

12
2.Сложность изменения. Например, при закрытии некоторого склада товары перераспределяются между другими складами. Эта операция потребует кардинального изменения структуры базы данных.
3.Жесткость структуры, не позволяющая учесть в базе данных отдельные реальные ситуации. Например, товары, хранящиеся на одном складе, предназначены нескольким магазинам.
4.Сложность эксплуатации. Работа с иерархическими базами данных требует значительной квалификации пользователей в области программирования. В частности, в СУБД IMS фирмы IBM для описания общей схемы базы данных и блока связи каждого пользователя с базой данных использовался язык программирования Assembler. Для выборки данных из БД – специализированный язык DL/1, для обработки полученной информации – языки PL/1 или Кобол.
Перечисленные причины привели к тому, что иерархическая модель данных
внастоящее время практически не используется.
Сетевая модель данных Стандарт сетевой модели данных впервые был определен в 1975 г. организа-
цией CODASYL (Conference of Data System Languages).
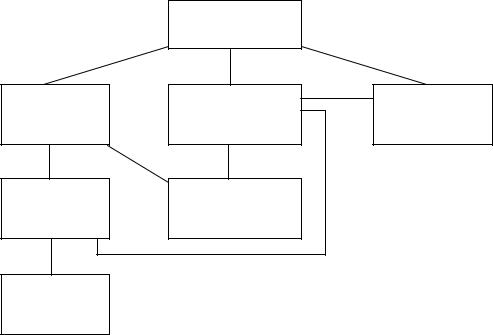
В сетевой модели данных не накладывается никаких ограничений на количество связей, входящих в одну вершину. Следовательно, связи можно уста-
навливать не только между узлами соседних по подчиненности уровней, но и различных уровней (рис. 3):
|
Филиал |
|
Магазин |
Подразделение |
Дирекция |
Склад |
Сотрудники |
|
Товар |
|
|
Рис. 3 |
Сетевая база данных |
|
13
Связи, изображенные на рис. 3 и отсутствующие на рис. 2, могут характеризовать вполне реальные взаимоотношения в работе торгового предприятия: представители дирекции могут курировать работу конкретных подразделений, подразделения предприятия (автохозяйство, ремонтная служба) обеспечивают работу складов, сотрудники подразделений (бухгалтеры, торговые агенты) взаимодействуют с магазинами. Таких связей можно определить очень много.
В результате формируется сеть, которая позволяет отображать связи между объектами предметной области практически любой степени сложности, в частности, кольцевые структуры. В сетевой модели, если на нее не накладывается никаких ограничений, в принципе любой объект может быть точкой входа в систему, каждый из объектов может быть связан с произвольным числом других объектов, и между записями связанных объектов могут быть любые отношения. Например, для сетевой базы данных, изображенной на рис. 3, формируются связи «многие ко многим» (многие подразделения предприятия обеспечивают работу многих складов). На практике в реальных СУБД на модель накладываются определенные ограничения для преобразования связей «многие ко многим» в связи «один ко многим».
Достоинствами сетевой модели данных по сравнению с иерархической моделью являются ее гибкость, возможность образования произвольных связей, экономичность. Недостатки – высокая сложность, практически исключающая возможность ее эксплуатации пользователями, не являющимися специалистами в области информационных технологий, ослабленный контроль целостности связей между объектами базы данных [ 15 ].
По указанным причинам СУБД, построенные на основе сетевой модели (IDMS, db_VistaIII и др.), не получили широкого распространения [ 15 ].
Реляционная модель данных Реляционная модель данных (РМД) положена в основу большинства совре-
менных СУБД. Достоинствами модели являются простота размещения данных и удобство их интерпретации.
Реляционная модель ориентирована на организацию данных в виде таблиц (отношений).
Для РМД существует довольно строгое теоретическое обоснование. Представление данных в виде отношений позволяет использовать для обработки данных формальный математический аппарат реляционной алгебры отношений и реляционного исчисления. Понятия таблицы и отношения с практической точки
14
зрения представляют собой одно и то же, поэтому в дальнейшем будут употребляться оба эти термина.
Каждая таблица реляционной базы данных имеет имя и строку заголовков. Рассмотрим таблицу базы данных торгового предприятия, в которой хранят-
ся сведения о поставщиках товаров (табл. 1.1):
Таблица 1.1
Поставщики
Код |
Название |
Город |
|
|
|
345 |
Волна |
Хабаровск |
|
|
|
412 |
Парус |
Владивосток |
|
|
|
123 |
Звезда |
Хабаровск |
|
|
|
215 |
Парус |
Иркутск |
|
|
|
Таблица имеет имя Поставщики, названия столбцов таблицы Код, Название, Город представляют собой строку заголовков.
Табличная форма представления данных позволяет удобно описывать простейший вид связей между ними: информация об объекте, которая хранится в таблице (поставщики товаров), делится на множество подобъектов, каждому из которых соответствует одна строка таблицы (конкретный поставщик). При этом все подобъекты имеют одинаковую структуру или свойства.
В терминологии реляционной модели данных каждый столбец таблицы называется полем (атрибутом), каждая строка таблицы – записью (корте-
жем).
Данные в одном поле могут иметь значения только из некоторой совокупности допустимых значений, называемой домéном. Например, для поля Код таблицы Поставщики домéном является совокупность целых трехзначных чисел, для поля Город – названий городов. Для каждого поля таблицы должен быть задан конкретный тип данных. Для поля Код он является числовым, для полей Название и Город – текстовым. Обратите внимание, что понятие типа данных шире, чем домена: числа могут быть не только целыми трехзначными, но и дробными, отрицательными и т. д.
К таблицам РМД предъявляются следующие требования:
1. Значения данных, расположенные на пересечении любых строки и столбца, должны быть неделимыми (атомарными, элементарными). Это требование означает, что в каждой ячейке таблицы может находиться только одно значение.
15
2.В таблице не должно быть полей с одинаковыми названиями, порядок расположения полей является произвольным. Наличие этого требования определяется тем, что поиск информации в таблице реализуется в полях, имена которых указаны в запросе.
3.Порядок следования записей может быть произвольным.
4.В таблице не должно быть одинаковых записей.
Важным следствием отсутствия в таблице одинаковых записей является наличие в ней первичного ключа. Значение первичного ключа должно быть
уникальным для каждой записи таблицы, следовательно, должно однозначно определять каждую запись таблицы.
Первичным ключом таблицы Поставщики является поле Код. Поля Название и Город не могут являться первичными ключами, так как в них имеются по-
вторяющиеся значения (см. табл. 1.1). Первичный ключ, определенный по одному полю таблицы, называется простым.
В ситуации, когда в таблице нет поля с уникальными значениями данных, первичный ключ может быть определен по нескольким полям. Например, в таблице Поставки товаров, в которой ведется учет партий товаров, поступивших в магазин, первичным ключом является совокупность полей Артикул и Дата по-
ставки (табл. 1.2):
|
|
|
|
Таблица 1.2 |
|
|
Поставки товаров |
|
|
|
|
|
|
|
Название товара |
Артикул |
Количество |
Дата поставки |
Шифр поставщика |
|
|
|
|
|
Костюм |
500 |
100 |
10.12.05 |
345 |
|
|
|
|
|
Сапоги |
200 |
75 |
10.12.05 |
123 |
|
|
|
|
|
Туфли |
100 |
120 |
11.12.05 |
123 |
|
|
|
|
|
Костюм |
500 |
100 |
11.12.05 |
345 |
|
|
|
|
|
Костюм |
300 |
50 |
12.12.05 |
345 |
|
|
|
|
|
Костюм |
400 |
50 |
12.12.05 |
215 |
|
|
|
|
|
Туфли |
100 |
100 |
12.12.05 |
215 |
|
|
|
|
|
Первичный ключ, определенный по нескольким полям, называется со-
ставным. В общем случае в таблице может быть несколько вероятных ключей, из которых один выбирается как первичный.
С помощью одной таблицы обычно не удается описать сложные структуры данных из предметной области. Поэтому реляционная модель данных предпола-
16
гает создание нескольких таблиц, которые при необходимости связываются между собой по ключевым полям. Такая стратегия очень удобна, так как позволяет хранить постоянно и редко используемые данные в разных таблицах.
Предположим, в таблице Дополнительные сведения хранится подробная информация об организациях, поставляющих товары (табл. 1.3):
|
|
|
|
Таблица 1.3 |
|
|
Дополнительные сведения |
|
|
||
|
|
|
|
|
|
Поставщик |
Директор |
Телефон |
Адрес |
№ договора |
|
|
|
|
|
|
|
345 |
Иванов П. Л. |
64-12-83 |
Мира, 4 |
75 |
|
|
|
|
|
|
|
412 |
Сеидов О. А. |
22-17-12 |
Победы, 18 |
19 |
|
|
|
|
|
|
|
123 |
Цой О. М. |
39-18-34 |
Блюхера, 1 |
79 |
|
|
|
|
|
|
|
215 |
Лодис С. С. |
46-19-23 |
Пушкина, 1 |
35 |
|
|
|
|
|
|
|
В таблицу Дополнительные сведения включены всего пять полей, но их может быть гораздо больше: ИНН организации, Банк организации, Главный бухгалтер и т. д. Очевидно, что такие сведения могут быть востребованы для учета поступающих товаров значительно реже, чем хранящиеся в таблице По-
ставщики.
Свяжем таблицы Поставщики и Дополнительные сведения с помощью полей Код и Поставщик. Сравнивая значения данных в этих полях и выбирая сочетания записей, для которых они совпадают, можно получить ответы, например, на такие запросы: «Кто является директором организации «Парус» из Владивостока?» (Сеидов О.А.); «Какой адрес у организации «Волна»?» (Мира, 4). Приведенный пример демонстрирует связь между таблицами «один к одному» – одной записи в таблице Поставщики соответствует одна запись в таблице До-
полнительные сведения.
Свяжем теперь таблицы Поставщики и Поставки товаров с помощью полей Код и Шифр поставщика. Возникает вопрос о правомерности выполненных действий. Так как значения данных в поле Шифр поставщика повторяются, это поле не может являться первичным ключом таблицы Поставки товаров.
На самом деле никакого противоречия не существует – поле Шифр постав-
щика является внешним ключом таблицы Поставки товаров. Внешний ключ –
это поле или группа полей таблицы, которые не являются первичным ключом в данной таблице, но являются первичным ключом в другой таблице.
17
С помощью связывания таблиц Поставщики и Поставки товаров по ключевым полям, можно получить ответы на запросы: «Какая организация поставила костюмы 10 декабря 2005 г.?» (Волна); «Из каких городов были привезены туфли?» (Хабаровск, Иркутск).
Связывая таблицы Поставки товаров и Дополнительные сведения, можно получить ответы на запросы: «Какой номер телефона у организации, поставившей костюмы с артикулом 500?» (64-12-83); «В соответствии с каким договором поставлялись костюмы с артикулом 400?» (№ 35).
Рассмотренные примеры очень просты. При работе с реальными базами данных можно выполнять более сложные запросы, связывая одновременно несколько таблиц. При этом не исключено, что для каждой связи будут использованы разные поля таблиц и типы ключей (простые или составные). Нет необходимости поддерживать постоянные связи между таблицами – они могут быть созданы в любой момент, когда возникнет соответствующая потребность.
Для связывания таблиц, данные в связующих полях обязательно должны быть получены из одного домена. Имена связующих полей могут отличаться друг от друга (Код, Шифр поставщика, Поставщик), расположение связующих полей в таблицах может быть произвольным (см. табл. 1.1 – 1.3).
Объектно-ориентированная модель данных Создание объектно-ориентированных СУБД считается одним из наиболее
перспективных направлений в области разработки новых типов баз данных. Объектно-ориентированные СУБД базируются на идеях, сформулированных
в объектно-ориентированных языках программирования (наследования, инкапсуляции и полиморфизма). Предметная область представляется в виде множества классов объектов. Структура и поведение объектов одного класса (например, товаров базы данных торгового предприятия) являются одинаковыми.
Объект обладает следующими характеристиками [ 12 ]:
1.Имеет уникальный идентификатор, однозначно определяющий объект.
2.Принадлежит к некоторому классу, обладающему определенными поведением и свойствами.
3.Может обмениваться сообщениями с другими объектами.
4.Имеет некоторую внутреннюю структуру. Объекты, внутренняя структура которых скрыта от пользователей (известно только, какие функции может выполнять данный объект), называются инкапсулированными.
18
Поведение объекта задается с помощью методов его класса – операций, которые можно применять к объекту. Способность применять один и тот же метод для разных классов называется полиморфизмом [ 2 ].
В объектно-ориентированной модели возможно создание нового класса объектов на основе уже существующего класса. Этот процесс называется наследованием. Новый класс, называемый подклассом существующего класса (суперкласса), наследует все свойства и методы суперкласса [ 4 ]. Кроме того, для него могут быть определены дополнительные свойства и методы.
Объектно-ориентированная СУБД позволяет хранить объекты и обеспечивает их совместное использование различными приложениями. Для этого она должна обладать следующими компонентами [ 12 ]:
1.Языком баз данных, который позволяет декларировать классы объектов, а затем создавать, сохранять, извлекать и удалять объекты.
2.Хранилищем объектов, к которому могут получить доступ разные приложения. Для ссылок на объекты используются их идентификаторы.
Для практической реализации объектно-ориентированных баз данных применяются два подхода [ 12 ]:
1.Используется язык объектно-ориентированного программирования (например, С++), дополненный средствами, позволяющими при необходимости сохранять объекты после завершения программы, с помощью которой они были созданы.
2.Основой является реляционная система, к которой добавляются объектноориентированные компоненты.
Недостатки объектно-ориентированных баз данных [ 12 ]:
1)отсутствуют необходимое унифицированное теоретическое обоснование
истандартизованная терминология;
2)не существует формально сформулированной методологии проектирования баз данных;
3)отсутствуют средства создания нерегламентированных запросов;
4)нет общих правил поддержания согласованности данных.
Взаключение можно отметить, что объектно-ориентированные базы данных
внастоящее время очень сложны в проектировании и эксплуатации, что ограничивает их практическое применение. Поэтому, несмотря на продолжающиеся интенсивные исследования, объектно-ориентированная модель данных пока поддерживается лишь немногими СУБД (POET, Jasmine, Versant, Iris) [ 15 ].