


Основы машинного5обучения
В этой главе
33 Понимание противоречий между общностью и оптимизацией — фундаментальная проблема машинного обучения.
33 Формальные процедуры оценки моделей машинного обучения.
33 Методы эффективного обучения моделей.
33 Методы достижения лучшего обобщения.
После.трех.практических.примеров.в.главе.4.у.вас.должно.сложиться.начальное. понимание,.как.решаются.задачи.классификации.и.регрессии.с.использованием.нейронных.сетей..Кроме.того,.вы.собственными.глазами.увидели.главную. проблему.машинного.обучения:.переобучение..В.этой.главе.мы.формализуем. некоторые.из.новых.знаний.в.прочную.концептуальную.основу,.подчеркнув. важность.точной.оценки.модели.и.баланса.между.обучением.и.обобщением.
5.1. ОБОБЩЕНИЕ: ЦЕЛЬ МАШИННОГО ОБУЧЕНИЯ
В.трех.примерах,.представленных.в.главе.4,.—.в.прогнозировании.оценки.обзоров. фильмов,.классификации.тем.новостей.и.регрессии.цен.на.жилье.—.мы.делили. данные.на.обучающую,.проверочную.и.контрольную.выборки..Мы.быстро.выяснили.причину,.почему.нельзя.оценивать.качество.моделей.по.тем.же.данным,. на.которых.производилось.обучение:.спустя.всего.несколько.эпох.качество.
166 Глава 5. Основы машинного обучения
прогнозирования.по.обучающим.данным.начинало.расходиться.с.качеством.прогнозирования.по.данным,.которые.модель.прежде.не.видела..Возникал.эффект. переобучения,.и.этому.эффекту.подвержены.все.модели.машинного.обучения.
Основной.проблемой.машинного.обучения.является.противоречие.между.оптимизацией.и.общностью..Под.оптимизацией.понимается.процесс.настройки. модели.для.получения.максимального.качества.на.обучающих.данных.(обучение.
в.машинном обучении),.а.под.общностью.—.способность.обученной.модели.давать. качественный.прогноз.по.данным,.ранее.ей.незнакомым..Цель.игры.—.добиться. высокого.уровня.общности.—.но.вы.не.можете.ею.управлять..Можно.только.на- страивать.модель,.опираясь.на.обучающие.данные..И.если.переусердствовать.
в.этом,.возникнет.эффект.переобучения.и.общность.пострадает.
Но.из-за.чего.возникает.переобучение?.Как.добиться.хорошего.уровня.общности?
5.1.1. Недообучение и переобучение
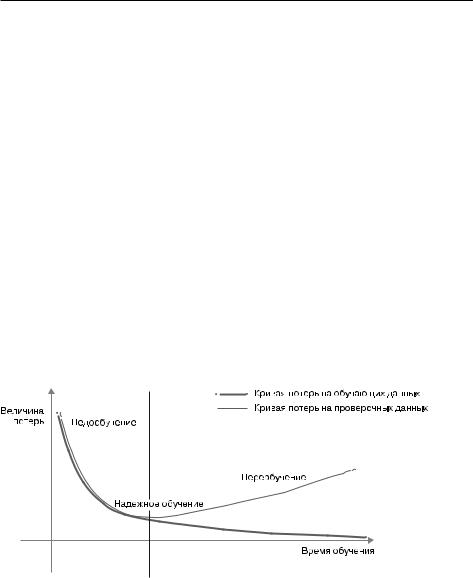
Во.всех.трех.примерах.предыдущей.главы.качество.модели.на.проверочных. данных.всегда.достигало.максимума.после.небольшого.количества.эпох.и.затем. начинало.снижаться..Это.закономерность.(рис..5.1)..Далее.вы.увидите,.что.она. проявляется.в.моделях.любых.типов.и.с.любым.набором.данных.
Рис. 5.1. Каноническое поведение модели при переобучении
В.начале.обучения.оптимизация.и.общность.коррелируют:.чем.ниже.потери. на.обучающих.данных,.тем.они.ниже.и.на.контрольных.данных..Пока.так.происходит,.принято.говорить,.что.модель.недообучена:.прогресс.еще.возможен;. сеть.еще.не.смоделировала.все.релевантные.шаблоны.в.обучающих.данных..
Однако.после.нескольких.итераций.на.обучающих.данных.общность.перестает.

5.1. Обобщение: цель машинного обучения 167
улучшаться,.метрики.оценки.на.проверочных.данных.останавливают.свой.рост. и.затем.начинают.ухудшаться:.наступает.эффект.переобучения.модели..Другими. словами,.модель.начинает.запоминать.шаблоны,.характерные.для.обучающих. данных,.но.нетипичные.для.новых.
Переобучение.особенно.вероятно,.когда.исходные.данные.зашумлены,.если.в.них. присутствует.элемент.неопределенности.или.они.содержат.редкие.признаки..
Давайте.рассмотрим.конкретные.примеры.
Зашумленные обучающие данные
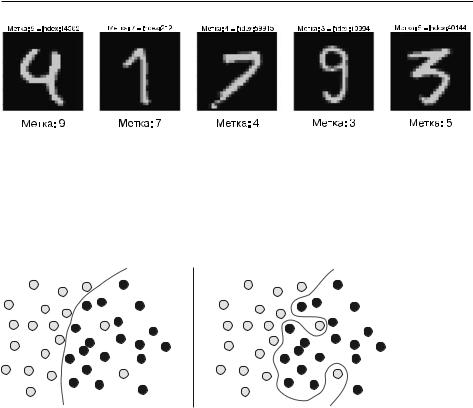
В.реальных.наборах.данных.довольно.часто.некоторые.входные.данные.оказываются.искаженными..Например,.изображение.цифры.в.наборе.MNIST.может. не.содержать.ничего,.кроме.черных.пикселей,.или.выглядеть.необычно.(рис..5.2).
Рис. 5.2. Некоторые необычные образцы в обучающей выборке в наборе MNIST
Что.это.за.цифры?.Я.тоже.не.знаю..Однако.все.они.присутствуют.в.обучающей.выборке.в.наборе.MNIST..Но.это.полбеды..Что.еще.хуже,.так.это.наличие. совершенно.правильных.входных.данных,.которые.имеют.ошибочные.метки. (рис..5.3).
168 Глава 5. Основы машинного обучения
Рис. 5.3. Образцы в обучающей выборке в наборе MNIST, имеющие неверные метки
Если.модель.постарается.учесть.такие.выбросы,.ее.способность.к.обобщению. ухудшится.(рис..5.4)..Например,.рукописная.цифра.4,.которая.очень.похожа.на.4. с.ошибочной.меткой.на.рис..5.3,.может.в.конечном.итоге.классифицироваться. как.9.
Рис. 5.4. Обобщение выбросов: надежное обучение против переобучения
Неоднозначные признаки
Не.всякий.шум.в.данных.возникает.из-за.неточностей.—.даже.идеально.отобран- ные.и.аккуратно.промаркированные.данные.могут.быть.зашумлены,.когда.имеет. место.неопределенность.и.неоднозначность..В.задачах.классификации.часто. бывает.так,.что.некоторые.области.пространства.исходных.признаков.связаны. сразу.с.несколькими.классами..Представьте,.что.вы.разрабатываете.модель,.ко- торая.по.изображению.банана.предсказывает.—.является.он.незрелым,.спелым. или.гнилым..Эти.категории.не.имеют.объективных.границ,.поэтому.одно.и.то.же. изображение.может.быть.классифицировано.разными.людьми.как.изображение. незрелого.или.спелого.банана..Аналогично.многие.задачи.связаны.со.случайностью..Например,.вы.могли.бы.взяться.за.предсказание.дождя.по.атмосферному. давлению,.но.за.одинаковыми.измерениями.с.некоторой.вероятностью.иногда. следует.дождливая,.а.иногда.солнечная.погода.
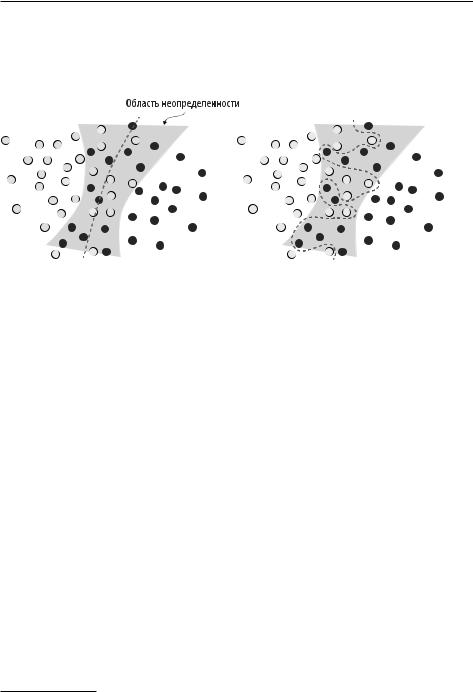
Модель .могла .бы .переобучиться .— .запомнить .такие .вероятностные .дан- ные .в .обучающей .выборке, .игнорируя .возможность .присутствия .областей.
5.1. Обобщение: цель машинного обучения 169
неопределенности.в.пространстве.признаков.(рис..5.5)..На.уровне.надежного. обучения.модель.способна.игнорировать.отдельные.образцы.и.видеть.картину. в.целом.
Рис. 5.5. Надежно обученная и переобученная модели по-разному видят область неопределенности в пространстве признаков
Редкие признаки и ложная корреляция
Если.вы.в.своей.жизни.видели.только.двух.рыжих.полосатых.кошек.и.обе.они. были.жутко.агрессивными,.вы.можете.сделать.вывод,.что.рыжие.полосатые. кошки,.как.правило,.агрессивны..Перед.вами.наглядный.пример.переобучения:. если.бы.вы.встретили.большее.количество.кошек,.и.не.только.рыжих,.то.узнали. бы,.что.характер.кошки.на.самом.деле.не.зависит.от.ее.окраски.
Точно.так.же.модели.машинного.обучения,.натренированные.на.наборах.данных,.включающих.редкие.значения.признаков,.подвержены.переобучению.. Если.в.задаче.классификации.отзывов.в.одном.из.текстов.обучающей.выборки. появится.слово.cherimoya.(черимойя.—.плод,.произрастающий.в.Андах),.а.от- зыв.будет.отрицательным,.то.слабо.регуляризованная.модель.может.придать. этому.слову.слишком.большой.вес.—.и.всегда.относить.к.отрицательным.любые. новые.отзывы,.упоминающие.черимойю,.тогда.как.объективно.в.этой.ягоде.нет. ничего.плохого1.
Важно.отметить,.что.значение.признака.не.обязательно.должно.встречаться. всего.несколько.раз,.чтобы.породить.ложные.корреляции..Представьте.слово,. которое.появляется.в.ста.обучающих.образцах,.из.которых.54.%.имеют.положи- тельную.оценку,.а.46.%.—.отрицательную..Эта.разница.вполне.может.быть.об- условлена.статистической.погрешностью,.но.модель,.весьма.вероятно,.научится.
1. Марк.Твен.даже.назвал.черимойю.«самым.вкусным.из.известных.человечеству. фруктом».

170 Глава 5. Основы машинного обучения
использовать.данный.признак.для.решения.задачи.классификации..Это.один. из.самых.распространенных.источников.переобучения.
Вот.яркий.пример..Возьмем.набор.MNIST..Создадим.новую.обучающую.вы- борку,.добавив.к.существующему.784-мерному.измерению.с.фактическими. данными.такое.же.784-мерное.измерение.с.белым.шумом,.чтобы.белый.шум. занимал.половину.данных..Для.сравнения.создадим.эквивалентную.выборку,. добавив.784-мерное.измерение.с.нулями..Добавление.бессмысленных.признаков. никак.не.влияет.на.информационное.содержание.данных:.просто.в.выборке.появились.измерения,.не.несущие.никакой.информации..Эти.дополнения.никак. не.повлияют.на.способность.человека.различать.рукописные.цифры.
Листинг 5.1. Добавление пустых признаков и признаков с белым шумом в выборку с данными из набора MNIST
from tensorflow.keras.datasets import mnist import numpy as np
(train_images, train_labels), _ = mnist.load_data() train_images = train_images.reshape((60000, 28 * 28)) train_images = train_images.astype("float32") / 255
train_images_with_noise_channels = np.concatenate(
[train_images, np.random.random((len(train_images), 784))], axis=1)
train_images_with_zeros_channels = np.concatenate( [train_images, np.zeros((len(train_images), 784))], axis=1)
Теперь.натренируем.модель.из.главы.2.на.обеих.обучающих.выборках.
Листинг 5.2. Обучение модели на выборке, включающей пустые признаки и признаки с белым шумом
from tensorflow import keras
from tensorflow.keras import layers
def get_model():
model = keras.Sequential([ layers.Dense(512, activation="relu"), layers.Dense(10, activation="softmax")
])
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
return model
model = get_model() history_noise = model.fit(
5.1. Обобщение: цель машинного обучения 171
train_images_with_noise_channels, train_labels, epochs=10,
batch_size=128, validation_split=0.2)
model = get_model() history_zeros = model.fit(
train_images_with_zeros_channels, train_labels, epochs=10,
batch_size=128, validation_split=0.2)
И.посмотрим,.как.изменяется.точность.обеих.моделей.на.проверочной.выборке. в.процессе.обучения.
Листинг 5.3. Вывод сравнительного графика изменения точности моделей на проверочной выборке
import matplotlib.pyplot as plt
val_acc_noise = history_noise.history["val_accuracy"] val_acc_zeros = history_zeros.history["val_accuracy"] epochs = range(1, 11)
plt.plot(epochs, val_acc_noise, "b-", label="Точность проверки с белым шумом")
plt.plot(epochs, val_acc_zeros, "b--",
label="Точность проверки с пустыми признаками") plt.title("Влияние признаков с белым шумом на точность проверки") plt.xlabel("Эпохи")
plt.ylabel("Точность") plt.legend()
Несмотря.на.то.что.обе.выборки.содержат.одну.и.ту.же.информацию,.точность. модели,.обученной.на.выборке.с.белым.шумом,.оказалась.примерно.на.один. процент.ниже.(рис..5.6).—.очевидно,.что.это.отставание.обусловлено.влиянием. ложных.корреляций..Чем.больше.каналов.с.шумом.будет.добавлено.в.выборку,. тем.хуже.будет.точность.
Зашумленные.признаки.неуклонно.ведут.к.переобучению..Поэтому,.когда.нет. четкой.уверенности.в.информативности.признаков,.перед.обучением.прибегают. к.отбору признаков..Например,.ограничение.данных.из.IMDB.десятью.тысячами. самых.распространенных.слов.было.упрощенной.формой.отбора.признаков..Ти- пичный.способ.отобрать.признаки.—.вычислить.некоторую.оценку.полезности. для.каждого.доступного.признака,.показывающую,.насколько.он.информативен. для.решаемой.задачи.(например,.тесноту.связи.между.признаком.и.метками),. и.оставить.только.признаки.с.оценкой.выше.некоторого.порога..Это.поможет. отфильтровать.неинформативные.признаки,.такие.как.канал.с.белым.шумом. в.предыдущем.примере.