эпохи,.и.настроим.его,.указав.путь.к.файлу.для.сохранения.и.аргументы.save_best_only=True.и.monitor="val_loss":.с.ними.обратный.вызов.будет. сохранять.новый.файл.с.весами.модели.(перезаписывая.любой.предыдущий),. только.если.текущее.значение.метрики.val_loss.окажется.ниже,.чем.когда-либо. раньше.во.время.обучения..Благодаря.этому.сохраненный.файл.всегда.будет. содержать.состояние.модели,.соответствующее.наиболее.эффективной.эпохе. обучения.с.точки.зрения.величины.потерь.на.этапе.проверки,.и.нам.не.придется. повторно.обучать.новую.модель.с.меньшим.количеством.эпох,.если.будет.достигнут.эффект.переобучения:.мы.сможем.просто.загрузить.сохраненный.файл.
Листинг 8.11. Обучение модели с использованием объекта Dataset
callbacks = [ keras.callbacks.ModelCheckpoint(
filepath="convnet_from_scratch.keras", save_best_only=True, monitor="val_loss")
]
history = model.fit( train_dataset, epochs=30,
validation_data=validation_dataset, callbacks=callbacks)
Создадим.графики.изменения.точности.и.потерь.модели.на.обучающих.и.проверочных.данных.в.процессе.обучения.(рис..8.9).
Листинг 8.12. Формирование графиков изменения потерь и точности в процессе обучения
import matplotlib.pyplot as plt accuracy = history.history["accuracy"]
val_accuracy = history.history["val_accuracy"] loss = history.history["loss"]
val_loss = history.history["val_loss"]
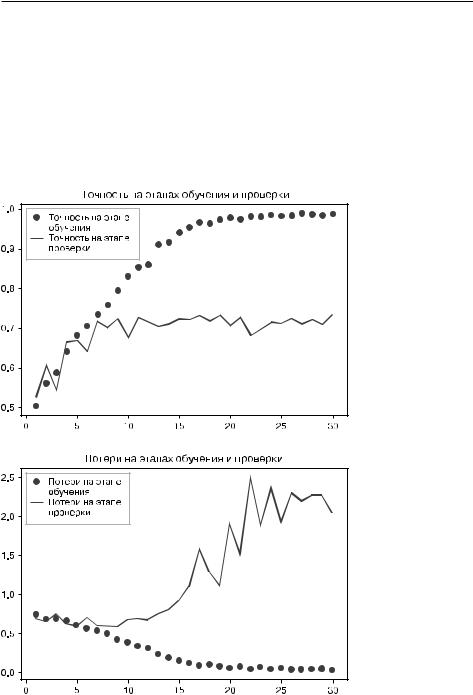
282 Глава 8. Введение в глубокое обучение в технологиях зрения
epochs = range(1, len(accuracy) + 1)
plt.plot(epochs, accuracy, "bo", label="Точность на этапе обучения") plt.plot(epochs, val_accuracy, "b", label="Точность на этапе проверки") plt.title("Точность на этапах обучения и проверки")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Потери на этапе обучения") plt.plot(epochs, val_loss, "b", label="Потери на этапе проверки") plt.title("Потери на этапах обучения и проверки")
plt.legend()
plt.show()
Рис. 8.9. Графики изменения метрик на этапе проверки |
при обучении простой сверточной сети |