

38
[ 2 ]. Иногда применяется межфайловая кластеризация, когда на одной странице во внешней памяти размещаются записи из нескольких логических объектов (файлов) базы данных [ 2 ]. Например, на страницах, где содержатся сведения о поставках товаров в магазин с конкретными названиями и артикулами, может храниться информация о таких характеристиках этих товаров, как производитель, поставщик, цена, цвет изделия и т. д. из другого логического объекта. Такой принцип хранения данных может существенно ускорить выполнение запросов, включающих критерии отбора для характеристик, хранимых совместно, но он замедляет поиск информации для всех других запросов. Поэтому кластеризация является оправданной, если к базе данных наиболее часто выполняются запросы одного типа. При этом следует иметь в виду, что одновременно можно реализовать только один вариант кластеризации базы данных, так как речь идет о физическом хранении информации.
4.Распределенная обработка данных
4.1.Режимы работы с базой данных
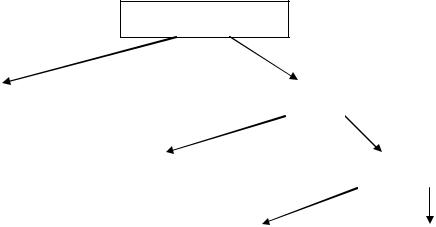
Взависимости от характера решаемых задач, обрабатываемой информации, используемой СУБД, работа с базами данных может быть организована различными способами (рис. 7):
Режим работы с БД
|
|
Многопользовательский |
Однопользовательский |
|
|
|
|
|
|
|
|
|
|
|
Последовательный |
|
Параллельный |
|
|
|
С централизованной БД |
|
С распределенной БД |
|
|
|
Рис. 7. Режимы работы с базами данных [ 4 ]
39
Если с базой данных, размещенной на автономном или входящем в состав локальной вычислительной сети компьютере, в течение одного или нескольких сеансов работает только один человек, такой режим называется однопользова-
тельским (монопольным).
В рамках последовательного многопользовательского режима к базе дан-
ных имеют доступ несколько человек, которые сменяют друг друга в процессе работы.
Параллельные режимы работы с базой данных предполагают, что с одной и той же базой данных одновременно работают несколько пользователей.
Несмотря на очевидную простоту рассмотренных понятий, студенты часто неправильно их интерпретируют, полагая, что сам факт одновременного выполнения заданий с помощью СУБД MS Access во время лабораторных занятий на компьютерах, включенных в локальную вычислительную сеть, обеспечивает параллельный режим работы. При этом забывается, что каждый пользователь работает со своей локальной базой данных, сохраняемой под уникальным именем.
Для обеспечения надежной и качественной работы с базой данных в монопольном и последовательном многопользовательском режимах обычно не требуются сложные специальные методы и технологии. Необходимый результат может быть достигнут с помощью простых организационных мер: регламентации действий и ограничения полномочий отдельных пользователей, внедрения детально разработанных инструкций о характере и последовательности выполняемых действий и т. д.
Монопольный и последовательный многопользовательский режимы в основном применяются для работы с небольшими, локальными базами данных (учет поступления товаров в отдельный магазин, решение несложной научноисследовательской задачи и т. д.). Если база данных предназначена для обеспечения деятельности даже небольших организаций, фирм, учреждений, с высокой степенью вероятности можно ожидать, что она будет эксплуатироваться в параллельном режиме.
Для понимания особенностей параллельного режима работы с базой данных предварительно рассмотрим фундаментальные понятия клиент и сервер.
4.2. Архитектура «клиент-сервер»
Термины «клиент» и «сервер» изначально применялись для архитектуры программного обеспечения, которое можно было разделить на два вычислитель-

40
ных процесса. Клиентский процесс запрашивает некоторые услуги у сервера, серверный процесс предоставляет эти услуги клиенту. Один сервер может обслуживать несколько клиентов.
В дальнейшем, в связи с развитием вычислительных сетей, возникла возможность распределения указанных задач между отдельными компьютерами. Поэтому в настоящее время под клиентом и сервером обычно понимают разные компьютеры, выполняющие эти задачи. По мнению К. Дж. Дейта, такое понимание терминов «клиент» и «сервер» является небрежным, но очень распространенным [ 2 ].
С позиций теории баз данных сервер – это собственно СУБД. Сервер обеспечивает хранение и обработку данных, их защиту и целостность и т.д.
Клиенты представляют собой различные приложения, выполняемые «над» СУБД. Они могут быть написаны непосредственно пользователями в процессе работы с базой данных на одном из языков программирования (С++, Pascal и т.д.) или являться встроенными приложениями, поставляемыми производителями СУБД или другими организациями (процессоры языков запросов, генераторы отчетов и приложений, графические бизнес-системы и т. д.) [ 2 ].
Исходя из рассмотренных положений, архитектуру «клиент-сервер» можно представить в следующем общем виде [ 2 ]:
Пользователи
Приложения Клиенты
|
|
Сервер |
СУБД |
||
|
|
|
|
|
|
База данных
Рис. 8. Архитектура «клиент-сервер» [ 2 ]
41
Архитектура «клиент-сервер» имеет ряд достоинств:
1.БД может использоваться одновременно несколькими клиентами.
2.Работа с данными клиентом и сервером выполняется параллельно. В результате процесс обработки данных существенно ускоряется.
3.Компьютер сервера может иметь большие вычислительные возможности, что обеспечивает высокую производительность системы.
4.Компьютер клиента можно адаптировать к требованиям конкретного конечного пользователя.
Основываясь на архитектуре «клиент-сервер», рассмотрим особенности режимов работы с централизованной и распределенной базами данных.
Централизованная база данных Централизованное хранение баз данных применяется уже несколько десяти-
летий. База данных хранится на внешних устройствах центральной ЭВМ, работающей под управлением многозадачной операционной системы. Пользователи обращаются к базе данных с удаленных терминалов, часто не имеющих собственных вычислительных ресурсов – процессора и памяти (рис. 9):
Пользователи
Клиенты
Телекоммуникационная вычислительная сеть
Сервер
База данных
Рис. 9. Централизованная база данных [ 2 ]
42
Достоинствами этого режима являются простота эксплуатации системы и ее относительная дешевизна. Недостатки – большая зависимость от качества работы центрального узла и повышенные требования к его производительности.
Система параллельного доступа к базе данных, расположенной на одном компьютере, нескольких пользователей называется системой распределенной обработки данных.
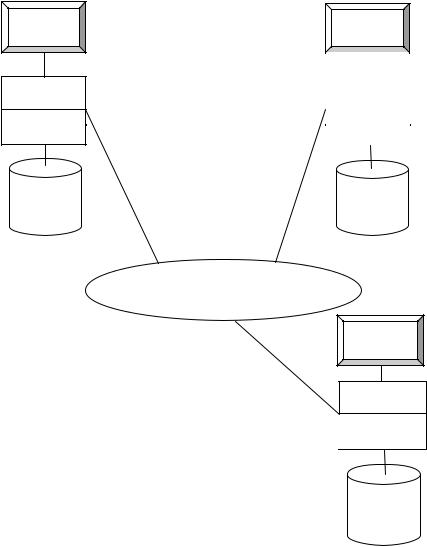
Распределенная база данных В рамках этого режима отдельные части базы данных распределяются между
различными компьютерами. При этом доступ к данным на любом компьютере поддерживается всеми клиентами через телекоммуникационную вычислительную сеть (рис. 10):
Пользователи |
Пользователи |
|
Клиенты |
|
|
Клиенты |
|
|
|
||
|
Сервер |
|
|
Сервер |
|
|
|
|
|
База данных (часть 1) |
База данных (часть 2) |
Телекоммуникационная вычислительная сеть
Пользователь
Клиенты
Сервер
База данных (часть 3)
Рис. 10. Распределенная база данных [ 2 ]
43
В каждом узле системы функционируют собственные СУБД и программное обеспечение. Следовательно, распределенную СУБД можно интерпретировать как способ организации совместной работы отдельных локальных СУБД, расположенных в различных узлах. При этом СУБД каждого узла должна иметь средства, обеспечивающие пользователям и приложениям возможность работы со всей базой данных.
Классифицируют гомогенные и гетерогенные распределенные базы данных [ 12 ]. В гомогенных распределенных базах данных в узлах системы используются СУБД одного типа, в гетерогенных – различных типов.
Рационально сохранять в каждом узле системы часть базы данных, логически связанную с этим узлом. Например, база данных, созданная для крупного производственного объединения, может состоять из фрагментов, каждый из которых содержит информацию о работе отдельного подразделения, цеха и т. д.
При такой организации работ увеличивается производительность обработки информации, так как сведения, необходимые для обеспечения деятельности подразделения или филиала предприятия, извлекаемые из базы данных наиболее часто, хранятся в связанном с ним узле системы. Это позволяет экономить ресурсы, поскольку обращение за данными к удаленным узлам происходит значительно реже. Ликвидируется зависимость от центрального узла – при сбое в отдельном узле системы целостность большей части базы данных сохраняется.
При работе с распределенной базой данных каждый компьютер является клиентом для одних компьютеров и сервером для других. Клиент может получить доступ к любому количеству серверов. Этот доступ может быть одновременным к нескольким серверам или реализовываться последовательно от сервера к серверу. Оптимальной является такая организация работы, когда от выполняемого приложения скрыты механизмы функционирования системы и создается впечатление, что обработка данных осуществляется одной СУБД, работающей на одном компьютере. Пользователи и приложения должны получать доступ к необходимым им данным, не имея информации о месте расположения этих данных.
Система распределения базы данных по нескольким компьютерам, расположенным в сети, с обеспечением возможности параллельного доступа к ней нескольких пользователей, называется системой распределенных баз данных.
При использовании в работе архитектуры «клиент-сервер» часто необходимо решать проблему унифицированного доступа к данным, созданным различными