


9.3. Современные архитектурные шаблоны сверточных сетей 317
О ВАЖНОСТИ ИССЛЕДОВАНИЯ ВОЗМОЖНОСТИ УПРОЩЕНИЯ МОДЕЛЕЙ ГЛУБОКОГО ОБУЧЕНИЯ
Архитектуры моделей глубокого обучения чаще являются результатом постепенного развития, чем проектирования, — они разрабатываются методом проб и ошибок. Так же как в биологических системах, если взять любую сложную экспериментальную модель глубокого обучения, есть вероятность, что удаление нескольких модулей (или замена некоторых обученных весов случайными значениями) не приведет к потере качества.
Наращивая сложность, исследователи глубокого обучения сталкиваются со следующим соблазном: сложная (даже более, чем необходимо) система может быть более интересной или более новой — что увеличит шансы прохождения авторских статей о ней через процесс рецензирования. Прочитав множество трудов по глубокому обучению, вы заметите, что они часто подгоняются под требования рецензентов как по стилю, так и по содержанию — и это отрицательно сказывается на ясности объяснения и надежности результатов. Например, математический аппарат в подобных текстах редко используется для четкой формализации идей или неочевидных результатов — чаще он применяется для придания налета серьезности, как дорогой костюм продавца.
Целью исследований должна быть не только публикация, но и получение надежных знаний. Самый простой путь для этого — изучение причинноследственной связи в вашей системе. Есть очень простой способ изучения причинно-следственной связи: исследование абляции (возможности упрощения модели). Оно предполагает систематические попытки упростить систему удалением ее частей, чтобы определить, где в действительности формируются основные результаты. Если вы обнаружите, что X + Y + Z дает хорошие результаты, попробуйте также X, Y, Z, X + Y, X + Z и Y + Z и посмотрите, что будет.
Став исследователем глубокого обучения, старайтесь избавляться от шума в процессе исследований: изучайте возможность упрощения своих моделей. Всегда спрашивайте: «Есть ли более простое объяснение? Действительно ли необходима эта дополнительная сложность? Зачем?»
9.3.2. Остаточные связи
Возможно,.вы.знакомы.с.детской.игрой.«испорченный.телефон».(в.Велико- британии.ее.называют.также.«китайским.шепотом»,.а.во.Франции.—.«арабским. телефоном»),.где.первоначальное.сообщение.нашептывается.на.ухо.первому. игроку,.который.затем.нашептывает.его.на.ухо.следующему.и.т..д..Последний. игрок.громко.сообщает.услышанное.им.сообщение,.зачастую.существенно.

318 Глава 9. Введение в глубокое обучение в технологиях зрения
отличающееся.от.исходной.версии..Это.—.забавная.метафора.накопления.ошибок. при.последовательной.передаче.информации.по.зашумленному.каналу.
Как.оказалось,.обратное.распространение.в.последовательной.модели.глубокого. обучения.очень.похоже.на.игру.в.«испорченный.телефон»..У.вас.есть.цепочка. функций,.например:
y = f4(f3(f2(f1(x))))
Цель.игры.—.настроить.параметры.каждой.функции.в.цепочке,.основываясь.на. ошибке,.полученной.на.выходе.f4 .(потеря.модели)..Чтобы.настроить.f1,.нужно. передать.информацию.об.ошибке.через.f2,.f3 .и.f4..Однако.каждая.следующая. функция.в.цепочке.вносит.свои.искажения..Если.цепочка.функций.слишком. глубокая,.искажения.начинают.подавлять.информацию.о.градиенте,.и.обратное. распространение.перестает.работать..Ваша.модель.вообще.не.будет.обучаться..
Это.проблема.затухания градиентов.
Решение.простое:.нужно.лишь.заставить.каждую.функцию.в.цепочке.перестать. вносить.искажения,.чтобы.сохранить.информацию,.полученную.от.предыдущей.
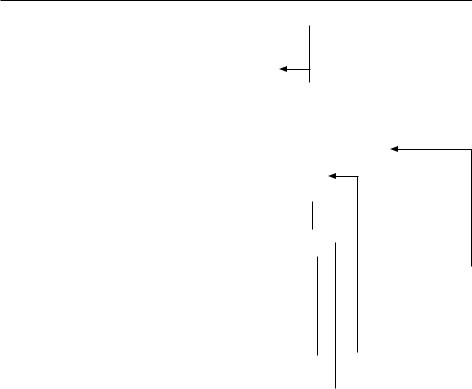
функции..Самый.простой.способ.реализовать. |
|
это.—.использовать.остаточные связи..Входные. |
|
данные.слоя.или.блока.слоев.добавляются.в.его. |
|
выходные.данные.(рис..9.9)..Остаточные.связи. |
|
действуют.как.короткие пути.для.распростра- |
|
нения .информации .в .обход .деструктивных. |
|
блоков.или.блоков,.вносящих.существенные. |
|
искажения.(таких.как.блоки.с.нежелательны- |
|
ми.активациями.или.слоями.прореживания),. |
|
позволяя.информации.градиента.ошибок.про- |
|
ходить.по.глубокой.сети.без.искажений..Этот. |
Рис. 9.9. Остаточная связь |
метод.был.представлен.в.2015.году.в.семействе. |
|
моделей.ResNet.(разработанном.Каймином.Хе. |
в обход блока, выполняющего |
с.коллегами.в.Microsoft)1. |
обработку |
На.практике.остаточная.связь.реализуется.следующим.образом.
Листинг 9.1.
x = ... 
 residual = x
residual = x  x = block(x)
x = block(x) 
x = add([x, residual])
Это вычислительный блок, который может вносить искажения
Добавить исходные данные в выход слоя: получившиеся выходные данные будут содержать полную информацию о входе
1. He Kaiming et al. .Deep .Residual .Learning .for .Image .Recognition .// .Conference.on. Computer.Vision.and.Pattern.Recognition,.2015,.https://arxiv.org/abs/1512.03385.

9.3. Современные архитектурные шаблоны сверточных сетей 319
Обратите .внимание: .добавление .входных .данных .блока .в .выходные .под разумевает,.что.выход.должен.иметь.ту.же.форму,.что.и.вход..Однако.этот.прием. не.подходит.для.случаев,.когда.блок.включает.сверточные.слои.с.увеличенным. количеством.фильтров.или.слой.выбора.максимального.по.соседям..В.таких. случаях.можно.использовать.слой.Conv2D .1.×.1.без.активации.для.линейного. проецирования.остатков.в.желаемую.форму.вывода.(листинг.9.2)..Обычно. сверточные.слои.в.целевом.блоке.создаются.с.аргументом.padding="same",.что- бы.избежать.уменьшения.пространственного.разрешения.из-за.дополнения,. и.берутся.увеличенные.шаги.свертки.в.остаточной.проекции,.чтобы.обеспечить. соответствие.любому.уменьшению.пространственного.разрешения,.вызванному. слоем.выбора.максимального.по.соседним.значениям.(листинг.9.3).
Листинг 9.2. Остаточный блок, в котором изменяется число фильтров
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation="relu")(inputs) residual = x
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) residual = layers.Conv2D(64, 1)(residual) 
x = layers.add([x, residual])
Теперь выход блока и тензор residual имеют одинаковую форму, и их можно сложить
В residual имеется только 32 фильтра, поэтому мы используем слой Conv2D 1 × 1 для преобразования в требуемую форму
Листинг 9.3. Случай, когда целевой блок включает слой выбора максимального по соседям
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation="relu")(inputs) residual = x 
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) x = layers.MaxPooling2D(2, padding="same")(x)
residual = layers.Conv2D(64, 1, strides=2)(residual) x = layers.add([x, residual]) 
В слое преобразования остатков используется аргумент strides=2, чтобы обеспечить соответствие с уменьшенным разрешением, созданным слоем MaxPooling2D
Теперь выход блока и тензор residual имеют одинаковую форму, и их можно сложить
Для.большей.конкретности.ниже.приводится.пример.простой.сверточной.сети,. организованной.в.серию.блоков,.каждый.из.которых.состоит.из.двух.сверточных.слоев.и.одного.необязательного.слоя.MaxPooling2D .с.остаточными.связями. в.обход.каждого.блока:
320 Глава 9. Введение в глубокое обучение в технологиях зрения
inputs = keras.Input(shape=(32, 32, 3)) x = layers.Rescaling(1./255)(inputs)
def residual_block(x, filters, pooling=False): residual = x
x = layers.Conv2D(filters, 3, activation="relu", padding="same")(x) x = layers.Conv2D(filters, 3, activation="relu", padding="same")(x) if pooling:
x = layers.MaxPooling2D(2, padding="same")(x)
residual = layers.Conv2D(filters, 1, strides=2)(residual) elif filters != residual.shape[-1]:
residual = layers.Conv2D(filters, 1)(residual) x = layers.add([x, residual])
return x
x = residual_block(x, filters=32, pooling=True)  x = residual_block(x, filters=64, pooling=True)
x = residual_block(x, filters=64, pooling=True) 
x = residual_block(x, filters=128, pooling=False) 
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs=inputs, outputs=outputs) model.summary()
Последний блок создается без слоя MaxPooling2D, потому что далее применяется слой глобального усреднения
Второй блок; обратите внимание, что число фильтров в каждом блоке увеличивается
Ниже.приводится.сводная.информация.о.созданной.модели:
Model: "model"
___________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
===================================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
___________________________________________________________________________________
rescaling (Rescaling) (None, 32, 32, 3) 0 input_1[0][0]
___________________________________________________________________________________
conv2d (Conv2D) (None, 32, 32, 32) 896 rescaling[0][0]
___________________________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248 conv2d[0][0]
___________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0 conv2d_1[0][0]
___________________________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 32) 128 rescaling[0][0]
___________________________________________________________________________________
add (Add) |
(None, 16, 16, 32) 0 |
max_pooling2d[0][0] |
|
|
conv2d_2[0][0] |
___________________________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 64) 18496 add[0][0]
___________________________________________________________________________________