

5617
.pdfyit =µ + β + αi + εit, |
εit НОР(0 |
, αi |
НОР(0 |
, |
где αi + εit рассматривается как |
остаточный |
член, |
состоящий |
из двух |
компонент: индивидуальной специфической компоненты, которая не изменяется во времени, и компоненты остатка, которая по предположению является не коррелированной во времени, таким образов, вся корреляция остатков во времени приписывается индивидуальным эффектам αi. Предполагается также, что αi и εit взаимно независимы и независимы от xjs (для всех j и s). Это означает, что МНК-оценки для µ и β в модели со случайными эффектами являются несмещёнными и состоятельными. Структура компонент остатков подразумевает, что составной остаток αi + εit будет иметь определённый вид автокорреляции (если 

 . Следовательно, обычно вычисляемые стандартные ошибки для МНК-оценок будут некорректны и этом случае лучше воспользоваться обобщённым МНК (ОМНК), используя структуру ковариационной матрицы остатков. Так можно получить ОМНК-оценку параметром модели со случайными эффектами.
. Следовательно, обычно вычисляемые стандартные ошибки для МНК-оценок будут некорректны и этом случае лучше воспользоваться обобщённым МНК (ОМНК), используя структуру ковариационной матрицы остатков. Так можно получить ОМНК-оценку параметром модели со случайными эффектами.
Оценки параметров модели со случайными эффектами получаются аналогично рассмотренным ранее оценкам с фиксированными эффектами из уравнения регрессии в отклонениях от индивидуальных средних, но взятых с
весами υ = 1 – ψ2, где ψ = |
): |
|
|
|
|
|
|||||
|
|
|
|
= µ |
|
|
|
|
|
β + uit. |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
||||||||
Оценки со случайными эффектами обозначаются как |
(random effects). |
||||||||||
При ψ = 0 имеем модель с фиксированными эффектами. При ψ = 1 ОМНК-оценка просто является МНК-оценкой. Можно показать, что ОМНКоценка является средневзвешенной оценкой внутригрупповой и межгрупповой оценок для вектора параметров β. Межгрупповая оценка является обычной МНК-оценкой вектора параметров β в модели индивидуальных средних:
 = µ +
= µ + β + αi +
β + αi +  , i = 1,2,…,n.
, i = 1,2,…,n.
Таким образом, ОМНК-оценка (оценка параметров модели со случайными эффектами) является матрично-взвешенным средним межгрупповой и внутригрупповой оценок, где веса зависят от соотношения дисперсий этих двух оценок.
Межгрупповая оценка игнорирует любую внутригрупповую информацию. ОМНК-оценка является оптимальной комбинацией
81

внутригрупповой и межгрупповой оценок и поэтому более эффективна, чем любая из этих двух оценок в отдельности. Если объясняющие переменные независимы от всех εit и всех αi, то ОМНК-оценка является несмещённой и состоятельной.
Отметим, что компоненты дисперсий  и
и  на практике неизвестны и оцениваются предварительно на основе реализуемого ОМНК. В разных статистических пакетах они могут оцениваться по-разному, поэтому результаты таких оценок могут различаться для разных пакетов.
на практике неизвестны и оцениваются предварительно на основе реализуемого ОМНК. В разных статистических пакетах они могут оцениваться по-разному, поэтому результаты таких оценок могут различаться для разных пакетов.
Оценка, полученная реализуемым ОМНК, называется оценкой со случайными эффектами для вектора неизвестных параметров β (и µ).
По аналогии с моделью с фиксированными эффектами встаёт вопрос: различаются ли компоненты ошибки αi у разных объектов наблюдения?
С этой целью вместо проверки гипотезы о том, что αi = αj для любых i,j формулируется гипотеза в соответствии с постановкой модели со случайными эффектами: H0 : αi = 0 против альтернативы Hа : αi > 0. Для проверки этой гипотезы применяют тест множителей Лагранжа с тестовой
статистикой вида (тест Бреуша – Пагана) |
|
||||||||
|
|
LM = |
|
|
|
|
)2. |
||
|
|
|
|
|
|
||||
Здесь |
|
|
Если верна нулевая |
||||||
|
|||||||||
гипотеза и выполняется предпосылка о нормальном распределении ошибок, LM-тест имеет асимптотическое χ2-распределение с одной степенью свободы. Если нулевая гипотеза отклоняется, то имеем модель со случайными эффектами, в противном случае – объединённую модель.
4.4. Фиксированные эффекты или случайные?
Имея две различные спецификации модели панельных данных, учитывающие индивидуальные эффекты, необходимо решить, какую из них предпочесть. Как было отмечено, каждая из таких моделей обладает своими преимуществами и недостатками. Недостатки модели с фиксированными эффектами состоят в необходимости оценивать большое число параметров и невозможности включить неизменные во времени переменные. Модель со случайными эффектами эти проблемы решает, но требует введения дополнительного предположения о некоррелированности специфического для каждого объекта слагаемого ошибки с регрессорами. А эта предпосылка
82

не всегда выполняется, что приводит к неэффективным оценкам случайных |
|
||||||||||||||
эффектов. Но если эта предпосылка выполнена, то рекомендуется применять |
|
||||||||||||||
модель со случайными эффектами. Таким образом, при выборе той или иной |
|
||||||||||||||
спецификации модели панельных данных, необходимо решить вопрос: |
|
||||||||||||||
зависят ли индивидуальные эффекты αi |
и регрессоры xit. |
|
|||||||||||||
Хаусман предложил тестировать эту гипотезу, исходя из следующих |
|
||||||||||||||
соображений. Необходимо сравнить две оценки вектора параметров β |
|
||||||||||||||
модели панельных данных: одна из них состоятельна как при нулевой |
|
||||||||||||||
гипотезе, так и при альтернативной, а другая состоятельна (и эффективна) |
|
||||||||||||||
только при нулевой гипотезе. Значимое различие между ними укажет, что |
|
||||||||||||||
нулевая гипотеза вряд ли будет справедлива. |
|
|
|
||||||||||||
Пусть |
εit и |
xis независимы |
при любых |
|
t и s, так что оценка с |
|
|||||||||
фиксированными |
эффектами |
|
|
является |
состоятельной для вектора |
Отформатировано: русский |
|||||||||
|
|
|
|||||||||||||
параметров β независимо от того, коррелированы ли xit и αi, тогда как оценка |
|
||||||||||||||
со случайными эффектами |
состоятельна и эффективна, только если xit и |
|
|||||||||||||
αi не коррелированы. |
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Рассмотрим вектор разностей |
|
|
|
|
|
|
|
. Чтобы оценить значимость этих |
|
||||||
|
|
|
|
|
|
||||||||||
разностей в соответствии с общим алгоритмом проверки статистических |
|
||||||||||||||
гипотез необходимо рассчитать определённую статистику, закон |
|
||||||||||||||
распределения которой известен при верности нулевой гипотезы. Хаусман |
|
||||||||||||||
показал, |
что если обе оценки, |
входящие в разность, имеют приближённо |
|
||||||||||||
нормальное распределение (а это так, если верна нулевая гипотеза), то и |
|
||||||||||||||
разность имеет то же распределение, тогда такой статистикой может быть |
|
||||||||||||||
|
|
H = ( |
|
|
|
|
|
|
)т( |
|
|
), |
|
||
|
|
|
|
|
|
|
|
|
|
|
|||||
где – оценка матрицы ковариаций |
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|||||||||
Если верна нулевая гипотеза (xit и αi |
не коррелированы), то эта статистика |
|
|||||||||||||
имеет асимптотическое χ2-распределение с к степенями свободы. Если |
|
||||||||||||||
расчётное значение этой статистики меньше критического (или расчётный |
|
||||||||||||||
уровень значимости больше принятого), то нулевая гипотеза не отклоняется |
|
||||||||||||||
и мы имеем модель со случайными эффектами. |
|
|
|
||||||||||||
Таким образом, критерий Хаусмана тестирует, значимо ли различие |
|
||||||||||||||
оценок с фиксированными и случайными эффектами. Необходимо отметить, |
|
||||||||||||||
что этот критерий асимптотический и в малых выборках ковариационная |
|
||||||||||||||
матрица |
может быть неположительно определённой, так что её обращение |
|
|||||||||||||
83

нельзя вычислить. В качестве альтернативы можно проводить такое тестирование лишь для подмножества элементов в векторе β.
4.5. Качество подгонки панельных данных моделью
Для стандартных моделей регрессии качество подгонки (при условии, что среди регрессоров есть константа) обычно измеряет коэффициент детерминации R2 или скорректированный коэффициент детерминации  .
.
При анализе панельных данных возникают некоторые проблемы с определением коэффициента детерминации, связанные с неопределённостью в отношении того, что считать полной суммой квадратов отклонений, подлежащей разложению на объяснённую регрессией и остаточную. Кроме того, модель со случайными эффектами оценивается с помощью обобщённого МНК, для которого коэффициент детерминации вообще не является адекватной мерой качества подгонки.
В контексте рассматриваемой проблемы полную вариацию независимой переменной yit можно записать в виде суммы внутригрупповой и межгрупповой вариаций, т.е.
(1/nT) 




 = (1/nT)
= (1/nT) 



 + (1/n)
+ (1/n) 



 ,
,
где  обозначает общее выборочное среднее. Теперь можно определить альтернативные версии меры R2 в зависимости от размерности анализируемых данных. При этом предполагается, что коэффициенты множественной детерминации определяются в терминах квадратов коэффициентов корреляции между реальными и расчётными (по соответствующей модели) значениями объясняемой переменной.
обозначает общее выборочное среднее. Теперь можно определить альтернативные версии меры R2 в зависимости от размерности анализируемых данных. При этом предполагается, что коэффициенты множественной детерминации определяются в терминах квадратов коэффициентов корреляции между реальными и расчётными (по соответствующей модели) значениями объясняемой переменной.
Например, в объединённой модели МНК-оценка максимизирует общую меру качества подгонки данных моделью, т.е. максимизирует общий R2, о котором говорят как о «R2-полном» или R2overall. Определяется он из соотношения
|
= corr2( , |
, |
где |
т . |
|
Оценка с фиксированными эффектами выбирается, чтобы наиболее полно
объяснить внутригрупповую вариацию, |
и поэтому максимизируется |
|||||
«внутригрупповой R2», заданный в виде |
|
|
|
|||
= corr2( |
|
|
|
),( |
|
|
|
|
|
|
|
||
|
|
|||||
Отформатировано: русский Отформатировано: русский
84

где 




 -
-  )т
)т . Такой коэффициент называется R2within. Межгрупповая оценка, являясь МНК-оценкой для модели в терминах
. Такой коэффициент называется R2within. Межгрупповая оценка, являясь МНК-оценкой для модели в терминах
индивидуальных средних, максимизирует «межгрупповой R2», который определяется как
|
|
= corr2( |
|
, , |
|
|
|||
где |
|
т . И такой коэффициент называется R2between. |
||
|
||||
Описанные коэффициенты детерминации можно определить для любой оценки  вектора параметров β, при этом естественно считать, что
вектора параметров β, при этом естественно считать, что 

 т
т ,
, 




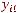 . Именно такой подход реализован в эконометрическом пакете STATA: при оценивании моделей с панельными данными вычисляются все три отмеченных коэффициента детерминации, независимо от того, какой метод оценивания применяется.
. Именно такой подход реализован в эконометрическом пакете STATA: при оценивании моделей с панельными данными вычисляются все три отмеченных коэффициента детерминации, независимо от того, какой метод оценивания применяется.
Следует отметить, что коэффициенты детерминации в моделях с панельными данными нецелесообразно использовать для того, чтобы определить, какой метод оценивания лучше. Однако эти коэффициенты можно применять для сравнения моделей, отличающихся набором регрессоров и оцениваемых одним и тем же методом.
Приведём пример анализа панельных данных на примере из Носко В. П. В нём рассматриваются три предприятия, каждое за 10 лет по двум показателям: y – объём инвестиций, x – прибыль. После структуризации информации, в рабочей области пакета EViews эти данные примут вид (рисунок 4.1).
Именно в таком виде (начиная со столбца F) эта информация и должна вноситься в базу данных пакета программ при анализе панельных данных.
85

Рисунок 4.1– Информация в рабочей области пакета EViews
Здесь F – индекс предприятия, YEAR – обозначение времени (10 лет). Графически эта информация представлена на рисунке 4.2.
Рисунок 4.2 – График исходной информации
86

Здесь первые 10 наблюдений – это 1-е предприятие за 10 лет, вторые 10 наблюдений – 2-е предприятие и последние – 3-е предприятие. Видно, что у 2-го предприятия, в отличие от 1-го и 3-го прибыль выше, чем инвестиции. Количественно это выглядит следующим образом:
Предприятие |
Инвестиции |
Прибыль |
|
|
|
1 |
155,02 |
153,97 |
|
|
|
2 |
150,15 |
165,59 |
|
|
|
3 |
143,13 |
128,58 |
|
|
|
Существенно ли это различие – попытаемся выяснить, используя модели панельных данных.
Приведём сначала расчёты в пакете EViews. Объединённая модель (без учёта структуры панельных данных – pooled) следующая (рисунок 4.3). Здесь она приведена для сравнительного анализа.
Рисунок 4.3 – Объединённая модель
Модель с фиксированными эффектами следующая (рисунок 4.4).
87

Рисунок 4.4– Модель с фиксированными эффектами
Сами эффекты в этой модели не вычисляются, но в пакете EViews есть опция, позволяющая их вычислить. Применив её, получим
Если использовать модель с фиктивными переменными (без константы), то получим (рисунок 4.5). Как видим, результаты этих двух методов вычисления эффектов не совсем совпадают. Показатели точности этих уравнений совпадают. Но особенности вычислений этих двух методов в том, что эффекты на рисунке 4.4 пронормированы таким образом, что их сумма равна нулю. И если эффекты на рисунке 4.5 пронормировать аналогичным образом, то получим то же самое, что и на рисунке 4.4.
Рисунок 4.5 – Модель с фиктивными переменными
88

При этом константа в уравнении модели с фиксированными эффектами (–1,323498) – это среднее арифметическое эффектов из модели с фиктивными переменными (рисунок 4.5). Вычтя это значение из эффектов модели на рисунке 4.5, получим в точности эффекты из рисунка 4.4.
Анализировать нормированные эффекты удобнее. Так, если попытаться проинтерпретировать численные значения эффектов (рисунок 4.4), то это можно сделать следующим образом. Как было отмечено в начале этого примера, второе предприятие отличается от 1-го и 3-го тем, что у него в анализируемом периоде прибыль выше инвестиций. Это и отмечено эффектами – у 2-го предприятия эффект с отрицательным знаком в отличие от эффектов 1-го и 3-го предприятий. Причём и численное значение эффектов показывает: различие в разности прибыли и инвестиций примерно одинаковое, но с обратным знаком, что и отражено в индивидуальных эффектах (рисунок 4.4).
И тем не менее фиксированные эффекты не объясняют вариацию между объектами, они только улавливают её. Т.е., если спросить, почему 2-е предприятие имеет прибыль больше, чем инвестиции по сравнению с другими анализируемыми предприятиями, то ответ, представляемый эффектами, есть просто: «потому, что это 2-е предприятие».
Рассчитаем модель со случайными эффектами. Получим (рисунок 4.6).
Рисунок 4.6 – Модель со случайными эффектами
89

Параметры этой модели оценены на основе обобщённого МНК с учётом ковариационной матрицы оценок, что и отражено в заголовке отчёта. Можно рассчитать индивидуальные случайные оценки (рисунок 4.7)
Рисунок 4.7 – Случайные эффекты
Они тоже нормированы под нулевое суммарное значение. И их интерпретация аналогична фиксированным эффектам.
Как было отмечено, тестирование, являются ли эффекты значимыми, можно определить на основе тестов Вальда и Бреуша – Пагана. Оба эти теста асимптотические, и в силу малого объёма выборки в анализируемом примере эти тесты здесь не приводятся.
По этой же причине можно было бы не приводить тест на спецификацию модели (с фиксированными эффектами или со случайными?), тем более, как отмечалось, результаты этого теста могут различаться при разных методах оценивания дисперсии остатков моделей. Тем не менее приведём для примера тест Хаусмана, рассчитанный в пакете EViews (рисунок 4.8). Как видим из отчёта работы этого теста, вероятность для χ2-статистики меньше 0,05, следовательно, гипотеза о значимом расхождении оценок по моделям с фиксированными и случайными эффектами отклоняется и можно предпочесть из этих моделей модель с фиксированными эффектами.
Рисунок 4.8 –Тест Хаусмана
90