

MM_dlya_LR
.pdfпоследовательности нулей и единиц с равной вероятностью, в смеси с аддитивной гауссовской помехой. Порог решения в приемнике выбран равным нулю. Логика принятия решения следующая: если амплитуда смеси сигнала и помехи больше нуля - принимается решение о передаче единицы, если меньше нуля - нуля.
По полученному выражению определить амплитуду импульсов если действующее напряжение помехи равно 0,8 В и требуется обеспечить вероятность ошибки pe 2 10 7 .
Отчет по работе
Отчет должен состоять из разделов, соответствующих разделам работы и включать сведения о содержании исследований, полученные результаты, их оценки и объяснения, а также использованные для расчетов формулы.
Примерный план отчета:
наименование работы;
наименование разделов и их содержание;
таблицы, отражающие исследования с оценками результатов;
выводы и пояснения.
ПРИЛОЖЕНИЕ 1.
РАБОТА С ПРОГРАММОЙ
Лабораторная работа выполняется на персональном компьютере (ПК) в среде «MATLAB». Для запуска графического интерфейса (рис.1) следует в командном окне «MATLAB» набрать «rp» и нажать клавишу «Enter».
Рис. 1 Внешний вид графического интерфейса лабораторной работы.
В лабораторной работе исследуются вероятностные характеристики случайного процесса.
Для начала работы нужно ввести вариант работы, заданный преподавателем.
Указать длину реализации случайного процесса. После каждой реализации н вычисления математического ожидания и дисперсии следует нажимать кнопку «Обновить данные». Результаты моделирования представляются на экране ПК в виде графиков и таблицы. Для этого следует нажимать по порядку следующие кнопки на графическом интерфейсе работы.
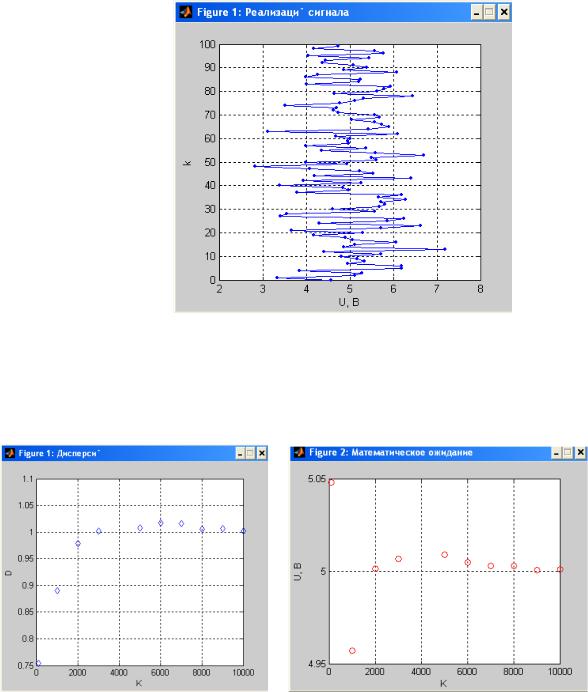
Зависимости, исследуемые в первой части работы приведены на рис. 2-5. Пример реализации случайного процесса показан на рис. 2.
Рис. 2 Графики зависимости дисперсии и математического ожидания от объема выборки
(длины реализации) показаны на рис. 3, 4. На рис. 5 показан вид графического интерфейса с указанием длины каждой исследуемой реализации и результатов вычислений дисперсии и математического ожидания по данной реализации.
Рис.3 |
Рис. 4 |
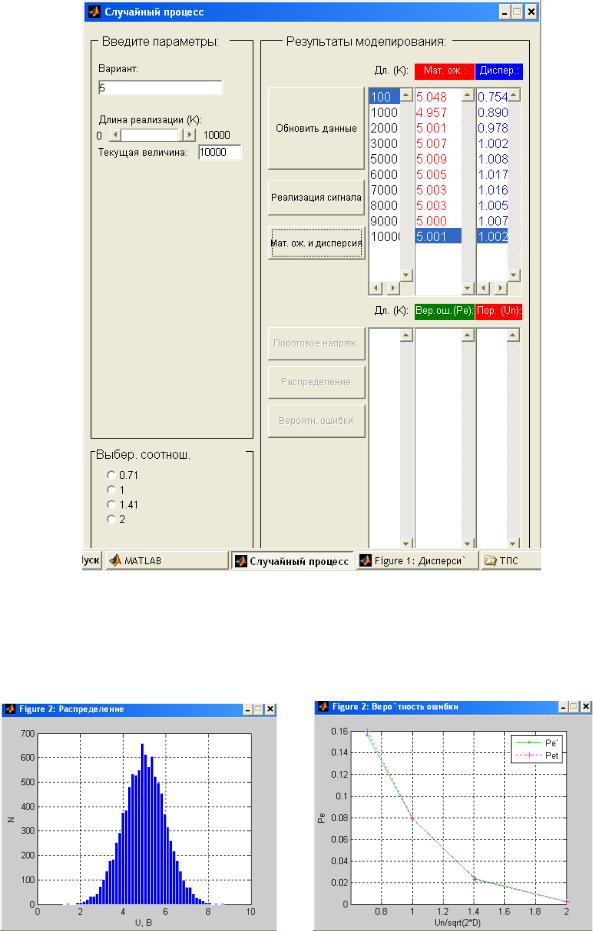
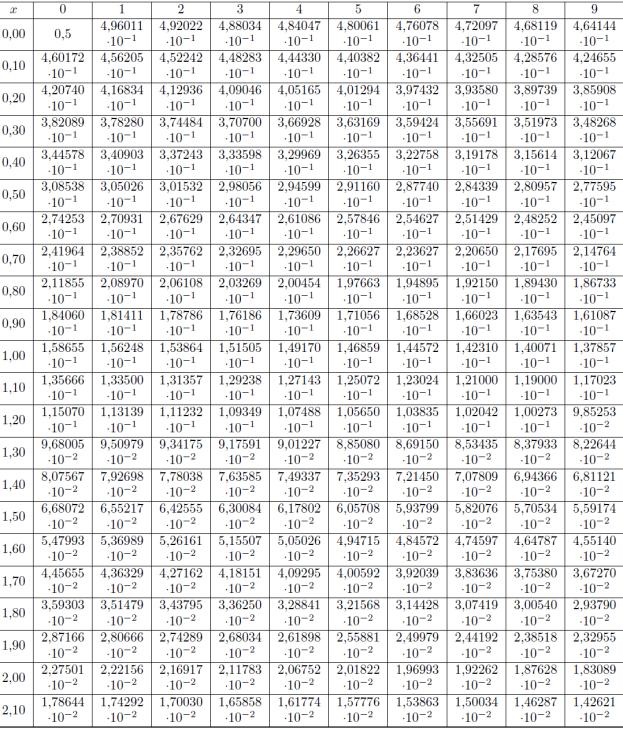
Рис.5 Зависимости, исследуемые во второй части работы показаны на рис. 6,7.
На рис. 6 показана гистограмма распределения амплитуд исследуемого случайного процесса. На рис. 7 показаны теоретическая и экспериментальные зависимости вероятности превышения амплитудой случайного процесса заданного порога.
Рис.6 |
Рис.7 |
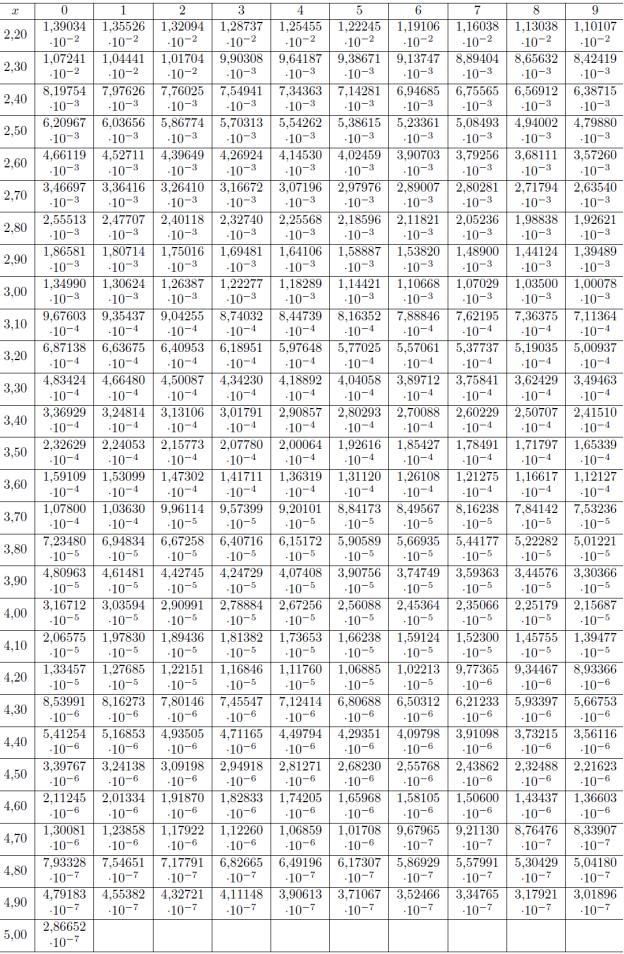
ПРИЛОЖЕНИЕ 2.
Таблица функции ошибок
Лабораторная работа № 4
Цель работы: Закрепление теоретических знаний о моделях дискретных источников информации и их свойствах. Приобретение навыков статистических исследований сообщений источников и определение их информационных характеристик, а также навыков статистического кодирования.
Содержание работы:
1)определение статистических характеристик источника по заданному его сообщению;
2)определение информационных характеристик источника и оценка влияния на них неравновероятности и взаимозависимости букв;
3)статистическое кодирование сообщений источника без учета и с учетом взаимозависимости букв, оценка эффективности различных алгоритмов сжатия сообщений.
Теоретические сведения
В теории передачи информации количество информации в сообщении определяется только вероятностными (статистическими) свойствами сообщений. Все другие её свойства, например, полезность, интонации или принадлежность автору, игнорируются.
Пусть {X, p(x)} ансамбль сообщений, Х={х1,х2,...,хL}, p(xi)-вероятность i-го сообщения. Количеством собственной информации или собственной информацией в сообщении хi называется число I(xi), определяемое как:
I(xi) = -log(p(xi)), i = 1, 2, ..., L
Если основание логарифма-2, то количество информации измеряется в битах, если 10, то в дитах. В дальнейшем, если не будет оговорено особо, подразумевается основание
2.
Свойства информации:
1.Информация всегда неотрицательна: I 0.
2.Для независимых сообщений p(xi,yj) = p(xi) p(yj), следовательно: (свойство аддитивности)
I(xi,yj) = I(xi) + I(yj)
Математическое ожидание H(X) случайной величины I(x), определенной на
ансамбле {X, p(x)}, называется энтропией этого ансамбля:
L |
L |
H(X) = M I(x) = I(xi) p(xi) = - p (xi) log(p (xi)) |
|
i =1 |
i =1 |
(M-оператор математического ожидания).
Иными словами - это среднее количество собственной информации в сообщениях ансамбля Х. Энтропия рассматривается также как мера беспорядка в системе.
Свойства энтропии:
1.Энтропия неотрицательна: Н(Х) 0.
2.Энтропия не может превышать логарифма количества сообщений: H(X) < logL.
3.Для статистически независимых сообщений: (свойство аддитивности)
H(XY) = H(X) + H(Y)
Поставим в соответствие каждому сообщению xi в соответствие код ai из некоторого алфавита A={a1,a2,...,aL}. Тогда, стоимостью кодирования будет называться величина

L C(X) =  ai
ai  p(xi)
p(xi)
i=1
где |a|-длина кода a в битах. В случае, когда длины всех кодов одинаковы и равны logL, мы получаем: C(X)=logL. Иначе говоря, под стоимостью кодирования понимается средняя длина кодового слова в битах (то же самое, что и Hmax).
Условная собственная информация сообщения х при известном сообщении y:
I(x|y) = -log(p(x|y))
Условная энтропия ансамбля Х относительно сообщения y:
|
L |
|
|
L |
|
H(X | y) = p(xi | y) I(xi | y) p(xi | y) log(p(xi | y)) |
|||||
|
i=1 |
|
|
i=1 |
|
Условная энтропия ансамбля Х относительно ансамбля Y (средняя условная |
|||||
энтропия): |
|
|
|
|
|
|
N |
|
L |
N |
|
H(X | Y) = M H(X | yj) = |
|
p(yj) H(X | yj) = - |
|
p(xi, yj) log(p(xi | yj)) |
|
|
|
|
|||
|
j=1 |
|
i=1 |
j=1 |
|
Свойства:
1.H(X|Y) H(X), и равно, если ансамбли независимы.
2.H(XY) = H(X) + H(Y|X) = H(X|Y) + H(Y) H(X) + H(Y)
Относительная энтропия H - отношение энтропии источника к максимальному значению, которое могло бы быть достигнуто при тех же символах: H = H/Hmax = H/С.
Избыточность кодирования R равна разности между стоимостью кодирования C и энтропией H: R = C - H.
Величина R для декодируемых сообщений всегда больше нуля и в пределе, для идеального архиватора должна стремиться к нулю. Относительная избыточность определяется по формуле:
R = (1- H) 100% |
C - H |
100% |
|
C |
|||
|
|
Если средняя длина кодового слова входного текста равна Т, то в случае выполнения неравенства T > С мы можем говорить о том, что имеет место сжатие информации. С помощью идеального архиватора, для которого R=0, можно определить избыточность входного текста Rt:
Rt = T - H = T - C (бит).
Сжатие сообщений (графических изображений, видеоизображений и звука) — процедура их перекодирования, производимая с целью уменьшения их объёма. Применяется для более рационального использования устройств хранения и передачи данных.
Сжатие основано на устранении избыточности информации, содержащейся в исходных данных.
Примером избыточности является повторение в тексте фрагментов (например, слов естественного или машинного языка). Подобная избыточность обычно устраняется заменой повторяющейся последовательности более коротким значением (кодом). Другой вид избыточности связан с тем, что некоторые значения в сжимаемых данных встречаются чаще других, при этом возможно заменять часто встречающиеся данные более короткими кодами, а редкие — более длинными (вероятностное сжатие). Сжатие данных, не обладающих свойством избыточности (например, случайный сигнал или шум), невозможно без потерь. Также, обычно невозможно сжатие зашифрованной информации.
Алгоритмы сжатия Сжатие без потерь
Возможно восстановление исходных данных без искажений используется при обработке компьютерных программ и данных, реже — для сокращения объёма звуковой, фото- и видеоинформации
Наиболее известные:
Преобразование Барроуза-Уилера; преобразование Шиндлера; алгоритм DEFLATE; Дельта-кодирование; Энтропийное кодирование; Инкрементное кодирование; Алгоритмы Лемпеля — Зива; LZ77; LZ77-PM; LZFG; LZFG-PM; LZP; LZBW; LZSS; LZB; LZH; LZRW1; LZ78; LZW; LZW-PM; LZMW; LZMA; LZO; PPM; RLE; SEQUITUR; Вейвлет;
Алгоритм Шеннона — Фано; Алгоритм Хаффмана; Адаптивное кодирование Хаффмана; Усечённое двоичное кодирование; Арифметическое кодирование; Адаптивное арифметическое кодирование; Кодирование расстояний; Энтропийное кодирование; Унарное кодирование; Кодирование Фибоначчи; Кодирование Голомба; Кодирование Райса; Кодирование Элиаса.
Сжатие с потерями
Восстановление возможно с искажениями, несущественными с точки зрения дальнейшего использования восстановленных данных применяется для сокращения объёма звуковой, фото- и видеоинформации, оно значительно эффективнее сжатия без потерь.
Наиболее известные:
JPEG; Линейное предсказывающее кодирование; А-закон; Мю-закон; Фрактальное сжатие; Трансформирующее кодирование; Векторная квантизация; Вейвлетное сжатие.
Описание некоторых алгоритмов без потерь Алгоритм RLE (вариант 1)
Известен также как алгоритм PPM
Групповое кодирование — от английского Run Length Encoding (RLE) — один из самых старых и самых простых алгоритмов архивации графики.
Изображение в нем (как и в нескольких алгоритмах, описанных ниже) вытягивается в цепочку байт по строкам растра.
Само сжатие в RLE происходит за счет того, что в исходном изображении встречаются цепочки одинаковых байт.
Замена их на пары "счетчик повторений" - "значение" уменьшает избыточность данных.
Алгоритм рассчитан на деловую графику — изображения с большими областями повторяющегося цвета.
Ситуация, когда файл увеличивается, для этого простого алгоритма не так уж редка. Ее можно легко получить, применяя групповое кодирование к обработанным цветным фотографиям.
Данный алгоритм реализован в формате PCX.
Алгоритм RLE (вариант 2)
Имеет больший максимальный коэффициент архивации и меньше увеличивает в размерах исходный файл.
Алгоритм декомпрессии для него выглядит так: Признаком повтора в данном алгоритме является единица в старшем разряде соответствующего байта. Похожие схемы компрессии использована в качестве одного из алгоритмов, поддерживаемых форматом TIFF, а также в формате TGA.
Характеристики алгоритма RLE: Коэффициенты компрессии: Первый вариант: 32, 2, 0,5.
Второй вариант: 64, 3, 128/129. (Лучший, средний, худший коэффициенты)
Класс изображений: Ориентирован алгоритм на изображения с небольшим количеством цветов: деловую и научную графику.
Симметричность: Примерно единица.
Характерные особенности: К положительным сторонам алгоритма можно отнести только то, что он не требует дополнительной памяти при архивации и разархивации, а также быстро работает. Интересная особенность группового кодирования состоит в том, что степень архивации для некоторых изображений может быть существенно повышена всего лишь за счет изменения порядка цветов в палитре изображения.
Особенности изображения, за счет которых происходит сжатие - подряд идущие одинаковые цвета: 2 2 2 2 2 2 2 15 15 15.
Коэффициенты сжатия - 32, 2, 0.5
Семейство алгоритмов LZ
LZW по первым буквам фамилий его разработчиков — Lempel, Ziv и Welch. Сжатие в нем, в отличие от PCX, осуществляется уже за счет одинаковых цепочек байт.
Один из достаточно простых вариантов этого алгоритма, например, предполагает, что во входном потоке идет либо пара , либо просто “пропускаемых” байт и сами значения байтов (как во втором варианте алгоритма RLE). При разархивации для пары копируются байт из выходного массива, полученного в результате разархивации на байт раньше, а значений “пропускаемых” байт просто копируются в выходной массив из входного потока. Данный алгоритм является несимметричным по времени, поскольку требует полного перебора буфера при поиске одинаковых подстрок. В результате нам сложно задать большой буфер из-за резкого возрастания времени компрессии. Максимальный коэффициент сжатия составит в пределе 8192 раза. В пределе, поскольку максимальное сжатие мы получаем превращая 32Кб буфера в 4 байта, а буфер такого размера мы накопим не сразу. Однако, минимальная подстрока, для которой нам выгодно проводить сжатие должна состоять в общем случае минимум из 5 байт, что и определяет малую ценность данного алгоритма. К достоинствам LZ можно отнести чрезвычайную простоту алгоритма декомпрессии.
LZMA
Сокращение от англ. Lempel-Ziv-Markov chain-Algorithm.
LZO
Алгоритм компрессии данных ориентированный на скорость.
Алгоритм LZW
Рассматриваемый нами ниже вариант алгоритма будет использовать дерево для представления и хранения цепочек. Очевидно, что это достаточно сильное ограничение на вид цепочек, и далеко не все одинаковые подцепочки в нашем изображении будут
использованы при сжатии. Однако в предлагаемом алгоритме выгодно сжимать даже цепочки, состоящие из 2 байт.
Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока и проверяем, есть ли в созданной нами таблице строк такая строка. Если строка есть, то мы считываем следующий символ, а если строки нет, то мы заносим в поток код для предыдущей найденной строки, заносим строку в таблицу и начинаем поиск снова.
В случае, если мы постоянно будем встречать новую подстроку, мы запишем в выходной поток 3810 кодов, которым будет соответствовать строка из 3808 символов. Без учета замечания 1 это составит увеличение файла почти в 1.5 раза.
LZW реализован в форматах GIF и TIFF. Характеристики алгоритма LZW:
Коэффициенты компрессии: Примерно 1000, 4, 5/7 (Лучший, средний, худший коэффициенты) Сжатие в 1000 раз достигается только на одноцветных изображениях размером кратным примерно 7 Мб (6.918...).
Класс изображений: Ориентирован LZW на 8-битные изображения, построенные на компьютере. Сжимает за счет одинаковых подцепочек в потоке.
Симметричность: Почти симметричен, при условии оптимальной реализации операции поиска строки в таблице.
Характерные особенности: Ситуация, когда алгоритм увеличивает изображение, встречается крайне редко. LZW универсален — именно его варианты используются в обычных архиваторах.
Особенности изображения, за счет которых происходит сжатие - Одинаковые подцепочки: 2 3 15 40 2 3 15 40
Коэффициенты сжатия - 1000, 4, 5/7.
Алгоритм Хаффмана
Один из классических алгоритмов, известных с 60-х годов. Использует только частоту появления одинаковых байт в изображении. Сопоставляет символам входного потока, которые встречаются большее число раз, цепочку бит меньшей длины. И, напротив, встречающимся редко — цепочку большей длины. Для сбора статистики требует двух проходов по изображению.
На практике используются его разновидности. Так, в некоторых случаях резонно либо использовать постоянную таблицу, либо строить ее “адаптивно”, т.е. в процессе архивации/разархивации. Эти приемы избавляют нас от двух проходов по изображению и необходимости хранения таблицы вместе с файлом. Кодирование с фиксированной таблицей применяется в качестве последнего этапа архивации в JPEG и в рассмотренном ниже алгоритме CCITT Group 3.
Характеристики классического алгоритма Хаффмана:
Коэффициенты компрессии: 8, 1,5, 1 (Лучший, средний, худший коэффициенты) Класс изображений: Практически не применяется к изображениям в чистом виде.
Обычно используется как один из этапов компрессии в более сложных схемах. Симметричность: 2 (за счет того, что требует двух проходов по массиву сжимаемых
данных).
Характерные особенности: Единственный алгоритм, который не увеличивает размера исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).