

Экономико-математические методы и модели Часть 1
..pdfа1, а2, …, аm − коэффициенты регрессии, которые подлежат вычислению методом наименьших квадратов.
При анализе уравнения множественной регрессии вводится понятие ошибки прогнозирования у, которая вычисляется как разность между рассчитанным значением функции ŷi и ее изме-
ренным (опытным) значением yi, т.е. у = ŷi − yi.
Для построения линейной модели воспользуемся Масте-
ром функций, функцией Линейн (Известные_значения_y;
Известные_значения_x; Конст; Статистика).
Эта функция вычисляет статистику для ряда с применением метода наименьших квадратов, чтобы построить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, описывающий полученную прямую. Так как возвращается массив значений, функция должна быть задана виде формулы массива.
Уравнение для прямойлинии выглядит следующимобразом: y = а1x1 + a2x2 + ... + amxm + a0,
где зависимое значение y – функция независимых значений xk, k = 1, 2, …, m;
ak – коэффициенты, соответствующие каждой независимой переменной xk;
a0 – постоянная.
Функция Линейн возвращает массив {am; am–1; ...; a1; a0}. Линейн может также возвращать дополнительную регрессионную статистику.
Конст – логическое значение, указывающее, необходимо ли, чтобы константа a0 была равна 0. Если Конст имеет значение Истина или опущено, то a0 вычисляется обычным образом. Если аргумент Конст имеет значение Ложь, то a0 полагается равным 0 и значения a подбираются таким образом, чтобы было выполнено соотношение y = a*x.
Статистика – логическое значение, указывающее, необходимо ли вернуть дополнительную статистику по регрессии. Если аргумент Статистика имеет значение Истина, то функция
31

Линейн возвращает дополнительную регрессионную статисти-
ку, так что возвращаемый массив будет выглядеть следующим образом: {am; am–1; ...; a1; a0: Sam; Sam–1; ...; Sа2; Sа1: R2; Sy; Fрасч; df:
Sрегр; Sост}. Если аргумент статистика имеет значение Ложь или опущен, то функция Линейн возвращает только коэффициенты
ak и постоянную а0.
Дополнительная регрессионная статистика выдается в таком виде:
am |
am–1 |
… |
а2 |
а1 |
а0 |
Sam |
Sam–1 |
… |
Sа2 |
Sа1 |
Sа0 |
R2 |
Sy |
|
|
|
|
Fрасч |
df |
|
|
|
|
Sр2егр |
Sост2 |
|
|
|
|
Sа1, Sа2, …
Sam–1, Sam
Sa0
R2 Sy
Fрасч
df
Sрегр2
Sост2
стандартные значения ошибок для коэффициентов а1, а2, ..., аn
стандартное значение ошибки для постоянной a0 (Sa0 = #Н/Д, если Конст имеет значение Ложь)
коэффициент детерминации стандартная ошибка для оценки y критерий Фишера число степеней свободы
регрессионная (объясненная) вариация остаточная вариация
Для того чтобы построить линейную модель, действуем
втакой последовательности:
активизируем ячейку Р23;
запустим Мастер функций, в всплывающем диалоговом окне выберем необходимую категорию – Статистические, а затем выделим нужную функцию Линейн, затем нажмем – ОК;
в появившемся окне Линейн нужно заполнить текстовые поля для Известные значения y (диапазон ячеек Q2:Q21);
для Известные значения x (R2:T21); для Конст (Истина) и для Статистик (Истина);
затем нажмем кнопку ОК.
32
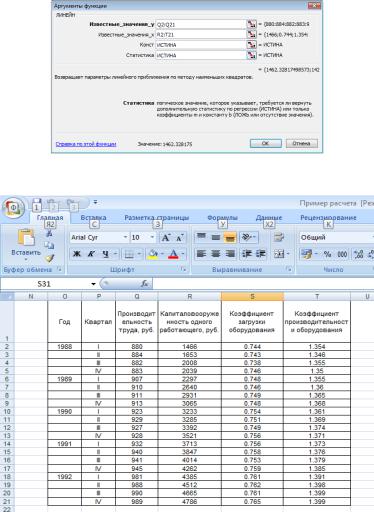
В итоге получаем значение:
Формулу в этом примере требуется ввести как формулу массива. Для этого выделим диапазон ячеек (P23:S27), начиная с ячейки, содержащей формулу. Нажмем клавишу F2, а затем клавиши CTRL+SHIFT+ENTER.
33
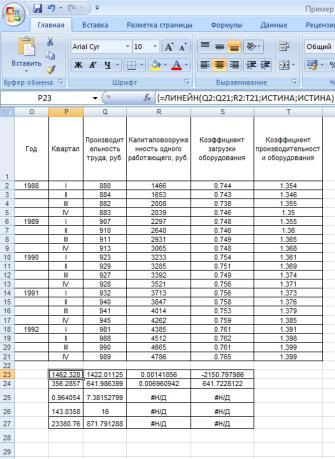
Получаем значения:
Линейная модель примет следующий вид:
y = –2150.798 + 0.00142x1 + 1422.01125x2 + 1462.328x3.
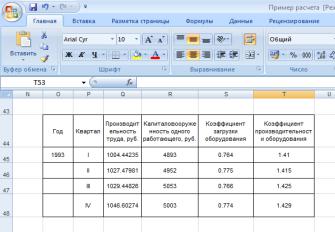
III. Прогнозируем производительность труда по модели на все кварталы следующего года.
Используем значение факторов х5; х11; х13 на 1993 год из табл. 2. Подставив эти значения в модель, получим прогнозные значения у.
34
Далее оценим точность прогноза в процентах:
|
|
|
i |
( yi yˆi ) |
100 %, |
|
|
|
|
|
|
|
|||
|
|
|
|
yi |
|
|
|
где yi |
– фактическое значение производительности труда; |
||||||
yˆi |
– расчетное значение производительности труда. |
||||||
|
|
|
(1025 1004.44) 100 % 2.006 % , |
|
|||
|
1 |
|
1025 |
|
|
|
|
|
|
|
|
|
|
||
|
2 |
|
(1077 1027.48) |
100 % 4.598 % , |
|
||
|
|
|
1077 |
|
|
|
|
|
3 |
|
(1079 1029.45) |
100 % 4.592 % , |
|
||
|
|
|
1079 |
|
|
|
|
|
|
(1090 1046.6) 100 % 3.982 % , |
|
||||
|
1 |
|
1090 |
|
|
|
|
|
|
|
|
|
|
||
|
1 2 3 |
4 2.006 4.598 4.592 3.982 |
3.79 % . |
||||
|
4 |
|
|
|
4 |
|
|
Поскольку среднее значение ошибки 3.79 % 7 % , то делаем вывод о том, что выбор факторов сделан правильно.
35
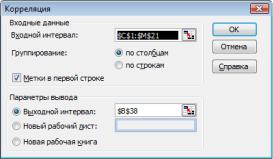
Далее решим предыдущий пример с использованием Ана-
лиза данных.
Для вычисления автокорреляции применим программу
Корреляции.
Для этого выполним следующие шаги:
1)в главном меню последовательно выберем пункты Сер-
вис/Анализ данных/Корреляция, затем щелкаем по кнопке ОК;
2)заполняем диалоговое окно для ввода данных и параметров вывода. Для того чтобы получить их, осуществим такие манипуляции:
зададим Входной интервал (в виде абсолютных ссылок $С$1:$M$21), а именно адресуем все ячейки, в которых есть значения функции у и аргументов x1, x2, …, xn;
выберем способ Группирования (для нашего случая – по столбцам);
поставим флажок для Метки, указывающий на то, что
впервой строке содержится название столбца;
выделим Выходной интервал, для этого достаточно указать левую верхнюю ячейку будущего диапазона ($B$38);
затем нажмем кнопку ОК.
36
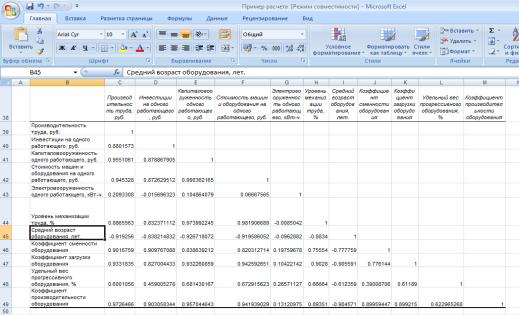
37
Получаем значения:
В первом столбце мы видим корреляцию между Y и Хi (коэффициент парной корреляции между производительностью труда и каждым фактором). В остальных столбцах рассчитаны коэффициенты автокорреляции между двумя факторами.
37
Для построения многофакторной модели и ее анализа применим методы анализа данных – программы Описательная статистика и Регрессия.
Для этого выполним следующие шаги:
1) в главном меню выберем последовательно пункты Сер-
вис/Анализ данных/Описательная статистика, затем щелкаем по кнопке ОК;
2) заполняем диалоговое окно для параметров вывода и ввода данных. Для того чтобы получить их, осуществим такие манипуляции:
зададим Входной интервал (в виде абсолютных ссылок $B$1:$D$21), а именно адресуем все ячейки, в которых находятся значения функции у и аргументов x1, x2 ;
выберем способ Группирования (в нашем случае по столбцам);
поставим флажок для Метки, указывающий на то, что
впервой строке содержится название столбца;
выделим Выходной интервал, для этого достаточно указать левую верхнюю ячейку будущего диапазона ($F$1);
поставим флажки, которые показывают необходимость получения Итоговой статистики, а также указывают, что требуемый Уровень надежности должен составлять 95 %; затем нажимаем кнопку ОК.
38
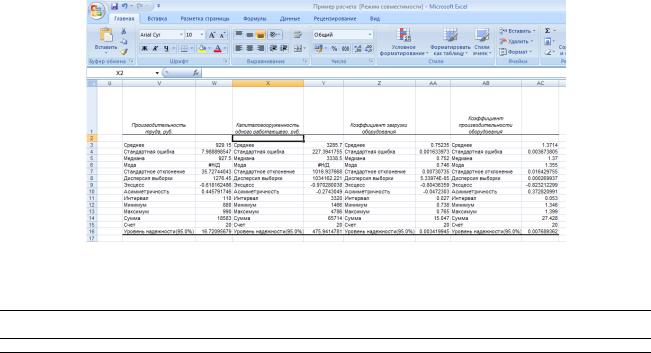
Получаем значения:
Из представленного комплекта статистических показателей выберем те, которые нам потребуются для последующего анализа, а именно среднее арифметическое и стандартное отклонение (среднеквадратичное отклонение) Sn.
|
|
Производительность |
Капиталовооруженность |
Коэффициент |
Коэффициент |
|
|
труда |
|
загрузки |
производительности |
|
Среднее |
929.15 |
3285.7 |
0.75235 |
1.3714 |
39 |
Стандартное отклонение |
35.727 |
1016.937 |
0.0073 |
0.01643 |
|
|
|
|
|
|
|
|
|
|
|
39
Вычисление показателей регрессии также происходит с использованием компьютерной программы. Для ее запуска выполним следующие команды:
в главном меню выберем пункты Сервис/Анализ данных / Регрессия, затем щелкнем по кнопке ОК;
заполним диалоговое окно ввода данных для параметра у
ихарактеристик х1 и х2; для того чтобы это сделать, необходимо в каждое окно (Интервал Y и Интервал Х) поместить наши данные, предварительно их выделив в соответствующих столбцах (нужно помнить, что для функции у данные расположены во втором столбце В2:В21, а для переменных х1 и х2 – в третьем и четвертом, т.е. в диапазоне ячеек C2:D21; отметим, что при этом выделяются только те ячейки, в которых находятся только числовые показатели);
выберем Уровень надежности (доверительную вероятность), равный 95 %;
выделим в текстовом поле Выходной интервал ту ячейку, от которой будет формироваться весь блок получаемых статистических показателей;
затем нажмем кнопку ОК.
40