

6.7Организация кэш–памяти на основе ассоциативного запоминающего устройства (кэш с ассоциативной организацией)
В этом случае всё пространство ОП разделяется на блоки (строки кэша) размером Естр=2n, n<<m, которые принимаются за единицу обмена кэша с ОП. Пример: m=26, n=5 (строка длиной 32 байта).
Всё пространство кэш–памяти также разделяется на строки ёмкостью 2n. В результате адреса ячеек ОП и кэша разделяются на поля:
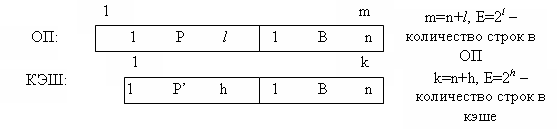
Пример: m=36, n=5, l=21, k=16, h=11.
Структура кэш с ассоциативной организацией типа 3D представлена на рисунке 6.12.
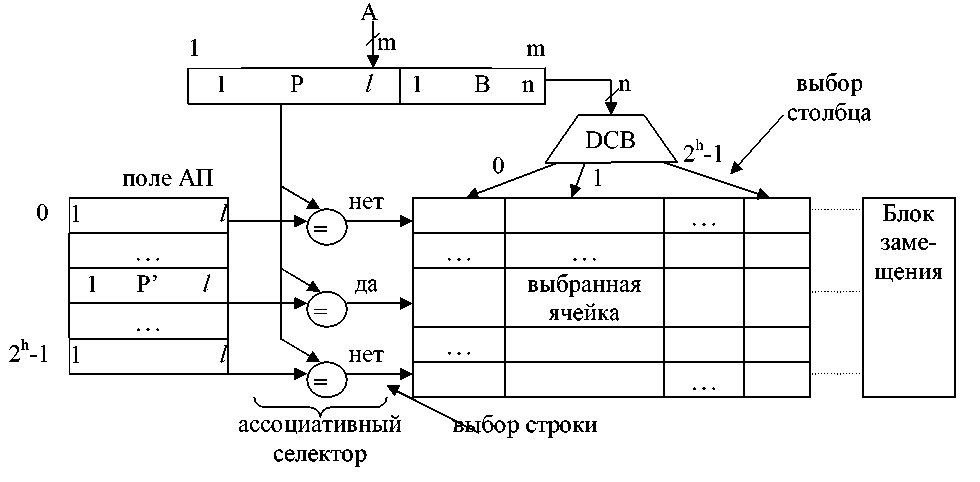
Рисунок 6.12 – Структура кэш с ассоциативной организацией
Если ассоциативный признак Р=Р’, то обращение осуществляется к выбранной по ‘да’ строке кэша. Выбор ячейки в строке осуществляется при помощи дешифратора DСВ (в примере В=1), т.е. по адресному принципу.
Если Р≠Р’, то производится замещение: адресуемый блок Р извлекается из ОП и переписывается в свободную или специально освобождённую строку кэша. Освобождение строки кэша осуществляется путём её переписи обратно в ОП по старому адресу Р.
Основной недостаток – большие затраты оборудования на селектор. Пример: m=26, n=5, l=21, k=16, h=11, Nсел=l*2h=21*211=42K (K=210) элементов сравнения.
В силу указанного недостатка кэш с чисто ассоциативной организацией обычно не применяется. С целью экономии оборудования используется более простая организация – кэш с наборно–ассоциативной организацией (архитектурой) (рисунок 6.13). В этом случае адрес А ячейки ОП делится на 3 поля: в третьем (старшем) поле G указывается номер группы строк (в нашем примере t=10). В группу объединяются две (четыре, ...) строки.
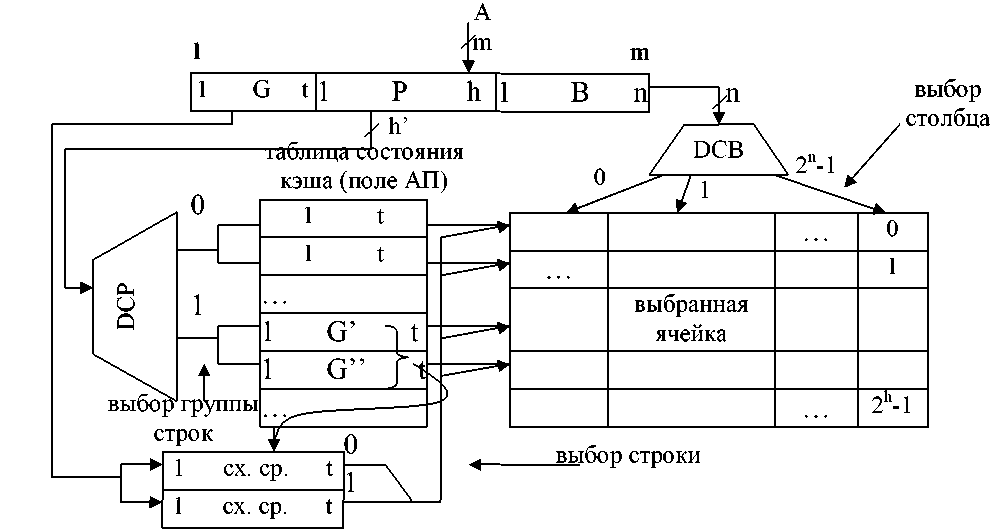
Рисунок 6.13
Экономия оборудования достигается за счёт того, что ассоциативный поиск остаётся только в группе из r строк (в примере r = 2). Выбор же группы строк осуществляется по адресному принципу при помощи дешифратора DСР. Таким образом, количество схем сравнения уменьшается до r, т.е. до количества строк в группе, а разрядность схем сравнения уменьшается до t . В результате затраты оборудования на ассоциативный поиск сокращаются до величины: Nасс = rt (пример: r=2, t=10, N=20).
Кроме того, сокращается длина ячеек поля АП до t разрядов, что также экономит оборудование. Правда, появляется дополнительный дешифратор DСР с количеством входов 2h’, где h’=h-log2r (в примере h’=h-1=10). Количество строк в группе определяется уровнем мультипрограммирования: r = M.
Кэш с наборно–ассоциативной архитектурой широко используется в IBM PC. Другие особенности организации кэш–буфера в IBM PC. Двухуровневая организация кэша: кэш первого уровня встраивается в процессор (конструктивно), а кэш второго уровня – вне ЦП, причём кэш второго уровня имеет большую ёмкость, чем кэш первого уровня. Кэш первого уровня работает на более высокой частоте – частоте ЦП, а второго – на частоте интерфейса ЭВМ (например, PCI). Вторая особенность (начиная с процессора Pentium): внутренний кэш делится на две части по назначению – кэш команд и кэш данных (т.н. Гарвардская архитектура ЭВМ).
6.8Организация стековых (магазинных) запоминающих устройств
ЗУ со стековой организацией широко используется при построении системы прерываний ЭВМ, а также при программировании алгоритмов, связанных с обработкой данных типа вектор, массив (переменных с индексами). Стековые ЗУ обеспечивают запись, чтение информации в соответствии с правилом: последним пришёл, первым вышел (LIFO). В них при обращении доступна только одна ячейка – т.н. вершина стека. При записи в стек слово сначала записывается в вершину стека, а затем проталкивается внутрь ЗУ и т.д. при записи очередных слов. При выполнении операции чтения слово сначала выталкивается в вершину стека, а затем подаётся на выходную шину ЗУ.
Технически такая память может быть реализована на основе сдвиговых регистров в количестве n – штук: количество сдвиговых регистров определяется разрядностью ячеек – n. Разрядность регистров сдвига определяется ёмкостью стека. Такая организация стека называется магазинной памятью (рисунок 6.14).
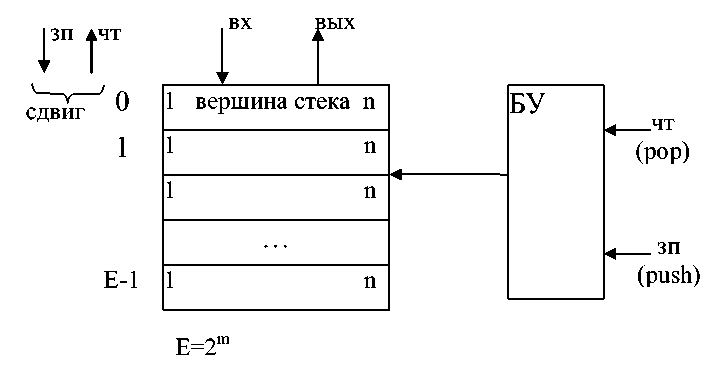
Рисунок 6.14 – Структура магазинных ЗУ
Одна из основных проблем магазинных ЗУ – переполнение стека, которое ведёт к потере информации, поэтому не допустимо. Следить за возможным переполнением должен сам программист.
Недостаток ЗУ магазинного типа – большие затраты оборудования и, следовательно, высокая удельная стоимость: сдвиговые регистры сложнее обычных.
Стековые ЗУ по этой причине (с целью экономии оборудования) обычно организуются другим способом: вместо сдвига информации в них используется подвижный указатель вершины стека (УС). Структура стекового ЗУ представлена на рисунке 6.15. Операция записи осуществляется по сигналу ЗП: 1) ЗП: [УС]:=ВХ; 2) УС:=УС+1, т.е. сначала производится запись слова в вершину стека (в ячейку, на которую указывает УС), а затем УС инкрементируется. Операция чтения реализуется по сигналу чтения ЧТ: 1) УС:=УС-1; 2) ВЫХ:= [УС].
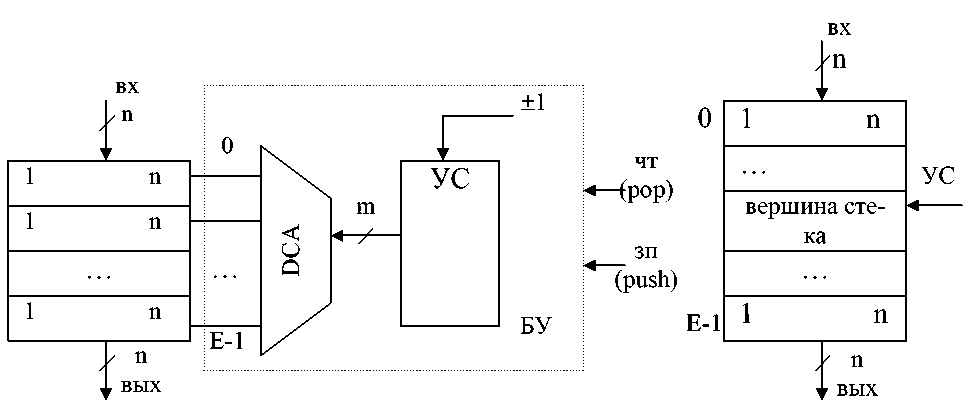
Рисунок 6.15
Технически УС реализуется на основе реверсивного счетчика.
Следует отметить, что запоминающая часть стековых ЗУ обычно располагается в адресном пространстве ОП: часть ячеек ОП отводится под стек.