

Методическое пособие 639
.pdfприведет к потере первоначальных наблюдений, а они еще будут нужны.
Для стандартизации данных необходимо выделить всю таблицу с имеющимися данными и выполнить команду Данные / Стандартизировать (Data / Standardize). Таблица с нормализованными данными приведена на рис. 50.
Рис. 50. Исходные данные после стандартизации
Вначале проведем иерархический кластерный анализ. Для этого выполним команду Анализ / Многомерный разведочный анализ / Кластерный анализ / Иерархическая классификация (Statistics / Multivariate exploratory techniques / Cluster analysis / Joining (tree clustering)). В открывшемся диалоговом окне (рис. 51) необходимо выбрать для анализа все переменные. При необходимости на вкладке Дополнительно (Advanced) можно выбрать меру расстояния между объектами в кластерах и между кластерами.
Для просмотра результатов кластерного анализа доступны различные команды из диалогового окна Результаты иерархической классификации (рис. 52). Наиболее важным результатом является иерархическое дерево (дендрограмма), которое в системе STATISTICA может быть построено как в
81
горизонтальном, так и в вертикальном виде. Пример вертикальной дендрограммы показан на рис. 53.
Рис. 51. Диалоговое окно с входными параметрами иерархического кластерного анализа
Рис. 52. Диалоговое окно с результатами иерархического кластерного анализа
82
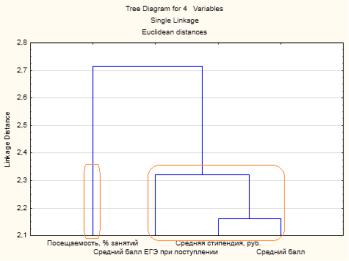
Рис. 53. Вертикальная дендрограмма
В рассматриваемом примере дендрограмма имеет очень простой вид и по ней можно сделать вывод о наличии двух кластеров (для наглядности выделены красным цветом).
Проверить значимость различий между полученными группами можно с помощью раздельного кластерного анализа методом k-средних (Анализ / Многомерный разведочный анализ / Кластерный анализ / Кластерный анализ методом k- средних). Для его выполнения в диалоговом окне необходимо выбрать все переменные и в списке Объекты выбрать Наблюдения (Строки). При необходимости на вкладке Дополнительно можно выбрать число кластеров (рис. 54).
83
Рис. 54. Диалоговое окно входных параметров кластерного анализа методом k-средних
Результаты кластерного анализа можно просмотреть с помощью различных кнопок из диалогового окна Результаты метода k-средних (рис. 55). Для оценки значимости различий необходимо открыть таблицу Дисперсионный анализ (рис. 56).
В данном примере можно сделать вывод, что различия между группами значимые, т.к. значимость критерия Фишера меньше 0.05.
Распределение элементов между кластерами можно просмотреть, нажав на кнопку Элементы кластеров и расстояния (Members of each cluster & distances). Таблицы с элементами двух кластеров показаны на рис. 57. Для наглядности здесь обе таблицы приведены вместе, но фактически они расположены на разных вкладках.
84
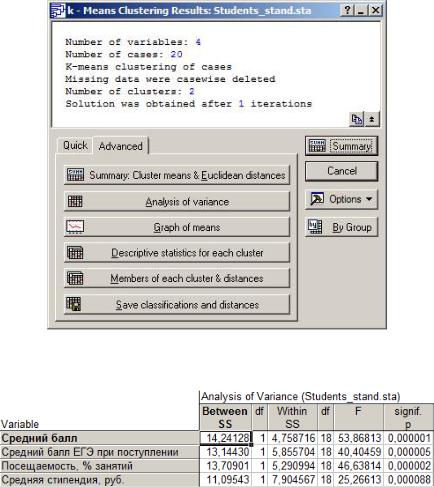
Рис. 55. Диалоговое окно с результатами кластерного анализа методом k-средних
Рис. 56. Таблица с результатами дисперсионного анализа
85
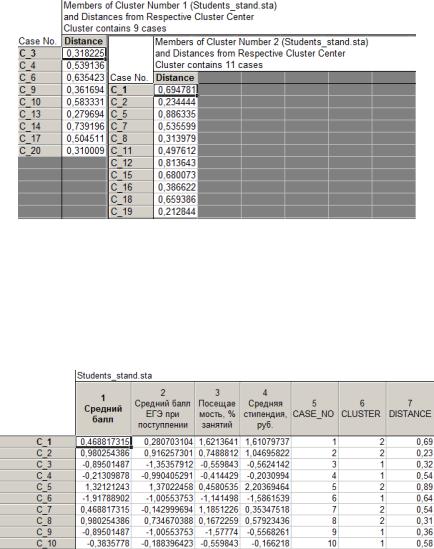
Рис. 57. Таблицы с распределением элементов по кластерам
Для сохранения результатов кластерного анализа надо нажать кнопку Сохранить классификацию и расстояния в окне с результатами анализа методом k-средних. При этом в исходную таблицу проекта добавятся столбцы с номером наблюдения, номером кластера и расстоянием (рис. 58).
Рис. 58. Фрагмент таблицы с результатами кластерного анализа
Для сравнения кластеров необходимо определить основные статистические характеристики для каждого
86
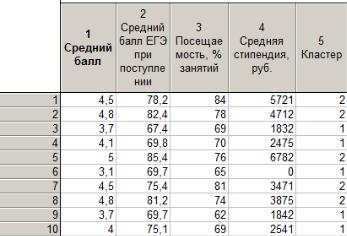
кластера. С этой целью скопируем столбец с номером кластера в таблицу с исходными данными до стандартизации (рис. 59).
Рис. 59. Фрагмент исходной таблицы с добавленным столбцом с номером кластера
Далее надо выбрать команду Анализ / Основные статистики и таблицы / Группировка и однофакторный ДА
(Statistics / Basic statistics/tables / Breakdown & one-way ANOVA). В диалоговом окне с входными параметрами в качестве переменной группировки указывается Кластер, а все остальные признаки будут зависимыми. На вкладке Список таблиц (рис. 60) можно выбрать параметры, которые будут выводиться в итоговых таблицах.
Результаты анализа можно просмотреть с помощью различных кнопок соответствующего диалогового окна (рис. 61). При нажатии на кнопку Итоги: таблица статистик
(Summary: table of statistics) откроется таблица с основными показателями для каждого кластера. Т. к. ранее для отображения была выбрана одна таблица средних, то выводится только средние значения признаков для каждого кластера (рис. 62).
87
Рис. 60. Диалоговое окно с параметрами отображения группированных данных
Рис. 61. Диалоговое окно с результатами группировки
88
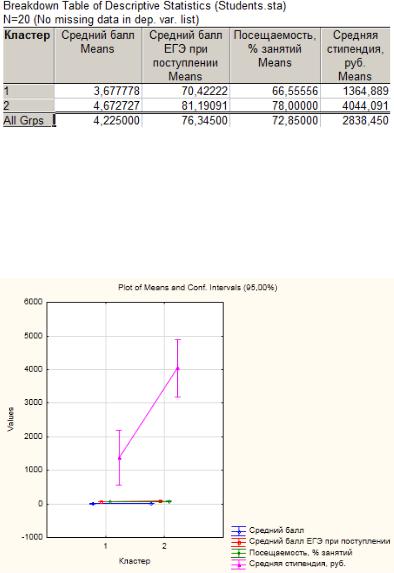
Рис. 62. Таблица со средними значениями признаков для каждого кластера
Для визуального сравнения кластеров можно построить график средних и доверительных интервалов (рис. 63) и ящичные диаграммы, по которым также можно сделать выводы о различии кластеров.
Рис. 63. График средних и доверительных интервалов
89
2.4.Пример выполнения дискриминантного анализа
всистеме STATISTICA
Проверим качество классификации, выполненной с помощью кластерного анализа. Для этого надо открыть таблицу с распределением элементов выборки по группам (рис. 59) и выбрать команду Анализ / Многомерный разведочный анализ / Дискриминантный анализ (Statistics / Multivariate exploratory techniques / Discriminant analysis). В
диалоговом окне Анализ дискриминантных функций
(Discriminant function analysis) (рис. 64) необходимо нажать на кнопку Переменные (Variables) и задать в качестве группирующей переменной столбец Кластер, а в качестве независимых переменных – все остальные столбцы.
Рис. 64. Диалоговое окно Анализ дискриминантных функций
Для проверки корректности обучающей выборки в диалоговом окне с результатами дискриминантного анализа (рис. 65) на вкладке Классификация (Classification) необходимо открыть таблицу Матрица классификации
(Classification Matrix) (рис. 66).
90