

Зональное ранжирование.
Ранжирование – сортировка документов в поисковой выдаче.
Для решения этой задачи поисковые машины для каждого найденного документа вычисляют его степень соответствия заданному запросу, т.е. (вычисленная) релевантность 2 (score).
Электронные документы обычно сопровождаются метаданными (metadata), которые кодируются в виде, распознаваемом компьютерами. Под метаданными мы понимаем конкретные виды данных о документе, например фамилию автора, название и дату публикации. Эти метаданные обычно содержат поля метаданных (fields), например дату создания и формат документа3 , а также фамилию автора и, возможно, название документа. Множество возможных значений этих полей следует считать конечным, например множество всех дат создания документа ограничено
Зоны (zones) напоминают поля, но содержанием зоны может быть произвольный текст. В то время как поле может иметь относительно небольшое множество значений, зона может содержать произвольный и неограниченный объем текста. Например, названия документов и аннотации обычно трактуются как зоны.

Зональное ранжирование в Lucene.
Lucene позволяет влиять на результаты поиска 3 способами:
Повышение уровня документа – вызов document.setBoost() перед добавлением документа в индекс. Выставление весов документам.
Повышение уровня поля документа – вызов field.setBoost() перед добавлением поля в документ и перед добавлением документа в индекс. Выставление веса полям.
Повышение уровня запроса – вызов Query.setBoost(). В запросе задаем, у какого слова больший вес.
Повышение уровня – присвоение документам или атрибутам веса, а также способ сообщить системе, что атрибут или документ более важен, поэтому он будет отображаться выше в запросах.
Модель tf-idf.
До сих пор ранжирование документа зависело от того, присутствует ли термин запроса в зоне документа. Теперь мы сделаем следующий логичный шаг: документ или зона, где термин запроса встречается чаще, следует считать более релевантным запросу и присвоить ему более высокое значение релевантности
Для этого присвоим каждому термину, обнаруженному в документе, вес (weight), зависящий от количества появлений этого термина в данном документе. Мы хотим оценить соответствие между термином запроса t и документом d, основываясь на весе термина t в документе d. Проще всего положить этот вес равным количеству вхождений термина t в документ d. Эта схема взвешивания называется частотой термина (term frequency) и обозначается как tft,d, где индекс t обозначает термин, а индекс d — документ
Чаще встречается использование документной частоты dfi (document frequency), представляющей собой количество документов в коллекции, содержащих термин t. Это объясняется тем, что, пытаясь найти различия между документами с целью их ранжирования по запросу, лучше использовать статистические показатели именно самих документов (например, количество документов, содержащих заданный термин), чем статистические показатели коллекции в целом
TF – число вхождений некоторого слова в документ к общему числу слов.
IDF – инверсия частоты, с которой слово встречается в документах коллекции.
 ,
где
N
– кол-во документов,
,
где
N
– кол-во документов,
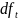 –
число документов, в которых встречается
t.
–
число документов, в которых встречается
t.
TF-IDF – векторная модель документа, статическая мера для оценки важности слова в контексте документа.

Мера TF-IDF – произведение двух множителей tf и idf.


Опорная нормировка длины документа.
Вероятная
релевантность оценивается как функция
от длины документа. При опорной нормировке
приведем график ранжирования по
косинусной мере. Нормализация при
 -кол-во
уникальных терминов в документе d,
примет вид:
-кол-во
уникальных терминов в документе d,
примет вид:
 ,
где
,
где
 – угловой коэффициент,
– угловой коэффициент,
 – точка пересечения с графиком косинусной
нормализации. Осталось оптимизировать
эти 2 параметра.
можно зафиксировать как среднее значение
по всей коллекции и свести к оптимизации
.
– точка пересечения с графиком косинусной
нормализации. Осталось оптимизировать
эти 2 параметра.
можно зафиксировать как среднее значение
по всей коллекции и свести к оптимизации
.

Ранжирование в Lucene. Модель BM25.


Модель ВМ25 - TF-IDF-подобная функция ранжирования, используемая поисковыми системами для упорядочивания документов по их релевантности. Функция BM25 даёт следующую оценку релевантности документа D {\displaystyle D}запросу Q:
 ,
где
,
где
 {\displaystyle
Q}
-
частота
слова,
{\displaystyle
Q}
-
частота
слова,
 – длина документа,
– длина документа,
 – средняя длина документа в коллекции,
– средняя длина документа в коллекции,
 и
и
 – свободные коэффициенты,
– свободные коэффициенты,
 ,
b
= 0.75.
,
b
= 0.75.