

Организация словарей.
Перестановочный индекс.
Перестановочный индекс индексирует все циклические перестановки заголовков.
k-граммный индекс.
k-грамма – пос-ть, состоящая из k символов. k-граммный индекс содержит все k-граммы, образованные из всех терминов лексикона. Каждый инвертированный список ставит в соответствие К-грамме все термины лексикона, её содержащие.
Поиск по числовым полям.
Поиск по числовым полям позволяет выполнять сравнительные и вычислительные запросы для числовых полей. Например, можно выполнить поиск документов определенного размера.
Геопоиск.
Геопоиск – поиск объекта на карте по его координатам. Пример геопоиска с помощью индексов: разбить рассматриваемую местность на площади (блоки) и пометить двузначными индексами, например, по номерам линий вдоль и поперек. Каждый такой блок можно аналогично разбить на блоки и таким же образом задать индекс, и т.д.
Сжатие индекса.
Чтобы обеспечить эффективное хранение индексов слов, встречающихся в веб-страницах, для каждого слова необходимо сохранить номера страниц, в которых они встречаются, и сжать данные, обеспечив эффективный доступ к ним.
Словарь – это простой массив, содержащий встреченные слова и смещение в дисковом файле, где хранятся номера страниц, где встречается данное слово. Чтобы повысить эффективность, эти данные должны быть отсортированы.
Преимущества сжатия.
Меньше требуется ресурсов для хранения
Быстрая загрузка данных с диска на память
Быстрая загрузка данных из памяти в кэш процессора
Закон Хипса.
оценка количества терминов в словаре
Закон Хипса – эмпирическая закономерность в лингвистике, описывающая распределение числа разных слов в документе. Формула:

Где М – количество различных терминов, Т – количество лексем в коллекции (размер документа), b ≈ 0.5 и 30 ≤ k ≤ 100 – свободные параметры, определяемые эмпирически.
Параметр k изменяется в довольно широких пределах, поскольку рост лексикона во многом зависит от природы коллекции и способа ее обработки. 3 Свертывание регистра и стемминг уменьшают скорость роста размера лексикона, в то время как включение чисел и орфографических ошибок увеличивает ее. Независимо от значений параметров для конкретной коллекции закон Хипса утверждает, что 1) при увеличении количества документов в коллекции размер лексикона продолжает возрастать, пока не достигнет максимального уровня, и 2) размер лексикона для крупных коллекций достаточно велик. Эти две гипотезы для больших коллекций доказаны эмпирически (раздел 5.4). Таким образом, сжатие словаря играет важную роль для повышения качества систем информационного поиска.
Закон Ципфа.
моделирование распределения терминов
Закон
Ципфа – эмпирическая закономерность
распределения частоты слов естественного
языка: если все слова языка (или текста)
упорядочить по убыванию частоты их
использования, то частота n-го
слова

Словарь как строка.
Словарь можно преобразовать в строку для экономии памяти и хранить только числовые позиции начала каждой из строк.
Хранить термины как элементы фиксированной длины нецелесообразно. Средняя длина термина в английском языке — примерно восемь символов (см. табл. 4.2), поэтому при такой схеме в среднем мы тратим впустую 12 символов. Кроме того, у нас нет возможности хранить термины длиннее 20 символов, такие как hydrochlorofluorocarbons или supercalifragilisticexpialidocious. Для решения этой проблемы можно хранить словарь в виде одной длинной строки, как показано на рис. 5.4. Указатель на следующий термин можно использовать для идентификации конца текущего термина. Как и прежде, мы ищем термины в структуре данных с помощью бинарного поиска в (теперь меньшей) таблице. По сравнению с предыдущей схемой эта схема экономит 60% памяти, поскольку мы выделяем на термин в среднем 12 байт вместо 20

Блочное хранение.
Блочное хранение – ещё более сжатый вид хранения словаря, при нём мы храним начало блока, а в блоках размеры слов.
Словарь можно сжать еще больше, сгруппировав термины в строке по блокам размером k и храня указатель только на первый термин каждого блока (рис. 5.5). Длина термина хранится в строке в виде дополнительного байта в начале термина. Таким образом, мы исключаем k - 1 указателей на термины, но требуем дополнительно k байт для хранения длины каждого термина. При k = 4 мы экономим (k - 1) × 3 = 9 байт на каждом указателе на термин, но требуем дополнительно k = 4 байт для хранения длин терминов. Итак, общие требования к памяти для хранения лексикона коллекции Reuters–RTV1 уменьшаются на 5 байт на каждый из блоков, состоящих из четырех терминов. В целом этот объем составляет 400 000 × 1/4 × 5 = 0,5 Мбайт, т.е. размер требуемой памяти снижается до 7,1 Мбайт.
Мы не использовали еще один источник избыточности при хранении словаря — тот факт, что последовательные элементы в списке, упорядоченном по алфавиту, имеют одинаковые префиксы. Это наблюдение приводит к фронтальной упаковке (front coding) (рис. 5.7). Мы сначала идентифицируем общий префикс для фрагмента списка терминов, а затем помечаем его специальным символом. Эксперимент показал, что для коллекции Reuters фронтальная упаковка экономит еще 1,2 Мбайт

Сжатие инвертированного индекса.
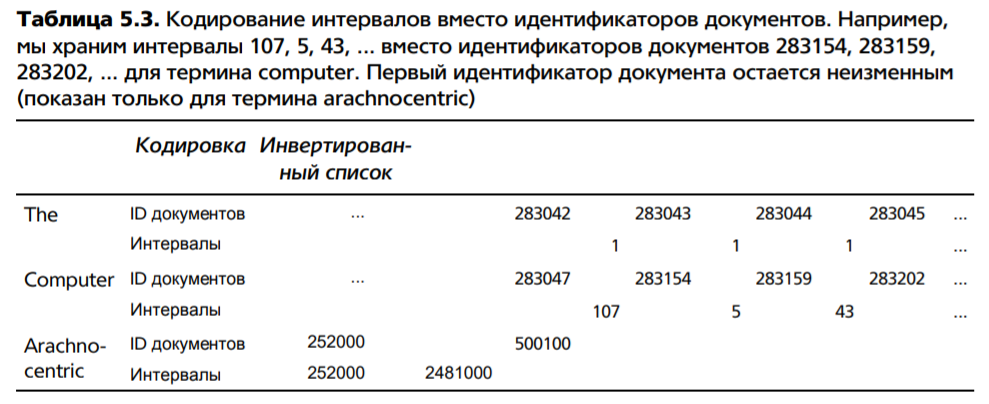
В индексе есть слово и id-шники документов, в которых оно встречается. Идшники могут быть большими, поэтому можно хранить не сами идшники, а разницы между ними. Для этого используется кодирование переменной длины: в каждом байте храним 7 бит числа и один бит на флаг, закончилось ли число. На число может хватить одного или двух битов.
Ключевая идея заключается в том, что интервалы между словопозициями являются короткими и для их хранения требуется меньше 20 бит. На практике интервалы между наиболее частыми терминами, таким как the и for, чаще всего равны единице. Однако пробелы между редкими терминами, встречающимися в коллекции лишь один или два раза (например, слово arachnocentric в табл. 5.3), по величине мало отличаются от идентификаторов документов и требуют для хранения 20 бит. Для экономного представления такого распределения интервалов необходим метод упаковки с использованием кодов переменной длины (variable encoding method), который для более коротких интервалов использует меньше битов.
Байтовое кодирование переменной длины (variable byte encoding — VB, или variable byte coding — VBC) использует для кодирования интервалов целое количество байтов. Последние 7 бит в каждом байте являются “полезной нагрузкой” и кодируют часть интервала. Первый бит байта является битом продолжения (continuation bit). Он равен единице у последнего байта закодированного интервала и нулю в остальных случаях
Для декодирования кода, закодированного переменным количеством байтов, считывается последовательность байтов, бит продолжения которых равен нулю, завершающаяся байтом, в котором бит продолжения равен единице. Затем извлекаются и конкатенируются семибитовые части
