

Змеев с.А., Волков д.В., Селютин и.Н., Гуляев о.А., Змеев а.А.
АКТУАЛЬНОСТЬ ПРОБЛЕМЫ ИНФОРМАЦИОННОЙ БЕЗОПАСНОСТИ СИСТЕМ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА
Рассматриваются вопросы информационной безопасности (ИБ) систем электронного документооборота (СЭД) и формализуются требования, выполнение которых обеспечивает ИБ СЭД
Увеличение документооборота в стране потребовало бурному развитию электронного документооборота. Электронный документооборот представляет собой обмен электронными, юридически значимыми документами с помощью систем электронного документооборота (СЭД). В общем виде электронный документ представляет собой цифровое отображение информации, носителем которого являются средства вычислительной техники и информатики. Правовой основой широкого внедрения электронного документооборота в информационные потоки между российскими организациями стало принятие закона об электронной цифровой подписи (ЭЦП) /1/. Современные СЭД успешно решают задачи автоматизации делопроизводства. Ежегодные темпы роста российского рынка СЭД, по мнению аналитиков, составляют не менее 30% и, ожидается, что темпы роста рынка СЭД в ближайшие годы сохранятся [2]. СЭД организуют все процессы жизненного цикла документа, включая работу над проектами, согласование, утверждение (подписание), исполнение, отправку в «дело» или архив. Кроме того, эти системы обеспечивают необходимый сервис для хранения, поиска и систематизации электронных документов, а также разделения прав доступа к ним. Осуществление электронного документооборота позволяет значительно повысить оперативность и «прозрачность» обращения документов.
Особенностью функционирования СЭД является работа в многопользовательском режиме с информацией разного уровня конфиденциальности. Согласно [3] «конфиденциальность информации - обязательное для выполнения лицом, получившим доступ к определенной информации, требование не передавать такую информацию третьим лицам без согласия ее обладателя». Кроме того, пользователи СЭД имеют различные полномочия по доступу к информации, циркулирующей в системе. Поэтому особое внимание при создании и эксплуатации СЭД необходимо уделять информационной безопасности (ИБ). В качестве угроз безопасности электронной информации, циркулирующей в СЭД, выступают, прежде всего, внутренние дестабилизирующие факторы (несанкционированные действия пользователей системы, выступающих в качестве субъектов доступа (СД) СЭД); внешние (действия злоумышленников); особенности среды передачи данных (возможное искажение либо перехват информации при использовании открытых каналов связи, в том числе через Интернет), а также возможные сбои оборудования (программ). Эти угрозы достаточно серьезны и, несмотря на высокие показатели надежности существующих СЭД, уровень развития аппаратного и программного обеспечения не гарантирует абсолютной надежности хранения и передачи информации в электронном виде. Поэтому для обеспечения ИБ СЭД актуальной является проблема создания системы защиты информации (СЗИ), входящей в СЭД в качестве подсистемы, обеспечивающей комплексную защиту конфиденциальной информации от вышеназванных угроз.
В общем виде система защищенного электронного документооборота (СЗЭД), в которой циркулирует конфиденциальная информация, должна в полном объеме реализовывать требования действующих руководящих документов ФСТЭК России и обеспечивать:
идентификацию и аутентификацию каждого СД;
авторизацию созданного исполнителем документа или действий над ним — за счет закрепления за каждым СД электронной цифровой подписи;
подлинность и целостность информации (документа) — за счет автоматической проверки ЭЦП;
шифрование конфиденциальной информации при ее передаче;
шифрование базы данных на жестком диске сервера;
импорт идентификационных данных, который исключал бы возможность обмена информацией с «подставным» сервером;
защиту от сбоев;
наличие программируемых (гибких) прав доступа (в том числе по правам копирования, печати и отправке документов) и другие.
Но даже в этом случае остаются проблемные вопросы обеспечения ИБ, такие, как: возможность доступа администратора защиты (безопасности) информации к защищаемым информационным ресурсам СЗЭД; риск хищения идентификационных и аутентификационных данных; несанкционированное копирование информации и ряд других. Для противодействия таким угрозам необходимо реализовать разграничение доступа пользователей и обслуживающего персонала к информационным ресурсам СЭД, программным средствам обработки (передачи) и защиты информации, а также регистрацию их действий.
Безопасность СЗЭД может быть обеспечена при выполнении следующих условий:
1. Выполнение требований установленной политики безопасности, под которой понимается совокупностью законов, правил и норм, определяющих обработку, распространение и защиту информации, причем, в зависимости от применяемой политики можно выбирать конкретные механизмы, обеспечивающие безопасность системы на основе проведенного анализа возможных угроз и выбора мер противодействия.
2. Оценка и контроль эффективности СЗИ СЭД, которая показывает, насколько корректны механизмы, отвечающие за проведение в жизнь политики безопасности.
3. Протоколирование и анализ всех событий, относящихся к безопасности системы.
Итак, для обеспечения безопасности конфиденциальных сведений в СЭД необходимо комплексное применение как программно-аппаратных систем и средств защиты информации, так и реализацией организационных мероприятий по обеспечению ИБ.
Литература
Федеральный закон от 10.01.2002 № 1-ФЗ «Об электронной цифровой подписи».
Электронный документооборот: за и против. «Советы бывалых» / Секретарское дело. 2010, № 2. С 12-21.
Об информации, информационных технологиях и о защите информации: федер. закон № 149-ФЗ от 27 июля 2006.
Воронежский государственный технический университет
УДК 621.3
И.Н.Селютин, Д.В. Волков, В.С. Гундарев
К ВОПРОСУ ФОРМИРОВАНИЯ ОПТИМАЛЬНОЙ СТРУКТУРЫ СИСТЕМ ЗАЩИТЫ ИНФОРМАЦИИ ОТ НСД В АВТОМАТИЗИРОВАННЫХ СИСТЕМАХ
В статье рассматривается способ формирования оптимальной структуры систем защиты информации от НСД (СЗИ НСД) в существующих автоматизированных системах (АС) на основе применения классического метода оптимизации (задачи о наименьшем покрытии)
Как показал опыт эксплуатации современных АС, наибольший вклад в нарушения информационной безопасности (ИБ) этих систем вносят факты НСД к информации и вычислительным ресурсам. Сложность решения проблем защиты информации (ЗИ) от НСД в АС обусловлена необходимостью создания СЗИ НСД, которая могла бы парировать существующие различные угрозы НСД и значительно затруднять доступ злоумышленника к различным ресурсам АС.
При разработке СЗИ НСД требуется решить два типа задач: осуществить синтез (структурный и параметрический) проектируемой системы в рамках возможных угроз НСД и провести анализ ее эффективности в процессе функционирования с целью выбора наиболее эффективных вариантов СЗИ НСД /1/. При этом решение такого рода задач осложняется тем, что для каждого структурного элемента СЗИ НСД и выполняемой функции возможно применение различных программных средств, во множестве представленных на рынке. Следовательно, возможно построить множество вариантов этих систем в конкретной АС, отличающихся структурой, составом, технико-экономическими и другими показателями.
Целью данной статьи является разработка способа формирования оптимальной структуры СЗИ НСД в АС на основе алгоритма решения задачи о наименьшем покрытии.
Представим множество угроз ИБ в АС и множество СЗИ, предлагаемых для включения в структуру разрабатываемой СЗИ НСД, в виде матрицы, в которой строки соответствуют угрозам, а столбцы – конкретным средствам ЗИ от НСД. Тогда элемент aij=1, если j-е средство ЗИ реализует защиту от i-ой угрозы НСД, в противном случае aij=0. При этом каждая строка матрицы должна содержать единицу хотя бы в одном столбце, т.е. защиту от данной угрозы реализует хотя бы одно средство защиты. Тогда задача минимизации сводится к поиску наименьшего числа столбцов, «покрывающих» все строки, т.е. минимального набора средств, реализующих ЗИ от всех потенциальных угроз. Кроме того, каждому столбцу ставится в соответствие некоторая стоимость cj и требуется выбрать покрытие с наименьшим общей стоимостью. Под стоимостью (или, в другой терминологии, весом) может подразумеваться вероятность преодоления j-го средства ЗИ.
ЗНП
своим названием обязана следующей
теоретико-множественной интерпретации.
Даны множество R={r1,r2,…,rM}
и семейство Ψ={S1,…,SN}
множеств Sj R.
Любое подсемейство Ψ’={Sj1,
Sj2…,Sjk}
семейства Ψ такое, что
R.
Любое подсемейство Ψ’={Sj1,
Sj2…,Sjk}
семейства Ψ такое, что
 (1)
(1)
называется покрытием множества R, а множества Sji называются покрывающими множествами. Если в дополнение к предыдущему соотношению Ψ’ удовлетворяет условию

т.е. множества Sji (i=1,…,k) попарно не пересекаются, то Ψ’ называется разбиением множества R. Для нашей задачи это означает, что защита от каждой потенциальной угрозы реализуется одним и только одним средством.
Если
каждому
 Ψ поставлена в соответствие положительная
стоимость cj,
то ЗНП формулируется так: найти покрытие
множества R,
имеющее наименьшую стоимость, причем
стоимость семейства Ψ’={Sj1,Sj2…,Sjk}
определяется как
Ψ поставлена в соответствие положительная
стоимость cj,
то ЗНП формулируется так: найти покрытие
множества R,
имеющее наименьшую стоимость, причем
стоимость семейства Ψ’={Sj1,Sj2…,Sjk}
определяется как
 .
Аналогично формулируется и задача о
наименьшем разбиении (ЗНР).
.
Аналогично формулируется и задача о
наименьшем разбиении (ЗНР).
В
матричной форме, когда строки (M N)-матрицы
[tij],
состоящей из нулей и единиц, покрываются
столбцами, ЗНП может быть сформулирована
как задача линейного программирования:
N)-матрицы
[tij],
состоящей из нулей и единиц, покрываются
столбцами, ЗНП может быть сформулирована
как задача линейного программирования:
минимизировать

при ограничениях

где


и

Для ЗНР неравенства (2) обращаются в равенства

Вследствие особой природы ЗНП часто удается сделать при её исследовании определенные, хорошо известные заранее выводы и упрощения.
Например:
1)
если для некоторого элемента ri то ri
покрыть нельзя и, следовательно, задача
не имеет решения;
то ri
покрыть нельзя и, следовательно, задача
не имеет решения;
2)
если
 ,
такое, что
,
такое, что
 и
и
 ,
то Sk
должно присутствовать во всех решениях
и задачу можно свести к «меньшей»,
положив
,
то Sk
должно присутствовать во всех решениях
и задачу можно свести к «меньшей»,
положив
 и
и
 ;
;
3)
пусть
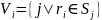 ;
тогда если
;
тогда если
 такие, что
такие, что
 ,
то rq
можно удалить из R,
поскольку любое множество, которое
покрывает rp,
должно также покрывать и rq,
т.е. rp
доминирует над rq;
,
то rq
можно удалить из R,
поскольку любое множество, которое
покрывает rp,
должно также покрывать и rq,
т.е. rp
доминирует над rq;
4)
если для некоторого семейства множеств
 справедливы соотношения
справедливы соотношения
 и
и
 для любых
для любых
 ,
то
,
то
 может быть вычеркнуто из Ψ, поскольку
может быть вычеркнуто из Ψ, поскольку
 доминирует над
.
доминирует над
.
Предположим, что все эти упрощения выполнены (если они возможны) и что исходная ЗНП уже переформулирована в соответствующую неприводимую форму.
Как уже отмечалось, ЗНР тесно связана с ЗНП, являясь по существу ЗНП с дополнительным (неперекрываемость) ограничением. Это ограничение удобно использовать при решении задачи методом, использующем древо поиска, т.к. при таком ограничении может рано выясниться, что некоторые возможные ветвления дерева рассматривать не надо. С учетом этого сначала рассмотрим алгоритм решения ЗНР, а затем используем этот алгоритм для решения ЗНП.
Сущность простых методов решения ЗНР, использующих дерево поиска, такова. Вначале строятся «блоки» столбцов, по одному на каждый элемент rk из R, т.е. всего M блоков. k-й блок состоит из таких множеств семейства Ψ (представленных столбцами), в которых содержится элемент rk, но отсутствуют элементы с меньшими индексами – r1,…,rk-1. Следовательно, каждое множество (столбец) появляется точно в одном определенном блоке и совокупность блоков может быть представлена в виде таблицы, как показано в таблице 1.
В
процессе работы алгоритма блоки
отыскиваются последовательно и
формирование k-го
блока начинается после того, как каждый
элемент ri,
 ,
будет покрыт частным решением. Таким
образом, если какое-то множество в блоке
k
содержит элементы с индексами, меньшими
k,
то оно должно быть отброшено (на этом
этапе) в соответствии с требованием
неперекрываемости.
,
будет покрыт частным решением. Таким
образом, если какое-то множество в блоке
k
содержит элементы с индексами, меньшими
k,
то оно должно быть отброшено (на этом
этапе) в соответствии с требованием
неперекрываемости.
Множества в пределах каждого блока размещаются в порядке возрастания их стоимостей и перенумеровываются так, что Sj теперь уже обозначает множество, соответствующее j-му столбцу таблицы 1.
Текущее
«наилучшее» решение
 со стоимостью
со стоимостью
 известно на любом этапе поиска (
обозначает семейство соответствующих
покрывающих множеств). Если B
и z
– соответствующее семейство и стоимость
на данной стадии поиска, а E
– множество, представляющее те элементы
(т.е. строки) ri,
которые покрываются множествами из B,
то один из простых алгоритмов, использующих
дерево поиска, можно описать следующим
образом.
известно на любом этапе поиска (
обозначает семейство соответствующих
покрывающих множеств). Если B
и z
– соответствующее семейство и стоимость
на данной стадии поиска, а E
– множество, представляющее те элементы
(т.е. строки) ri,
которые покрываются множествами из B,
то один из простых алгоритмов, использующих
дерево поиска, можно описать следующим
образом.
Присвоение начальных значений
Шаг
1. Построить исходную таблицу и начать
с частного решения:
 и
и
 .
.
Расширение
Шаг
2. Найти
 .
Над блоком p
поставить метку (над его первым множеством,
которое, как следует из построения
таблицы, имеет наименьшую стоимость).
.
Над блоком p
поставить метку (над его первым множеством,
которое, как следует из построения
таблицы, имеет наименьшую стоимость).
Таблица 1
|
Блок 1 |
Блок 2 |
Блок 3 |
Блок 4 |
|
r1 |
1…1 |
0 |
|
|
|
|
|
1…1 |
0 |
|
|
r3 |
|
|
1…1 |
0 |
|
r4 |
0 или 1 |
|
|
1…1 |
|
. |
|
0 или 1 |
0 или 1 |
|
|
. |
|
|
|
0 или 1 |
|
rm |
|
|
|
|
и.т.д. |
Шаг
3. Начиная с отмеченной позиции в блоке
p,
перебирать его множества
 ,
скажем, в порядке возрастания индекса
j.
,
скажем, в порядке возрастания индекса
j.
1)
Если найдено множество
,
такое, что
 и
и
 (где
(где
 – стоимость множества
),
то перейти к шагу 5.
– стоимость множества
),
то перейти к шагу 5.
2)
В противном случае, т. е. если блок p
исчерпан или выбрано множество
,
такое, что
 ,
перейти к шагу 4.
,
перейти к шагу 4.
Шаг возвращения
Шаг
4. B
не может привести к лучшему решению.
Если
 (т.е. блок 1 исчерпан), то алгоритм
заканчивает работу и оптимальным
решением является
.
В противном случае удалить последнее
множество, скажем,
(т.е. блок 1 исчерпан), то алгоритм
заканчивает работу и оптимальным
решением является
.
В противном случае удалить последнее
множество, скажем,
 ,
добавить его в B,
положить
,
добавить его в B,
положить
 ,
поставить метку над множеством
,
поставить метку над множеством
 ,
удалить предшествующую метку в блоке
l
и перейти к шагу 3.
,
удалить предшествующую метку в блоке
l
и перейти к шагу 3.
Проверка нового решения
Шаг
5. Обновить данные:
 .
Если найдено лучшее решение
.
Если найдено лучшее решение
 ,
то положить
,
то положить
 ,
,
 и перейти к шагу 2.
и перейти к шагу 2.
Если
поиск оканчивается с исчерпыванием
блока 1 (см. выше шаг 4), то целесообразно
переставить блоки в порядке возрастания
числа столбцов (множеств) в каждом блоке.
Это может быть осуществлено (перед
построением исходной таблицы)
перенумерацией элементов (строк)
 в порядке увеличения числа множеств
из S,
содержащих соответствующие элементы.
в порядке увеличения числа множеств
из S,
содержащих соответствующие элементы.
В алгоритме, описанном выше, единственным шагом, характерным для ЗНР, является шаг 3-1. Если удалить в этом шаге требование неперекрываемости (т.е. необязательно, чтобы защита от угрозы реализовывалась только одним средством), то алгоритм может быть использован для ЗНП. Однако в этом случае исходная таблица будет отличаться от таблицы 1.
Положим
Sj={rj1,rj2,…},
где
 …
. Теперь недостаточно включить Sj
только в блок
…
. Теперь недостаточно включить Sj
только в блок
 ,
поскольку без требования неперекрываемости
нельзя исключить Sj
из рассмотрения, например, в блоке
,
поскольку без требования неперекрываемости
нельзя исключить Sj
из рассмотрения, например, в блоке
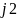 ,
если rj1
уже покрыто частным решением. Следовательно,
Sj
должно входить в каждый блок
,
если rj1
уже покрыто частным решением. Следовательно,
Sj
должно входить в каждый блок
 …
. С другой стороны, поскольку элемент
…
. С другой стороны, поскольку элемент
 из Sj
согласно тому, что поиск осуществляется
последовательно, покрывается перед
ветвлением на множествах блока β (
из Sj
согласно тому, что поиск осуществляется
последовательно, покрывается перед
ветвлением на множествах блока β ( ),
то теперь возможно удалить все элементы
xjα
из Sj
перед введением Sj
в
любой блок
без какого-либо влияния на результат
решения задачи. Эта тривиальная операция
удаления с вычислительной точки зрения
оказывается очень выгодной, поскольку
исходная таблица в ЗНП теперь может
быть сокращена с помощью описанных выше
правил, до значительно меньших размеров.
),
то теперь возможно удалить все элементы
xjα
из Sj
перед введением Sj
в
любой блок
без какого-либо влияния на результат
решения задачи. Эта тривиальная операция
удаления с вычислительной точки зрения
оказывается очень выгодной, поскольку
исходная таблица в ЗНП теперь может
быть сокращена с помощью описанных выше
правил, до значительно меньших размеров.
Рассмотрим некоторые важные условия и вычисление нижних границ, которые могут быть использованы для ограничения дерева поиска и улучшения эффективности основного алгоритма.
Рассмотрим
случай, когда блок 1 содержит (среди
других) множества
 и
и
 со стоимостями 3 и 4 соответственно, а
блок 2 содержит множества
со стоимостями 3 и 4 соответственно, а
блок 2 содержит множества
 и
и
 ,
каждое со стоимостью 2.
,
каждое со стоимостью 2.
В
процессе работы описанного алгоритма
на некотором этапе получим
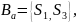
 ,
,
 ;
затем ветвление будет продолжаться до
тех пор, пока мы не найдем решение,
которое лучше, чем текущее
,
либо не установим, что S1
и S3
не могут одновременно появляться в
оптимальном решении.
;
затем ветвление будет продолжаться до
тех пор, пока мы не найдем решение,
которое лучше, чем текущее
,
либо не установим, что S1
и S3
не могут одновременно появляться в
оптимальном решении.
Далее, через много шагов, мы достигаем такой ситуации, когда
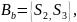
 ,
,
Здесь
становится ясным, что дальнейшее
ветвление делать не нужно, поскольку
 и
и
 .
Подобная картина наблюдается и при
.
Подобная картина наблюдается и при
 ,
,
Таким
образом имеет смысл хранить для каждого
значения z=1,2,
…,
некоторый список максимальных множеств
E,
которые уже получены для данных z
(где под максимальным понимается такое
множество, которое не содержится в
другом множестве из этого списка). Эти
списки множеств E
путем элиминации тех ветвлений, которые
позже оказываются бесполезными. Пусть
мы сохранили некоторый список
 множеств E,
которые были получены в процессе
выполнения алгоритма на некотором
уровне с суммарной стоимостью
множеств E,
которые были получены в процессе
выполнения алгоритма на некотором
уровне с суммарной стоимостью
 .
Предположим, что на данном этапе
.
Предположим, что на данном этапе
 ,
,
 ,
,
 и мы заняты исследованием блока k
(где
и мы заняты исследованием блока k
(где
 - см. шаг 2 алгоритма) и выбором множества
- см. шаг 2 алгоритма) и выбором множества
 со стоимостью
со стоимостью
 для следующего ветвления. Если
для следующего ветвления. Если
 ,
то ветвление в рассматриваемом алгоритме
с этого этапа продолжается дальше и
,
то ветвление в рассматриваемом алгоритме
с этого этапа продолжается дальше и
 ,
,
 ,
,
 ,
,
независимо от каких-либо других соображений.
Однако можно гарантировать (на шаге 3), что перед продолжением ветвления
 ,
,
 и при всех
,
для которых
и при всех
,
для которых
 .
(4)
.
(4)
Если
не удовлетворяет приведенному выше
условию, то оно отбрасывается и
рассматривается следующее множество
 блока k,
и т.д. Если
удовлетворяет условию (4), то можно
продолжать ветвление дальше с
так же, как и раньше, но с обновленным
списком
блока k,
и т.д. Если
удовлетворяет условию (4), то можно
продолжать ветвление дальше с
так же, как и раньше, но с обновленным
списком
 ,
полученным добавлением
,
полученным добавлением
 в
в
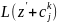 .
.
Поскольку невозможно практически хранить полные списки , то должны быть использованы некоторые эвристические критерии для определения размеров этих списков и способов их обновления в процессе поиска.
На
некотором этапе поиска, определяемом
 и когда блок k
является следующим блоком, подлежащим
рассмотрению, нижняя граница h
для наименьшего значения величины z
может быть вычислена и использована
для ограничения дерева поиска следующим
образом.
и когда блок k
является следующим блоком, подлежащим
рассмотрению, нижняя граница h
для наименьшего значения величины z
может быть вычислена и использована
для ограничения дерева поиска следующим
образом.
Рассмотрим
некоторый элемент
 ,
который отсутствует в множествах блоков
,
который отсутствует в множествах блоков
 ,
соответствующих элементам, еще не
покрытых частным решением. Тогда элемент
ri
не может быть покрыт, пока некоторое
множество
,
соответствующих элементам, еще не
покрытых частным решением. Тогда элемент
ri
не может быть покрыт, пока некоторое
множество
 блока i
не выбрано для добавления к B’
на следующем этапе. Итак, для каждого
такого элемента
блока i
не выбрано для добавления к B’
на следующем этапе. Итак, для каждого
такого элемента
 строится строка для матрицы
строится строка для матрицы
 и строка для второй матрицы
и строка для второй матрицы
 ,
где
,
где
 равно числу элементов в множестве
равно числу элементов в множестве
 ,
а
,
а
 - стоимость множества
.
- стоимость множества
.
Кроме
того, к каждой матрице
 и
и
 добавляется дополнительная строка,
скажем
добавляется дополнительная строка,
скажем
 ,
с
,
с
 для всех
для всех
 ,
,
 и
и

где
минимумом берется по всем множествам
таким, что
 .
Число элементов в строке
.
Число элементов в строке
 матрицы
(или
)
может быть отлично от числа элементов
в другой строке
матрицы
(или
)
может быть отлично от числа элементов
в другой строке
 .
Поэтому, добавив в конце строк 0 (нули)
и
.
Поэтому, добавив в конце строк 0 (нули)
и
 (бесконечности) соответственно для
матриц
и
,
добьемся того, чтобы число элементов в
разных строках стало одинаковым (например
(бесконечности) соответственно для
матриц
и
,
добьемся того, чтобы число элементов в
разных строках стало одинаковым (например
 ),
а матрицы стали прямоугольными.
),
а матрицы стали прямоугольными.
Теперь выскажем ряд утверждений. Поскольку оптимальное решение текущей подзадачи должно покрывать элементов, то, выбирая по одному значению из каждой строки матрицы с таким расчётом, чтобы удовлетворялось условие

и минимизировалась соответствующая стоимость
 ,
,
мы
как раз и получим нижнюю границу для
оптимальной стоимости в подзадаче –
границей является найденное значение
 .
Здесь мы предполагали, что множества,
соответствующие элементам матрицы D,
расположенным в разных строках, не
пересекаются; такая ситуация является
наилучшей из возможных, т.к. реализация
защиты от определенной угрозы
осуществляется одним средством.
Последняя строка
просто гарантирует, что если
.
Здесь мы предполагали, что множества,
соответствующие элементам матрицы D,
расположенным в разных строках, не
пересекаются; такая ситуация является
наилучшей из возможных, т.к. реализация
защиты от определенной угрозы
осуществляется одним средством.
Последняя строка
просто гарантирует, что если

то оставшиеся элементы покрываются наилучшим образом, т.е. с минимальной стоимостью покрытия для каждого дополнительно покрываемого элемента.
Наименьшее
значение для
 при ограничении
при ограничении
легко может быть получено с помощью следующего алгоритма динамического программирования.
Пусть
 – наибольшее число элементов, которые
могут быть покрыты только с помощью
первых
– наибольшее число элементов, которые
могут быть покрыты только с помощью
первых
 строк матрицы D
(т.е. с использованием только
блоков задачи), причем общая стоимость
покрытия не превышает
.
Тогда
может быть найдено итерационным методом,
так как
строк матрицы D
(т.е. с использованием только
блоков задачи), причем общая стоимость
покрытия не превышает
.
Тогда
может быть найдено итерационным методом,
так как


где
 придается начальное значение, равное
0 для всех v.
придается начальное значение, равное
0 для всех v.
Следовательно,
наименьшее из значений величины v,
для которых выполняется неравенство
 ,
как раз будет требуемой нижней границей
h;
оно может быть легко получено из таблицы
решения задачи динамического
программирования, составленной с
использованием приведенного выше
итерационного уравнения. Следует
отметить, что необходимо рассмотреть
только такие значения величины v.
для которых
,
как раз будет требуемой нижней границей
h;
оно может быть легко получено из таблицы
решения задачи динамического
программирования, составленной с
использованием приведенного выше
итерационного уравнения. Следует
отметить, что необходимо рассмотреть
только такие значения величины v.
для которых
 ,
поскольку если
,
поскольку если
 (т.е.
(т.е.
 для
для
 ,
то можно сразу же сделать шаг возвращения.
,
то можно сразу же сделать шаг возвращения.
Таким образом, предложенный способ формирования оптимальной структуры разрабатываемой СЗИ НСД позволяет реализовать СЗИ НСД, перекрывающую все возможные угрозы НСД, с наименьшими ресурсными затратами, если под «стоимостью» в алгоритме подразумевать задействие вычислительных ресурсов защищаемой системы, которые тем самым отвлекаются от выполнения задачи по прямому назначению.
Литература
1. Оптимальный синтез и анализ эффективности комплексов средств защиты информации: Монография / В.Г. Кулаков, В.Г. Кобяшев, А.Б. Андреев, А.Л. Линец, Ю.Е. Дидюк, О.Ю. Макаров, Е.А. Рогозин, Г.А. Остапенко, В.И. Белоножкин Воронеж: Воронеж. гос. техн. ун-т, 2004. - 181 с.
2. Майника Э., Алгоритмы оптимизации на сетях и графах – М.: Мир, 1981 – 324с.
3. Харари Ф., Теория графов – М.: Мир,1973 – 402 с
4. Кристофайдес Н., Теория графов. Алгоритмический подход – М.: Мир, 1978 – 429 с.
Воронежский государственный технический университет
УДК 681.3
С.В. Белокуров, А.А. Змеев, В.А. Хвостов, Р.А. Родин
Нормирование требований к основным элементам автоматизированной СИСТЕМЫ Информационной безопасности
В статье проанализированы структура и основные требования к основным элементам автоматизированной системы информационной безопасности
Поскольку
уровень автоматизированной системы
информационной безопасности (АС ИБ)
системы определяется уровнями ИБ ее
элементов [1], то возникает необходимость
рационального распределения заданных
требований по ИБ системы между ее
элементами. Первым шагом на пути решения
поставленной задачи является Анализ
функциональных схем АС и определение
ее основных элементов с таким расчетом,
чтобы соответствующий показатель уровня
безопасности SOF системы определялся по
формуле
 ,
где
,
где
 - показатель уровня безопасности i – го
основного элемента АС; N — количество
основных элементов, в системе.
- показатель уровня безопасности i – го
основного элемента АС; N — количество
основных элементов, в системе.
Система удовлетворяет требованиям по ИБ, если для каждого основного показателя уровня ИБ выполняется условие:
 ;
(1)
;
(1)
где
— действительное значение показателя
уровня ИБ АС;
 —
требуемое значение этого же показателя.
—
требуемое значение этого же показателя.
Неравенство (1) может быть выполнено при различных комбинациях уровня ИБ основных элементов, которые достигаются при различных затратах средств и времени. Задача нормирования требований к уровням ИБ состоит в том, чтобы выбрать такую комбинацию уровней ИБ основных элементов, при которых выполняется неравенство (1) и достигается минимум экономических затрат на обеспечение требуемого уровня ИБ проектируемой АС.
Для
решения рассматриваемой задачи введем
в рассмотрение функцию экономических
затрат для каждого основного элемента
 .
В отношении функции
могут быть выдвинуты следующие допущения.
.
В отношении функции
могут быть выдвинуты следующие допущения.
При фиксированном начальном значении уровня ИБ i-го элемента функция является неубывающей дифференцируемой функцией, удовлетворяющей условию:
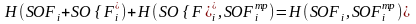 ,
,
при
всех
 .
Численные значения функции удовлетворяют
условиям:
.
Численные значения функции удовлетворяют
условиям:
 .
.
Суммарные экономические затраты на разработку системы удовлетворяют равенству:
 .
(2)
.
(2)
При
сделанных выше допущениях задача
определения оптимальных требований по
ИБ к элементам системы сводится к
минимизации функции (2) при дополнительном
ограничении: .
.
Для решения поставленной задачи может быть использован метод неопределенных множителей Лагранжа, применение которого приводит к следующей системе уравнений:
 ,
,
 ,
,
 ,
,
где
 - неопределенный множитель Лагранжа;
- неопределенный множитель Лагранжа;  .
.
Аппроксимировав
функцию
на отрезке
 прямой
линией, получаем:
прямой
линией, получаем: ,
,
где
 — коэффициент, определяемый по формуле:
— коэффициент, определяемый по формуле:
 .
.
Коэффициенты
 линейной аппроксимации
могут быть определены на основе опыта
разработки аналогичных элементов
существующих систем.
линейной аппроксимации
могут быть определены на основе опыта
разработки аналогичных элементов
существующих систем.
Литература
1. Основы информационной безопасности: Учебник для высших учебных заведений МВД России / Под ред. В.А. Минаева и С.В. Скрыля. - Воронеж: Воронежский институт МВД России, 2001. – 464 c.
Воронежский институт МВД России
Военная академия ВКО имени Г.К. Жукова
Воронежский государственный технический университет
УДК 681.3
С.В. Белокуров, А.А. Змеев, В.А. Хвостов, Р.А. Родин
Алгоритм нормирования требований к информационной безопасности автоматизированной системы
В статье приведен алгоритм нормирования требований к информационной безопасности автоматизированной системы при заданной эффективности по прямому назначению.
Представим алгоритм нормирования требований к информационной безопасности автоматизированной системы при заданной эффективности по прямому назначению (рис. 1).
Алгоритм
реализует методику задания требований
к показателю
![]() - параметр потока событий связанный с
реализаций угроз нарушения информационной
безопасности (ИБ), а именно оперативное
время работы автоматизированной системы
(АС) в условиях отсутствия реализаций
угроз от несанкционированного доступа
(НСД), основанную на методе графического
решения трансцендентного уравнения,
разработанного в [1-3].
- параметр потока событий связанный с
реализаций угроз нарушения информационной
безопасности (ИБ), а именно оперативное
время работы автоматизированной системы
(АС) в условиях отсутствия реализаций
угроз от несанкционированного доступа
(НСД), основанную на методе графического
решения трансцендентного уравнения,
разработанного в [1-3].
Вычисления,
реализуемые при выборе требуемого
уровня надежности ПСЗИ, реализуются в
блоках 1-4 алгоритма. Исходными данными
алгоритма являются заданная вероятность
решения функциональной задачи ( )
и среднее время решения (длительность
рабочей смены) (
)
и среднее время решения (длительность
рабочей смены) ( ).
).
Блок 1 является подготовительным. В блоке формируются исходные данные для проведения расчетов. На основе анализ технической документации конкретной АС выявляются основные функциональные задачи системы и их временная сложность. Также анализируются принятые в организации политика безопасности и данные об устраненных ранее попытках нарушения информационной безопасности. Выходными данными первого блока являются значения идеальной эффективности и среднее время восстановления после реализации угроз НСД.
В блоке 3 осуществляется решение трансцендентного уравнения.

Рис. 1. Алгоритм нормирования требований к информационной безопасности автоматизированной системы при заданной эффективности по прямому назначению
Выходным
значением алгоритма является значение
требований к параметру потока событий
связанный с реализаций угроз нарушения
ИБ (оперативного времени работы АС в
условиях отсутствия реализаций угроз
НСД) (![]() ).
).
Литература
1. Основы информационной безопасности: Учебник для высших учебных заведений МВД России / Под ред. В.А. Минаева и С.В. Скрыля. - Воронеж: Воронежский институт МВД России, 2001. – 464 c.
2. Рогозин Е.А. Методы и средства анализа эффективности при проектировании программных средств защиты информации / Е.А. Рогозин, О.Ю. Макаров, А.В. Муратов и др. // Монография. – Воронеж: Воронеж. гос. техн. ун-т, 2002. – 125 с.
3. Рогозин Е.А. Методы и средства автоматизированного управления подсистемой контроля целостности в системах защиты информации / Е.А. Рогозин, О.Ю. Макаров, В.И. Сумин и др. // Монография. – Воронеж: Воронеж. гос. техн. ун-т, 2003. – 165 с.
Воронежский институт МВД России
Военная академия ВКО имени Г.К. Жукова
Воронежский государственный технический университет
УДК 681.3
С.В. Белокуров, А.А. Змеев, В.А. Хвостов, Р.А. Родин
МЕТОДИКА ТЕСТИРОВАНИЯ РАБОЧЕЙ СРЕДЫ аВТОМАТИЗИРОВАННЫХ СИСТЕМ УПРАВЛЕНИЯ КРИТИЧЕСКОГО ПРИМЕНЕНИЯ
В статье предлагается методика оперативного управления тестированием в автоматизированных системах управления критического применения.
Для защиты информации (ЗИ) от несанкционированного доступа в автоматизированных системах управления критического применения (АСК) широко применяются программные системы защиты информации (ПСЗИ). Входящие в них средства тестирования позволяют администратору ЗИ проводить запуском главной тестовой программы периодическое тестирование рабочей среды АСК на предмет сравнения текущего состояния с эталонным. Традиционно управление тестированием имеет организационный характер. Стремление сократить частоту контрольных проверок и связанные с ними временные затраты, с одной стороны, и требование обеспечить своевременное обнаружение нарушения целостности, с другой, вызывает необходимость оптимизации тестирования [1-3].
Предлагается способ оперативного управления тестированием на базе автоматизации запуска главной тестовой программы. Он основывается на комплексной оценке качества функционирования ПСЗИ как объекта управления посредством системы показателей. Для оценки исходов альтернатив управленческого решения используется векторный критерий. Его компонентами являются частные показатели: статические (функциональность, ресурсная агрессивность функционирования, функциональная агрессивность функционирования, удобство использования) и динамические (адекватность функционирования, временная агрессивность функционирования). Последние характеризуются тем, что для их анализа используется математическая модель динамики функционирования ПСЗИ в АСК. Статические показатели считаются булевозначными, где 1 – допустимое качество функционирования ПСЗИ, а 0 – недопустимое. Динамические показатели считаются неотрицательными, их возрастание интерпретируется как улучшение качества функционирования ПСЗИ.
Задача принятия решения при управлении тестированием формализуется как задача математического программирования: требуется выбрать такую альтернативу, чтобы максимизировать показатель адекватности функционирования ПСЗИ при обеспечении значения показателя временной агрессивности функционирования ПСЗИ не ниже заданного и единичного значения всех статических показателей. Ограничение по показателю функциональности накладывается только на параметры, задающие эталонное состояние рабочей среды (контролируемые параметры). Оно удовлетворяется тогда и только тогда, когда объем контролируемых параметров обеспечивает достаточную полноту контроля целостности рабочей среды. А именно, периодическому контролю на целостность должна подвергаться вся конфиденциальная и системная информация. Ограничение по другим статическим показателям накладывается на параметры, задающие временную последовательность проведения контрольных проверок. Оно удовлетворяется тогда и только тогда, когда расписание проведения контрольных проверок удовлетворяет порядку, установленному эксплуатационной документацией на АСК (контрольные проверки могут начинаться только в ситуациях, предполагающих такую возможность).
При выполнении ограничений по статическим показателям исходная задача решается относительно единственного управляемого параметра, задающего временную последовательность контрольных проверок, – вероятности проведения проверки в ситуации, предполагающей такую возможность. Решение о проведении проверки в такой ситуации принимается по данной вероятности вбрасыванием датчика случайных чисел. Это обеспечивает неизвестность для злоумышленника времени начала очередной проверки. Динамические показатели оцениваются методом [1]: адекватность функционирования ПСЗИ, характеризующая своевременность проведения контрольных проверок, и временная агрессивность функционирования ПСЗИ, характеризующая своевременность реализации ПСЗИ защитных функций.
Литература
1. Основы информационной безопасности: Учебник для высших учебных заведений МВД России / Под ред. В.А. Минаева и С.В. Скрыля. - Воронеж: Воронежский институт МВД России, 2001. – 464 c.
2. Рогозин Е.А. Методы и средства анализа эффективности при проектировании программных средств защиты информации / Е.А. Рогозин, О.Ю. Макаров, А.В. Муратов и др. // Монография. – Воронеж: Воронеж. гос. техн. ун-т, 2002. – 125 с.
3. Рогозин Е.А. Методы и средства автоматизированного управления подсистемой контроля целостности в системах защиты информации / Е.А. Рогозин, О.Ю. Макаров, В.И. Сумин и др. // Монография. – Воронеж: Воронеж. гос. техн. ун-т, 2003. – 165 с.
Воронежский институт МВД России
Военная академия ВКО имени Г.К. Жукова
Воронежский государственный технический университет
УДК 681.3
А.А. Змеев
АЛГОРИТМ АУТЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЕЙ АВТОМАТИЗИРОВАННЫХ СИСТЕМ ЗАЩИТЫ ИНФОРМАЦИИ
В статье предлагается алгоритм идентификации и аутентификации пользователей автоматизированных систем, реализуемой модифицированной системой зашиты информации.
В многопользовательских автоматизированных системах (АС), с широкой номенклатурой пользователей и различными полномочиями по доступу к информации АС, целесообразно использовать многоуровневый алгоритм идентификации и аутентификации пользователей, основу которого составит типовой алгоритм [1].
Предлагается дополнить вышеуказанный типовой алгоритм процедурой подтверждения подлинности пользователя, которую целесообразно проводить в случайно выбранные дискретные моменты времени, во время его работы в системе и без его ведома. Данная процедура осуществляет мониторинговый контроль (МК) уже после предоставления пользователю доступа в систему и блокирует АС, если за терминалом начал работать не тот человек, которому доступ был предоставлен первоначально (см. рисунок). МК пользователя возможен при использовании встроенных оптических сканеров отпечатков пальцев, систем распознавания клавиатурного почерка и др. [2,3]. Актуальна задача МК физического состояния пользователя, т.к. под воздействием психотропных средств и в других случаях, он может оказать управляющее воздействие на АС приводящее к потерям (иногда невосполнимым). Эти состояния человека могут характеризоваться изменениями его биометрических параметров (пульс, баллистокардиограмма и др.), которые могут фиксироваться и использоваться для аутентификации пользователя [2].
При наличии в АС особо важного информационного ресурса (ресурса 0), целесообразно процедуры идентификации и аутентификации дополнить процедурой дополнительной аутентификации пользователей. Для этого предлагается использовать метод разделенных привилегий [1].

Рис. 1. Алгоритм идентификации и аутентификации пользователей АС, реализуемой модифицированной СЗИ
Таким образом разработан многоуровневый алгоритм идентификации и аутентификации пользователей, реализуемый модифицированной системой защиты информации (СЗИ) при их доступе к конфиденциальной информации АС (рис. 1).
Литература
1. Основы информационной безопасности: Учебник для высших учебных заведений МВД России / Под ред. В.А. Минаева и С.В. Скрыля. - Воронеж: Воронежский институт МВД России, 2001. – 464 c.
2. Рогозин Е.А. Методы и средства анализа эффективности при проектировании программных средств защиты информации / Е.А. Рогозин, О.Ю. Макаров, А.В. Муратов и др. // Монография. – Воронеж: Воронеж. гос. техн. ун-т, 2002. – 125 с.
3. Рогозин Е.А. Методы и средства автоматизированного управления подсистемой контроля целостности в системах защиты информации / Е.А. Рогозин, О.Ю. Макаров, В.И. Сумин и др. // Монография. – Воронеж: Воронеж. гос. техн. ун-т, 2003. – 165 с.
Военная академия ВКО имени Г.К. Жукова
УДК 681.3
А.А. Змеев
ФОРМАЛИЗАЦИЯ КРИТЕРИЕВ ДЛЯ ПОСТРОЕНИЯ СИСТЕМ ЗАЩИТЫ ИНФОРМАЦИИ ОТ НЕСАНКЦИОНИРОВАННОГО ДОСТУПА
Рассматривается методический подход построения системы автоматизированного проектирования программных систем защиты информации с использованием структуры требований ГОСТ Р ИСО/МЭК 15408-2002
В многопользовательских автоматизированных системах (АС), с широкой номенклатурой пользователей и различными полномочиями по доступу к информации АС, целесообразно использовать многоуровневый алгоритм идентификации и аутентификации пользователей, основу которого составит типовой алгоритм [1]. В современном мире процессы автоматизации управления, компьютеризации, расширения использования Internet предъявляют всё новые требования к системам защиты информации от несанкционированного доступа (СЗИ НСД). Для автоматизации процесса разработки СЗИ НСД, то есть для построения соответствующей системы автоматизированного проектирования (САПР) желательно иметь набор программных и программно-технических блоков (либо достаточно подробное их описание), каталог формализованных требований, а также методики и критерии оценки качества СЗИ НСД.
Для формализации требований к проектируемой системе может быть использован ГОСТ Р ИСО/МЭК 15408 «Информационная технология. Методы и средства обеспечения безопасности. Критерии оценки безопасности информационных технологий»[1], который содержит полный аутентичный текст международного стандарта ISO/IEC 15408 [2], называемого также «Общие критерии» (Common Criteria). Авторы этого, разработанного в 1999 году, документа — специалисты из шести стран (США, Канады, Великобритании, Германии, Нидерландов и Франции) и рабочей группы WG 3 «Критерии оценки безопасности» объединенного технического комитета JTC1 «Информационные технологии» ISO/IEC. Принятый в России стандарт является частью предполагаемой к принятию совокупности документов, призванной заменить разработанный в начале 90-х комплекс руководящих документов Гостехкомиссии в сфере защиты информации.
Стандарт содержит каталог функциональных требований и требований доверия, которые могут быть предъявлены к объекту информационных технологий, но не регламентирует их обязательное применение. Требования безопасности объекта оценки (ОО), в частности к СЗИ НСД, определяются исходя из целей безопасности, на основе анализа назначения и условий использования ОО и излагаются в профиле защиты (ПЗ) или в задании по безопасности (ЗБ).
Идеология «Общих критериев» предполагает принятие и использование ряда нормативных документов, содержащих сформулированные на основе данного стандарта ПЗ, которые собственно и задавали бы требования безопасности к объектам ИТ. Требования в стандарте объединены в классы, семейства и компоненты. Каждый класс имеет несколько семейств. Семейства содержат один или несколько компонентов. Компоненты содержат отдельные элементы. При этом в ПЗ, ЗБ или ОУД (для требований доверия) включаются только компоненты целиком со всеми элементами.
В стандарте используется уникальная система краткого наименования. Например, имя FDP_IFF.4.2 читается следующим образом: функциональный класс (F) «Защита данных пользователя» (DP), семейство «Функции управления информационными потоками» (IFF), четвёртый компонент «Частичное устранение неразрешённых информационных потоков» (4), второй элемент компонента (2).
Компоненты могут зависеть от других компонентов. Для требований доверия компоненты внутри семейств имеют строгую иерархическую зависимость, как на рис. 1 Здесь AVA_CCA это анализ скрытых каналов класса требований доверия, AVA оценка уязвимостей. То есть внутри семейства компонент с большим номером предъявляет более жёсткие требования, чем компонент с меньшим номером.

Рис. 1. Иерархия компонентов семейства.
Для компонентов функциональных требований иерархия внутри семейств имеет более сложную «древовидную» структуру, которая в стандарте указана для каждого семейства, как, например, на рис. 2. Здесь FAU_SAA это анализ аудита безопасности функционального класса, а FAU аудит безопасности.
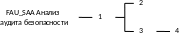
Рис. 2. Иерархия компонентов семейства.
Иерархическое разветвление внутри функционального семейства означает, что для достижения более высокого иерархического уровня (то есть более жёстких требований, чем в компоненте, являющемся корнем разветвления) необходимо реализовать требования компонентов из каждой ветви разветвления.
Помимо этого компоненты могут зависеть и от компонентов других семейств и классов. При этом зависимый компонент для осуществления своих функций нуждается в реализации функций компонента, от которого он зависит. Классификационная структура требований стандарта, обобщающая опыт ведущих специалистов в области информационной безопасности, может значительно облегчить основные этапы построения СЗИ НСД, среди которых анализ архитектуры компьютерной системы, выявление уязвимых элементов, анализ и классификация возможных угроз информации, оценка текущего уровня информационной безопасности, разработка политики безопасности, формирование перечня детальных требований и непосредственная разработка с учётом всех требований и влияющих факторов [3].
В САПР СЗИ НСД требования «Общих критериев» могут содержаться в базе данных, структура которой должна соответствовать структуре стандарта с учётом иерархии и зависимостей компонентов. Эти сведения могут быть использованы для формулировки требований к проектируемой СЗИ НСД в виде ПЗ или ЗБ после анализа исходных данных. Оценка проектируемой системы, заключающаяся в проверке целостности и непротиворечивости совокупности реализованных функций безопасности в смысле соответствия их структуре требований стандарта, может быть использована в задаче принятия решений структурного синтеза СЗИ НСД [4]. В качестве различных вариантов могут выступать как ранее разработанные СЗИ НСД, так и отдельные программные и программно-технические блоки, сведения о которых имеются у САПР.
Литература
1. ГОСТ Р ИСО/МЭК 15408-2002 Информационная технология. Методы и средства обеспечения безопасности. Критерии оценки безопасности информационных технологий. – Москва: ГОССТАНДАРТ. – 2002.
2. Основы информационной безопасности: Учебник для высших учебных заведений МВД России / Под ред. В.А. Минаева и С.В. Скрыля. - Воронеж: Воронежский институт МВД России, 2001. – 464 c.
3. Рогозин Е.А. Методы и средства анализа эффективности при проектировании программных средств защиты информации / Е.А. Рогозин, О.Ю. Макаров, А.В. Муратов и др. // Монография. – Воронеж: Воронеж. гос. техн. ун-т, 2002. – 125 с.
4. Рогозин Е.А. Методы и средства автоматизированного управления подсистемой контроля целостности в системах защиты информации / Е.А. Рогозин, О.Ю. Макаров, В.И. Сумин и др. // Монография. – Воронеж: Воронеж. гос. техн. ун-т, 2003. – 165 с.
Военная академия ВКО имени Г.К. Жукова
Рис.4.
Принципиальная электрическая схема УЛТ

УДК 681.3
М.В Попова, А.И. Мушта
МОДЕЛИРОВАНИЕ ЦИФРОВОГО УСТРОЙСТВА НА RTL УРОВНЕ
Представлен и реализован на примере полного сумматора алгоритм работы с программой моделирования цифровых устройств на базе RTL описания.
Постановка задачи
В настоящее время разработка цифровых схем для 3D изделий осуществляется согласно методологии логического синтеза. Одним из этапов проектирования схем является написание и отладкам RTL кода. САПР Cadence имеет в своем составе приложение Verilog-NC, использующееся для моделирования как на RTL-, так и на вентильном уровне.
Реализация задачи
Настройка рабочей среды NCLaunch.
Приложение Verilog-NC запускается командой «nclaunch» в терминальном окне, открытом из рабочего каталога. В результате выполнения команды откроется окно, показанное на рис.1.

Рис. 1. Приложение NCLaunch
В левой части окна расположены все рабочие каталоги, содержащие исходный RTL код, а также тестовое окружение (testbench). Правая часть окна содержит все рабочие директории, в том числе текущую worklib, иконка папки которой представлена в виде строительной каски желтого цвета. В самом низу списка директорий расположена папка рабочих сеансов. В нижней части окна NCLaunch отображаются выполняемые команды и процессы в текстовом виде, а также статусная информация выполненных процессов [1].
Для
открытия и редактирования файла
необходимо выбрать нужный файл и нажать
кнопку Edit
the
currently
selected
file
(редактирование выбранного файла)![]()
После
работы с файлом, его необходимо
скомпилировать. Это можно сделать либо
два раза кликнув на него, либо нажать
кнопку Launch
Verilog
Compiler
with
current
selection
(запуск компилятора с данным выбором)
![]() .
.
Скомпилированные файлы появятся в рабочей папке worklib. Если в процессе компиляции будут появляться ошибки, они будут отображаться в нижней части окна NCLaunc.
После успешного выполнения компиляции всех требуемых файлов перед началом моделирования требуется создать нетлист общей схемы в формате базы данных приложения NCLaunch. Для этого необходимо выполнить команду из меню «Tools/Elaborator» окна NCLaucnh. При этом на экран будет выведено окно, показанное на рис. 2.

Рис. 2. Окно Elaborate приложения NCLaunch
В верхней строке Design Unit необходимо задать название головного модуля среды окружения. Обычно головным модулем является testbench-файл. После нажатия на клавишу «OK» или «Apply» будет сформирован рабочий сеанс, т.е. собрана схема на основе скомпилированных ранее файлов. Статус процесса формирования отображается в нижней части окна. В случае обнаружения ошибок данные о месте и статусе ошибок будут отображены также в виде текстовой информации в нижней строке окна NCLaunch.
В случае нахождения ошибок необходимо исправить их, скомпилировать заново все файлы, подвергшиеся редактированию, и повторить создание рабочего сеанса.
После
того, как все файлы будут успешно
скомпилированы необходимо собрать базу
для последующего моделирования. Для
этого в директории worklib
необходимо найти самый верхний модуль
(testbench),
выбрать его и нажать на кнопку Launch
Elaborator
with
current
selection
(запуск выбранной разработки)![]() .
.
После
успешной сборки модели, появится
соответствующий пункт в категории
Snapshots
(снимки). Необходимо выбрать соответствующее
моделирование и нажать кнопку Launch
Simulator
with
current
selection
(запуск моделирования)![]()
Моделирование в приложении NCLaunch
Для начала моделирования по описанному алгоритму создадим файл с Verilog-кодом полного сумматора, который представлен на рис. 3.

Рис. 3. Verilog-код полного сумматора
Полный одноразрядный сумматор выполняет операцию арифметического сложения двух одноразрядных чисел A и B с учетом переноса из младшего разряда CY_IN-1. Он имеет три входа и два выхода [3]. Схема полного сумматора представлена на рис. 4.

Рис. 4. Схема полного сумматора
А – первое слагаемое;
В – второе слагаемое;
CY_IN-1 – перенос из младшего разряда;
CY_OUT – перенос в старший разряд;
Работа полного одноразрядного сумматора задается таблицей истинности:
Входы |
Выходы |
|||
A |
B |
CY_IN-1 |
Sum |
CY_OUT |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
Из таблицы истинности полного одноразрядного сумматора очевидно, что на выходе суммы Sum формируется единица, а на выходе переноса CY_OUT – нуль при наличии единицы на одном из входах A, B или CY_IN-1. При наличии единиц на любых двух из трех входов полного сумматора, на выходе Sum будет нуль, а на выходе CY_OUT – единица. При наличии на всех трех входах логических единиц, на обоих выходах сумматора присутствуют единицы. При нулях на всех трех входах выходы также принимают нулевые состояния.
После запуска моделирования откроется окно, представленное на рис. 5.

Рис. 5. Окно Design Browser приложения SimVision
В
левой части окна Design Browser отображается
проект в виде иерархически вложенных
папок, представляющих собой блоки схемы.
В правой части окна отображаются сигналы,
входящие в состав блока: входные,
выходные, внутренние. Выделив мышью
требуемые сигналы, необходимо нажать
клавишу
![]() .
При этом на экран будет выведено окно
симуляции Waveform приложения SimVision.
Выделенные сигналы будут добавлены в
список сигналов, расположенный в левой
части окна Waveform. Окно Waveform имеет ряд
функциональных клавиш, располагаемых
непосредственно под основным меню. Эти
клавиши необходимы для быстрого
выполнения основных, часто используемых
команд.
.
При этом на экран будет выведено окно
симуляции Waveform приложения SimVision.
Выделенные сигналы будут добавлены в
список сигналов, расположенный в левой
части окна Waveform. Окно Waveform имеет ряд
функциональных клавиш, располагаемых
непосредственно под основным меню. Эти
клавиши необходимы для быстрого
выполнения основных, часто используемых
команд.
На рис. 6 представлено окно Waveform с результатами моделирования в виде графиков.
Симуляция начинается непосредственно при нажатии на клавишу начала моделирования и останавливается в назначенное в тесте время или вручную при нажатии клавиши паузы. Во время симуляции на экран выводятся графики сигналов, которые могут быть представлены в виде отдельных сигналов или группы сигналов. Если график представлен в виде группы сигналов или шины, то способ выдачи информации на графике можно изменять. Доступны следующие виды выводимой информации: бинарный вид, десятичное представление, шеснадцатиричный вид, текстовая информация ASCII.

Рис. 6. Окно отображения результатов моделирования Waveform приложения Simvision
При
нажатии на кнопку
![]() ,
показывается выделенный сигнал на
электрической схеме. Схема приложения
Simvision изображена на рис. 7.
,
показывается выделенный сигнал на
электрической схеме. Схема приложения
Simvision изображена на рис. 7.

Рис. 7. Окно отображения результатов
моделирования Schematic Tracer приложения SimVision
Таким образом, после моделирования, можно сделать вывод, что RTL-модель полного сумматора описана верно, так как временные диаграммы соответствуют таблице истинности.
Заключение. Предложена последовательная настройка и работа со средой моделирования NCLaunch. С использованием языка Verilog реализована модель полного сумматора, представлена его работа.
Литература
1 Cadence. NCLaunch. User Guide. V 5.7, 2008.
2 Поляков А.К. Языки VHDL и VERILOG в проектировании цифровой аппаратуры. – М.: СОЛОН-Пресс, 2003. – 320 с.
3 Новожилов О.П. Основы цифровой техники. Учебное пособие. –М.: РадиоСофт, 2004, 526 с.
УДК 681.3
М.А. Цуканова, В.А. Кондусов
Измеритель амплитудно-частотных
характеристик на базе пк
Рассматривается устройство, предназначеное для измерения и наблюдения в режиме реального времени на экране компьютера АЧХ различных четырехполюсников на частотах от 50 кГц до 50 МГц.
Разработанное устройство предназначено для измерения и наблюдения в режиме реального времени на экране компьютера АЧХ различных четырехполюсников на частотах от 50 кГц до 50 МГц. Кроме того, прибор можно использовать как генератор сигналов [1].
Функциональная схема измерителя АЧХ показана на рисунке 1.
Прибор подключают к компьютеру через USB-разъем и включают специальную программу. Для измерения АЧХ четырехполюсника выбирают режим генератора качающейся частоты [1]. Сигнал от компьютера, преобразованный микросхемой FT245RL, поступает на микроконтроллер PIC16F72-P, который выдает значение частоты на цифровой синтезатор AD9850BRS в виде последовательного кода. Синтезатор в качестве опорной частоты использует частоту интегрального кварцевого генератора. Далее сигнал поступает на фильтр нижних частот (ФНЧ) с частотой среза 50МГц, а затем – на операционный усилитель AD8056. Напряжение 9В, сформированное DC/DC преобразователем MAU207, питает этот операционный усилитель. Усиленный сигнал поступает на вход исследуемого прибора. Выход исследуемого прибора подключают к блоку детекторов, в который входят линейный (AD8361) и логарифмический детектор (AD8310ARM). Выбор детектора осуществляется программно. Операционный усилитель LM358N служит для согласования уровней напряжений и выходного сопротивления детекторов со встроенным в микроконтроллер АЦП. На стабилитроне, транзисторе, двух резисторах и конденсаторе собран регулируемый источник опорного напряжения для АЦП. Полученный цифровой сигнал поступает через преобразователь интерфейса в компьютер, на экране которого выводится АЧХ прибора.
ПК

Микроконтроллер
PIC16F72-P
АЦП
Прямой цифровой синтезатор
AD9850BRS
Преобразователь
интерфейса FT245RL
Интегральный
кварцевый
генератор
Фильтр нижних
частот
Регулируемый источник опорного напряжения

С23
Операционный усилитель
AD8056
DC/DC
Преобразователь
MAU207

+5В
ИП

Линейный
детектор
AD8361ARM
Логарифмический
детектор
AD8310ARM

Операционный усилитель
AD8056




Рис. 1. Функциональная схема измерителя АЧХ
Как и любой генератор качающейся частоты, данный генератор выдает на выходе широкий спектр гармонических составляющих, поэтому появляется проблема электромагнитной совместимости. Исходя из анализа конструкторских решений подобных устройств, было решено экранировать узлы при помощи латуни. Измеритель АЧХ был выполнен в виде трех узлов: блока детекторов, микроконтроллерного блока и блока усилителя. Платы микроконтроллерного блока и усилителя двусторонние, изготавливаются из двусторонне фольгированного стеклотекстолита комбинированным позитивным методом. Платы ФНЧ и блока детекторов односторонние, метод изготовления – химический негативный. При сборке платы микроконтроллерного блока применяется двусторонний смешанный монтаж, для остальных плат – смешанно-разнесенный.
На рисунке 2 показана компоновка всех составных частей измерителя АЧХ внутри корпуса. Корпус алюминиевый, производства фирмы Takachi (модель UC13-4-18). На монтажной панели (1) расположены: плата микроконтроллерного блока (2), плата усилителя (3) и плата блока детекторов с экраном (4). Плата ФНЧ (5) смонтирована на плате усилителя и имеет свой экран. Также предусмотрен экран в виде перегородки (6). В ней установлен проходной конденсатор (7), через который подается питание на блок усилителя. Также на рисунке 2 видны два коаксиальных разъема (8) для подключения исследуемого прибора, разъем +5В для питания дополнительно подключаемых устройств (9), светодиод (10), который служит для индикации подключения измерителя АЧХ к ПК и USB-B разъем (11), смонтированный на плате микроконтроллерного блока.

Рис. 2. Измеритель АЧХ в сборе (верхняя крышка не показана)
В ходе технико-экономического анализа разработанного измерителя АЧХ было выяснено, что по большинству показателей разработанный измеритель АЧХ превосходит аналог АСК-4106 фирмы Актаком. Кроме того, масса разработанного измерителя АЧХ меньше почти в 2 раза, а габариты – в 3 раза. Потребляемая мощность также значительно ниже. Стоимость основных материалов и покупных комплектующих изделий составила 2185 р., договорная цена – 9450 р. Оптовая цена АСК-4106 составляет 12050 р. Таким образом, разработанный измеритель АЧХ является конкурентоспособным и займет достойное место на рынке.
Список литературы