

3841
.pdfВ нашем примере мы воспользуемся двумерными диа-
граммами рассеяния (Stats 2D Graphs -» Scatterplots).
В диалоговом окне при помощи кнопки Variables — Переменные выберите необходимые переменные, которые вы хотите отобразить графически и необходимый тип графика. Диаграмма рассеяния с прямой регрессии Y на х показана на рис. 2.13.
5.3. В Переключателе модулей (STATISTICA Module Switcher) выберите модуль Множественная регрессия (Multiple Regression). После запуска модуля на экране откроется стартовая панель модуля (рис. 2.14). Далее выберите переменные для анализа (воспользуйтесь кнопкой Variables). В качестве зависимой переменной (Dependent) выберите У, в качестве независимой (Independent) — X. После определения зависимых и независимых переменных на стартовой панели нажмите ОК.
Появится окно с результатами вычислений (рис. 2.15).
81

Рис.2.14.СтартоваяпанельмодуляMultiplyRegression
В диалоговом окне Результаты Множественной регрес-
сии — Multiple Regression Results просмотрите результаты оценивания. Результаты можно просмотреть в численном и графическом виде. Окно результатов анализа имеет следующую структуру: верх окна — информационный. Он состоит из двух частей: в первой части содержится основная информация о результатах оценивания, во второй высвечиваются значимый стандартизованный регрессионный коэффициент X- beta=,793; стандартизованный коэффициент регрессии вычисляется по формуле
~~
01 1* sx /sy ,
где sx и sy — оценки среднеквадратических отклонений для переменных х и у.
Рис. 2.15. Окно результатов множественной регрессии Внизу окна Результаты множественной регрессии
находятся функциональные кнопки, позволяющие всесторонне рассмотреть результаты анализа.
82

Рассмотрим вначале информационную часть окна. В ней содержатся краткие сведения о результатах анализа. А именно:
— Dep.Var. — имя зависимой переменной (Y);
—No. of Cases — число наблюдений (объем выборки п), по которым построена регрессия (n = 5);
—Multiple R — коэффициент множественной корреляции (описывает степень линейной зависимости между Y и факторами); в случае простой линейной регрессии равен модулю коэффициента корреляции;
—R — square — RI — квадрат коэффициента множественной корреляции (коэффициент детерминации). Если регрессионная модель значима, то коэффициент детерминации равен той доле дисперсии ошибок наблюдений, которая объясняется регрессионной моделью.
Коэффициент детерминации, вычисляется по формуле
R2 1 Qe ; Qy
— Adjusted R-square: adjusted RI— скорректированный коэффициент детерминации
R12 1 Qe / n k ,
Qy /(n 1)
где п — число наблюдений, а k — число оцениваемых параметров регрессионной модели; для простой линейной регрессии k
=2, так какопределяются оценки двух параметров 0 и 1 ;
—Std. Error of estimate — среднее квадратическое отклонение ошибок наблюдений
|
|
|
Qe |
; |
|
S |
S2 |
||||
|
|||||
|
|
|
(n k) |
||
~
—Intercept — оценка свободного члена регрессии 0
;
83

—Std. Error — стандартная ошибка оценки свободного
члена |
|
~ |
|
; |
D |
0 |
|
||
|
|
|
|
|
—t(n-k) and p-value — выборочное значение t- статистики и вычисленного уровня значимости р.t-статистика используется для проверки гипотезы H0 : 0 = 0:
|
|
~ |
|
|
|
t |
|
0 |
|
. |
|
|
|
|
|
||
|
|
~ |
|
||
|
|
D |
0 |
||
|
|
|
|
||
Уровень значимости p PT n k tв , где Т(п - к) — случайная величина, имеющая распределение Стьюдента с (я - к) степенями свободы, tв — выборочное значение t- статистики.
Если p , где — заданный уровень значимости, то гипотеза H0: 0 0 принимается.
В данном случае р = 0,823749, следовательно гипотеза H0: 0 0 принимается.
— F—выборочное значение F-статистики, FB.
F-статистика используется для проверки гипотезы H0:
0 0.
Если гипотеза H0: 0 0 верна, то статистика F имеет
распределение Фишера с (к- 1) и (n - к) степенями свободы. Гипотеза H0 принимается на уровне значимости , если
выборочное значение статистики F, FB, меньше F1 k 1,n k
- квантили распределения Фишера порядка 1 - . Если гипо-
теза H0: 0 0 принимается, то регрессионная модель незна-
чима.
—df— число степеней свободы F -статистики: (к- 1; n-к).
—р — вычисленный уровень значимости.
84

Вычисленный уровень значимости р: р = P[F(k - 1; п - k) > FB], где FB — выборочное значение F -статистики.
Если р < а, то гипотеза H0: 0 0 отклоняется; если р>
, то гипотеза H0: 0 0 принимается.
Вданном примере р = 0,109278, следовательно гипотеза H0: 0 0 принимается на уровне значимости = 0,05.
Регрессионная модель незначима.
Функциональные кнопки. При нажатии кнопки Regression Summary — Результаты регрессии на экране появится следующая таблица с результатами анализа (рис. 2.16):
Во втором столбце таблицы (BETA) выводится стандартизованный коэффициент регрессии 01 :
~
01 1* sx /sy ,
где sx и sy — оценки среднеквадратических отклонений для переменных х и у.
Рис. 2.16. Результаты регрессии
Стандартизированные коэффициенты регрессии — безразмерные величины.
В случае множественной регрессии стандартизованные коэффициенты регрессии используются для сравнения влияния на зависимую переменную факторов, имеющих различную размерность.
85

В четвертом столбце (В) приведены МНК-оценки коэффи-
~~
циентов регрессии: 0 и 1 .
Впятом столбце (St.Err. of В) — их стандартные отклонения
Вшестом столбце — t-статистики для проверки гипотезы
H0: 0 0:
|
|
~ |
|
|
|
ti |
|
i |
|
|
;i 0,1. |
|
|
|
|
||
|
|
||||
|
|
~ |
|||
|
|
D i |
|||
|
|
|
|
||
В седьмом столбце — соответствующие уровни значимо-
сти
pPT n k ti .
Вданном случае гипотеза H0: 1 0принимается на уров-
незначимости = 0,05.
Вычисленный уровень значимости р> . Это означает, что регрессионная модель незначима. Гипотеза H0: 0 0 также при-
нимаетсяпри =0,05.
Чтобы просмотреть и проанализировать остатки, войдите в меню Residual Analysis (анализ остатков), нажав соответствующую кнопку в нижней правой части панели результатов вычислений (рис. 2.15). Это меню представлено на рис. 2.17.
86

Рис. 2.17. Меню анализа остатков
Чтобы просмотреть остатки и их график, нажмите в левой нижней части этого меню кнопку Plots of residuals(A) (графики остатков (А)). Выбрав опцию Raw residuals (значения остатков), получим график остатков, наблюдаемые значения (observed value) зависимой переменной Y, предсказанные значения Y (predicted), остатки (residuals) и стандартизированные остатки (Standard Residual) вычисляемые по формуле
ei ,i 1,2,...,n, где S — оценка среднеквадратического откло-
S
нения ошибок наблюдений, S 0,7 (рис. 2.18).
Рис.2.18. График остатков (слева) и их значения (столбец Residual) справа
87
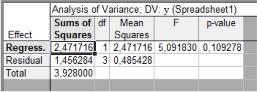
Остаточная сумма квадратов Qe (Residual) сумма квадратов, обусловленная регрессией QR (Regress) и сумма квадратов отклонений зависимой переменной Y ОТ среднего Qy (Total) вычисляются при нажатии кнопки Analysis of Variance (дисперсионный анализ) на панели результатов вычислений. Результаты дисперсионного анализа приведены на рис. 2.19.
Рис.2.19. Дисперсионный анализ
Вэтой же таблице приведены соответствующие значения числа степеней свободы (df), средние квадраты, F- статистика для проверки гипотезы о незначимости регрессионной модели и вычисленный уровень значимости р.
Вданном примере гипотеза о незначимости регрессионной модели по F-критерию также принимается, т. к. p 0,11
,что больше обычно задаваемого уровня значимости 0,05.
2.5.Обзор современных технологий анализа данных 2.5.1. Нейронечёткие системы
Нейронечеткие или гибридные системы, включающие в себя нечеткую логику, нейронные сети, генетические алгоритмы и экспертные системы, являются эффективным средством при решении большого круга задач реального мира [4].
Каждый интеллектуальный метод обладает своими индивидуальными особенностями (например, возможностью к обучению, способностью объяснения решений), которые делают его пригодным только для решения конкретных специфических задач.
88
Например, нейронные сети успешно применяются в распознавании моделей, но они неэффективны в объяснении способов достижения своих решений.
Системы нечеткой логики, которые связаны с неточной информацией, успешно применяются при объяснении своих решений, но не могут автоматически пополнять систему правил, которые необходимы для принятия этих решений.
Эти ограничения послужили толчком для создания интеллектуальных гибридных систем, где два или более методов объединяются для того, чтобы преодолеть ограничения каждого метода в отдельности.
Гибридные системы играют важную роль при решении задач в различных прикладных областях. Во многих сложных областях существуют проблемы, связанные с отдельными компонентами, каждый из которых может требовать своих методов обработки.
Пусть в сложной прикладной области имеется две отдельные подзадачи например задача обработки сигнала и задача вывода решения, тогда нейронная сеть и экспертная система будут использованы соответственно для решения этих отдельных задач.
Интеллектуальные гибридные системы успешно применяются во многих областях, таких как управление, техническое проектирование, торговля, оценка кредита, медицинская диагностика и когнитивное моделирование. Кроме того, диапазон приложения данных систем непрерывно растет.
В то время, как нечеткая логика обеспечивает механизм логического вывода из когнитивной неопределенности, вычислительные нейронные сети обладают такими заметными преимуществами, как обучение, адаптация, отказоустойчивость, параллелизм и обобщение.
Для того чтобы система могла обрабатывать когнитивные неопределенности так, как это делают люди, нужно применить концепцию нечеткой логики в нейронных сетях. Такие
89
гибридные системы называются нечеткими нейронными или нечетко-нейронными сетями.
Нейронные сети используются для настройки функций принадлежности в нечетких системах, которые применяются в качестве систем принятия решений.
Нечеткая логика может описывать научные знания напрямую, используя правила лингвистических меток, однако много времени обычно занимает процесс проектирования и настройки функций принадлежности, которые определяют эти метки.
Обучающие методы нейронных сетей автоматизируют этот процесс, существенно сокращая время разработки и затраты на получение данных функций.
Теоретически нейронные сети и системы нечеткой логики равноценны, поскольку они взаимно трансформируемы, тем не менее на практике каждая из них имеет свои преимущества и недостатки.
В нейронных сетях знания автоматически приобретаются за счет применения алгоритма вывода с обратным ходом, но процесс обучения выполняется относительно медленно, а анализ обученной сети сложен ("черный ящик").
Невозможно извлечь структурированные знания (правила) из обученной нейронной сети, а также собрать особую информацию о проблеме для того, чтобы упростить процедуру обучения.
Нечеткие системы находят большое применение, поскольку их поведение может быть описано с помощью правил нечеткой логики, таким образом, ими можно управлять, регулируя эти правила. Следует отметить, что приобретение знаний — процесс достаточно сложный, при этом область изменения каждого входного параметра необходимо разбивать на несколько интервалов; применение систем нечеткой логики ограничено областями, в которых допустимы знания эксперта и набор входных параметров достаточно мал.
90