

Методическое пособие 640
.pdfb и менее, устанавливается теоремой, называемой границей Рейгера, которая определяет минимальное число проверочных символов в коде.
Теорема. Любой линейный блоковый код, исправляющий все пакеты длиной b и менее, должен содержать, по крайней мере
r n k 2b |
(8.1) |
проверочных символов.
На первый взгляд данная граница совпадает с границей Синглтона (7.20), однако это только внешнее сходство, поскольку она имеет отношение к специфическим моделям ошибок (пакетам) и доказывается особым образом.
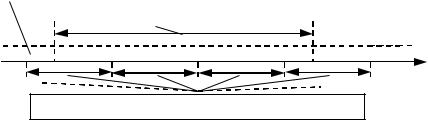
Наглядным примером кода, обладающим значительной способностью исправления пакетов ошибок, служит РС–код в двоичном представлении. Объяснение этому факту дает иллюстрация, представленная на рис. 8.2, которая отражает ситуацию, когда пакет из b двоичных символов затрагивает последовательно t или менее q–ичных символов, т.е. t блоков, каждый из которых содержит m или менее (для крайних) двоичных символов. (рис. 8.2 отвечает случаю t 4). Тогда, учитывая исправляющую способность исходного кода, будут исправлены указанные t q–ичных ошибок. Последнее означает, что удается исправить пакет ошибок длины
bm(t 1) 1 m[(nb kb)/2m 1] 1
именее, выраженной в числе двоичных символов. Если число проверочных символов РС–кода достаточно велико (t 1), то
b mt (nb kb)/2, и, значит, двоичная версия РС–кода, бу-
дучи достаточно слабой в отношении случайных ошибок, оказывается близкой к оптимальной (в смысле границы Рейгера) в исправлении пакетов ошибок. Вследствие этого РС–коды рассматриваются в качестве предпочтительного варианта для использования в каналах с группированием ошибок.
251
Двоичный |
|
|
|
|
|||
|
Пакет из b двоичных символов поражает |
||||||
|
символ |
|
|||||
|
|
t=4 q-ичных символов |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t
m двоичных символов =одному q-ичному
Рис. 8.2 Структура РС-кода
8.3. Кодирование с перемежением
Альтернативным способом борьбы с пакетами ошибок случит операция перемежения (чередования) символов кода. Под чередованием понимается процедура, направленная на рассеяние во времени пакета ошибок, т.е. приближение к модели ошибок, в которой они являются независимыми, одиночными и случайно распределенными. Как правило, устройства перемежения реализуются в одном из двух вариантов – блочном или сверточном. Оба указанных типа перемежителей находят широкое применение как в сочетании с блоковыми, так и сверточными кодами. Для понимания сущности операции перемежения кодовых символов рассмотрим простейший вариант реализации устройства блокового перемежения. Предположим, что используется блоковый код длины n, исправляющий ошибки кратности t включительно. Разделим поток кодированных символов на кадры, содержащие B кодовых слов (или, что то же самое, nB символов) каждый. Изменим порядок следования символов в пределах каждого кадра путем образования n последовательных блоков из B символов, в которых первый блок содержит первые символы всех B кодовых слов, второй блок – вторые символы кодовых слов и т.д. Переупорядоченный подобным образом поток символов передается по каналу связи. На приемной стороне осуществляется обратная опера-
252

ция – деперемежение – и, тем самым, восстанавливается исходный порядок следования символов.
Предположим, что при распространении по каналу на передаваемый поток данных воздействует пакет из b ошибочных символов. Тогда после операции деперемежения все ошибочные символы будут единообразно распределены между B кодовыми словами. Если к тому же в каждое кодовое слово попадет не более, чем t ошибок, то все они будут успешно исправлены вследствие корректирующей способности применяемого блокового кода. Значит, блоковое перемежение с длиной кадра в B кодовых слов позволяет исправлять пакеты ошибок длиной вплоть до
b Bt
включительно.
При такой обработке кодовой и принятой последовательностей ошибки на входе декодера распределяются более равномерно.
Структурная схема системы с перемежением показана на рис. 8.3.
Вход данных |
|
|
|
|
|
Выход данных |
||
|
|
|
|
|
|
|
|
|
|
|
Устройство |
|
Канал с |
|
Устройство |
|
|
Кодер |
|
|
Декодер |
|||||
|
перемеже- |
|
пакетами |
|
восстановле- |
|
||
|
|
ния |
|
ошибок |
|
ния |
|
|
|
|
|
|
|||||
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
Рис. 8.3. Схема системы с перемежением
Устройство перемежения в этой схеме переупорядочивает (переставляет) символы передаваемой последовательности некоторым детерминированным образом. С помощью устройства восстановления производится обратная перестановка, восстанавливающая исходный порядок следования символов. Используются различные способы перемежения-восстановления. Первый способ – периодическое перемежение. Он проще, но
253
при изменении характера помех может оказаться неустойчивым. Более сложное – псевдослучайное перемежение, которое обладает при нестационарных ошибках гораздо большей устойчивостью.
При периодическом перемежении функция перестановок периодична с некоторым периодом. Перемежение может быть блочным, когда перестановки выполняются над блоком данных фиксированного размера, или сверточным, когда процедура выполняется над непрерывной последовательностью.
При псевдослучайном перемежении блоки из L символов записываются в память с произвольной выборкой (ЗУПВ), а затем считываются из нее псевдослучайным образом. Порядок перестановок, одинаковый для устройств перемежения и восстановления, можно записать в ПЗУ и использовать его для адресации ЗУПВ.
Как и для периодического перемежения, существует вероятность того, что ошибки будут следовать таким образом (синхронно с перемежением), что одиночные ошибки будут группироваться в пакеты. Но такая вероятность чрезвычайно мала (если, конечно, это не организованная помеха и противник не знает порядка перемежения). Случайное же совпадение порядка следования перестановок при перемежении и импульсов помехи при достаточной длине L практически невероятно.
Что касается характера псевдослучайного перемежения, то для этого могут использоваться любые псевдослучайные последовательности – линейные и нелинейные последовательности максимальной длины, последовательности, основанные на линейном сравнении, а также любые алгоритмы формирования псевдослучайных чисел с необходимым периодом повторения.
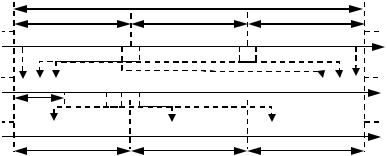
Обсужденная процедура исправления пакета ошибок поясняется на примере блокового перемежения кода Хэмминга длины n=7 с величиной кадра В=3, представленном на рис. 8.4.
254
|
|
|
|
|
|
n=7 |
|
|
|
|
|
|
B=3 |
|
|
|
|
|
|
|
|
|
|
|
|
||||
Кодирован- |
|
|
|
|
|
|
|
|
|
|
|
|
n=7 |
|
|
|
|
|
|
n=7 |
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ный поток |
1 |
|
2 |
3 |
|
4 |
|
5 |
|
6 |
7 |
8 |
9 |
10 |
11 |
|
12 |
13 |
14 |
15 |
16 |
17 |
|
18 |
19 |
20 |
21 |
t |
|
Перемеж. |
|
|
|
|
|
|
|
|
Пакет |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
символы |
1 |
|
8 |
15 |
|
2 |
|
9 |
|
16 |
3 |
10 |
17 |
4 |
|
11 |
|
18 |
5 |
12 |
19 |
6 |
13 |
|
20 |
7 |
14 |
21 |
t |
|
|
B=3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Деперемеж. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
символы |
1 |
|
2 |
3 |
|
4 |
|
5 |
|
6 |
7 |
8 |
9 |
10 |
|
11 |
|
12 |
13 |
14 |
15 |
16 |
17 |
|
18 |
19 |
20 |
21 |
t |
|
|
|
|
|
|
n=7 |
|
|
|
|
|
|
|
|
n=7 |
|
|
|
|
|
|
n=7 |
|
|
|
||||
Рис. 8.4. Блоковое перемежение
Практическая реализация процедуры перемежения осуществляется следующим образом. Кодированный поток данных предварительно построчно записывается в матрицу памяти размером B строк и n столбцов, а затем считывается по столбцам. Ясно, что операция деперемежения производится в обратном порядке.
Способность исправлять пакеты ошибок в результате операции перемежения достигается в обмен не только на аппаратурное усложнение, но и появление дополнительной временной задержки в передаче данных, равной
Td 2(B 1)(n 1)
в числе временных интервалов двоичных символов. Перемежение, как способ борьбы с пакетами ошибок,
находит широкое применение в современных телекоммуникационных системах.
8.4. Обнаружение и исправление ошибок в технике связи
Обнаружение ошибок в технике связи – действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) – процедура восстановления информации после чтения её из устройства
255
хранения или канала связи. Для обнаружения ошибок используют коды обнаружения ошибок, для исправления – корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды). В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок – важные задачи на многих уровнях работы с информацией.
Помехоустойчивое кодирование, вообще-то, не является обязательной операцией при передаче информации. Эта процедура в принципе может отсутствовать. Однако это может привести к очень существенным потерям в помехоустойчивости системы, значительному уменьшению скорости передачи и снижению качества передачи информации. Поэтому практически все современные системы (за исключением, быть может, самых простых) должны включать и обязательно включают помехоустойчивое кодирование данных.
Всистемах связи возможны несколько стратегий борьбы
сошибками:
–обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков – этот подход применяется в основном на канальном и транспортном уровнях;
–обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков – такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
–исправление ошибок применяется на физическом
уровне.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её. Любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
256
Хороший код должен удовлетворять, как минимум, сле-
дующим критериям:
1)способность исправлять как можно большее число
ошибок,
2)как можно меньшая избыточность,
3)простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, поэтому при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой или мобильной связи остро стоит вопрос экономии энергии, а в телефонной связи неограниченно повышать мощность сигнала не дают технические ограничения.
Коды, исправляющие ошибки, применяются:
–в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
–в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней [13].
8.5 Кодирование непрерывных источников
Методы кодирования источника базируются на точном априорном знании вероятностей всех его сообщений. На практике, однако, нередки ситуации, когда статистика источника заранее неизвестна, и для преодоления априорной неопреде-
257
ленности приходится оценивать вероятности сообщений непосредственно в процессе кодирования. Подобный подход лежит в основе схем словарного кодирования, основой которого является алгоритм Лемпеля-Зива. Более сложная ситуация имеет место в случае рассмотрения непрерывного источника сообщений, ансамбль которого представляет собой континуальное множество. Одним из наиболее распространенных типов подобных источников служит источник речи, в связи с чем ему и будет уделено основное внимание.
Передача речи является основным, обязательным режимом работы систем мобильной связи. Звук с помощью акустоэлектронного преобразователя (микрофона) превращается в аналоговый электрический сигнал. Поскольку в цифровых системах связи канальному кодированию подвергается последовательность бит, аналоговый речевой сигнал должен быть представлен в цифровой форме. При этом для эффективного использования канала требуется устранить его избыточность до величины, позволяющей на приемной стороне восстановить по нему звук с сохранением индивидуальных особенностей голоса (натуральность).
За длительный период развития телефонной связи были достаточно подробно изучены характеристики речи и устройство речевого аппарата человека. Так, установлено, что для обеспечения приемлемого качества восстановленной речи достаточно анализировать (передавать) речевой сигнал в полосе частот 300…3400 Гц. Выяснены и причины большой избыточности речевого сигнала. К ним относятся:
неравномерное распределение значений (отсчетов) сигнала (редки большие отсчеты);
высокая корреляция соседних отсчетов;
корреляция удаленных отсчетов, обусловленная периодичностью сигнала;
корреляция между периодами основного тона;
избыточность из-за пауз между слогами, словами, фразами при монологе, которые составляют (в среднем) до 25% вре-
258
мени разговора, и пауз, когда надо слушать собеседника (до 50% времени).
Задача устранения этой избыточности возлагается на речевые кодеки – устройства, осуществляющие кодирование речевого сигнала и его декодирование (восстановление). Основная проблема при разработке кодеков состоит в получении высокой степени сжатия без чрезмерного снижения качества восстановленной речи. Таким образом, основными характеристиками кодеков являются скорость преобразования
Rt k/ t, |
(8.4) |
где k – число бит на выходе кодера на интервале времени t, и качество восстановленной речи.
Скорость преобразования Rt является важной характери-
стикой речевых кодеков, так как определяет требуемую пропускную способность канала для передачи речи. Сжатие сигнала тем больше и, следовательно, кодек тем эффективнее, чем меньше Rt (при обеспечении требуемого качества восстанов-
ленной речи).
Методы сжатия речевых сообщений можно разделить на
2 группы: кодеры формы сигнала и вокодеры. Совместное ис-
пользование этих методов характерно для так называемых ги-
бридных кодеров.
Рассмотрим кодеры формы сигнала. Они позволяют сохранить основную форму непрерывного сигнала. Они не являются специфичными для речи и могут применяться для сжатия любого непрерывного сигнала. Непрерывный сигнал источника кодируется в 2 этапа. Сначала с помощью аналого-цифрового преобразования (АЦП) формируются последовательности, дискретные по уровню и времени, т. е. производится так называемое натуральное кодирование. Затем используются собственно методы сжатия дискретных последовательностей.
На рис. 8.5 показано преобразование непрерывного сигнала в цифровую форму. В литературе эта операция часто име-
259
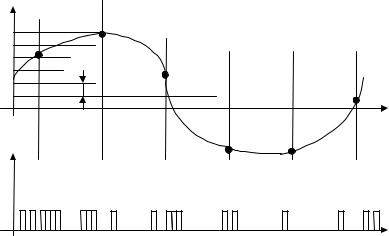
нуется импульсно-кодовой модуляцией (ИКМ), хотя в реально- |
|||||
сти ни о какой модуляции несущей речь не идет. |
|
||||
x(t) |
|
|
|
|
|
|
+98 |
|
|
|
|
+47 |
|
+28 |
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
+5 |
n–5 |
n–4 |
n–3 |
n–2 |
n–1 |
n t |
ИКМ |
|
|
–20 |
–32 |
|
|
|
|
|
|
|
s(n–5) s(n–4) |
s(n–3) s(n–2) |
s(n–1) |
s(n) |
||
10101111 |
11100010 |
10011100 |
00010100 |
00100000 |
10000101 |
t
Рис. 8.5. Импульсно–кодовая модуляция
В соответствии с теоремой Котельникова аналоговый сигнал x(t) заменяется своими непрерывными отсчетами xн(n t),
взятыми через интервал времени t 1/Fд, где Fд – частота дискретизации, в два раза превышающая верхнюю частоту Fв
спектра x(t). Поскольку t известен и на приемной стороне, в обозначениях его можно опустить.
Далее диапазон изменения xн(n) разбивается на 2k
дискретных уровней через интервалы x, называемые шагом квантования. Отсчет xн(n), удовлетворяющий условию s(n) x xн(n) [s(n) 1] x , где s(n) – целое, принадлежащее отрезку [ 2k 1, 2k 1], заменяется значением s(n) x. При этом возникает погрешность, максимальное значение которой равноx. Последовательность таких погрешностей называется шу-
мом квантования.
260