

Методическое пособие 639
.pdfРис. 43. Диалоговое окно спектрального анализа для одного ряда
Высокие пики на периодограмме (рис. 44) свидетельствуют о наличии периодичности. По данному графику можно предположить наличие циклов с периодом 6 лет. Значение пика отображается при наведении указателя на соответствующую точку периодограммы.
Рис. 44. Периодограмма для временного ряда
71

Для прогнозирования поведения временного ряда в системе STATISTICA применяется несколько методов, самым простым из которых является прогноз с помощью метода экспоненциального сглаживания. Из-за невысокой точности данный метод применяется, в основном, для краткосрочных прогнозов.
Процедура прогнозирования поведения временного ряда методом экспоненциального сглаживания вызывается из диалогового окна Временные ряды и прогнозирование с помощью кнопки Exponential smoothing and forecasting (Экспоненциальное сглаживание и прогнозирование). Откроется диалоговое окно Seasonal and Non-Seasonal Exponential smoothing (рис. 45).
Рис. 45. Диалоговое окно Сезонное и несезонное экспоненциальное сглаживание
Для выполнения прогнозирования необходимо задать сезонную компоненту, вид модели и параметры Alpha, Delta и Gamma. Автоматически определить данные параметры можно,
72

нажав на вкладке Grid search кнопку Perform grid search.
Откроется таблица, в которой и будут указаны рекомендуемые значения параметров (рис. 46).
Рис. 46. Рекомендуемые значения параметров прогнозирования
Над таблицей приводятся характеристики модели ряда (линейный тренд, аддитивная сезонная компонента, равная 5), в первой строке указаны рекомендуемые значения Alpha, Delta и Gamma, при которых ошибка прогнозирования будет минимальной. Как видно, рекомендуемая сезонная компонента совпадает с определенной ранее периодичностью ряда. Данные параметры необходимо задать на вкладке Quick и
нажать кнопку Summary: Exponential smoothing. Откроется диалоговое окно, содержащее следующие результаты прогнозирования:
-таблицу с исходными, сглаженными значениями ряда, остатками и прогнозными значениями на 10 интервалов вперед
(рис. 47);
-таблицу с различными оценками ошибки сглаживания, которая может быть использована для корректировки параметров сглаживания;
-графики исходного, сглаженного рядов и ряда остатков (рис. 48).
Переключаться между различными результатами можно
спомощью дерева на панели слева или с помощью кнопок, расположенных в правом нижнем углу окна.
73

Рис. 47. Таблица с результатами прогнозирования
Рис. 48. Графики исходного, сглаженного рядов и ряда остатков
Красной линией на графике показан сглаженный ряд, содержащий прогноз для 10 следующих элементов ряда.
74
3. ЛАБОРАТОРНОЕ ЗАДАНИЕ
Задание 1. Выбрать объект наблюдений и найти или задать самостоятельно для него ряд динамики объемом не менее 40 элементов, содержащий не менее пяти периодов.
Задание 2. Выполнить анализ и прогнозирование временного ряда.
4.УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ОТЧЕТА
Отчет должен содержать:
- наименование и цель работы; - краткие теоретические сведения;
- задание на лабораторную работу; - результаты выполнения лабораторной работы.
5.КОНТРОЛЬНЫЕ ВОПРОСЫ
1.Что такое временной ряд? Какие составляющие можно выделить в общей вариации наблюдаемых данных?
2.Какие модели применяются для описания временных
рядов?
3.Что такое автокорреляционная функция? Для чего она применяется?
4.Какой модуль предназначен для анализа временных рядов в системе STATISTICA?
5.Как выполнить прогнозирование временных рядов в системе STATISTICA?
75
Лабораторная работа №6 ОСНОВНЫЕ МЕТОДЫ КЛАССИФИКАЦИИ
НАБЛЮДЕНИЙ
СПОМОЩЬЮ ПАКЕТА STATISTICA
1.ОБЩИЕ УКАЗАНИЯ ПО ВЫПОЛНЕНИЮ ЛАБОРАТОРНОЙ РАБОТЫ
1.1.Цель работы
Изучение основных принципов работы с электронными таблицами в системе STATISTICA; получение практических навыков выполнения кластерного анализа в пакете
STATISTICA.
1.2.Используемое оборудование и программное обеспечение
Для выполнения лабораторной работы требуется ПЭВМ типа IBM PC с установленной ОС Windows XP и выше, пакет STATISTICA 10 или последующих версий.
2. МЕТОДИЧЕСКИЕ УКАЗАНИЯ ПО ВЫПОЛНЕНИЮ ЛАБОРАТОРНОЙ РАБОТЫ
2.1. Основные понятия кластерного анализа
При анализе результатов наблюдений часто возникает задача объединения элементов выборки со схожими параметрами в отдельные группы, причем множество таких групп может быть известно (задача классификации данных) или неизвестно (задача кластеризации данных).
Кластерный анализ – метод анализа, позволяющий выявить наличие внутренних связей между элементами выборки и разделить на их основе данные на множество групп со схожими параметрами (кластеры).
Кластерный анализ чаще всего применяется в тех случаях, когда неизвестно число групп, на которые следует разделить элементы исходной выборки, т. е. в задачах поиска структуры для малоизученных явлений. Например, если нужно
76
разделить на отдельные рыночные сегменты потребителей, обладающих определенной совокупностью характеристик (возраст, образование, доход, тип личности, место жительства и т.д.). Полученная классификация может использоваться для определения возможности и готовности каждой группы потребителей приобретать конкретные товары.
Пусть есть результаты наблюдений за множеством
объектов |
X (X1,X2,...,Xn), |
|
где |
|
каждый |
объект |
||
характеризуется |
m признаками, |
т. |
е. Xi (xi1,xi2,...,xim), |
|||||
i 1,...,n. |
Совокупность значений |
признаков сводится в |
||||||
матрицу |
|
|
|
|
|
|
|
|
|
|
x11 |
x12 |
... |
x1m |
|
|
|
|
|
|
x22 |
... |
x2m |
|
|
|
|
|
x21 |
|
|
|
|||
|
|
X |
|
... |
... |
. |
|
|
|
|
... ... |
|
|
|
|||
|
|
|
xn2 |
... |
|
|
|
|
|
|
xn1 |
xnm |
|
|
|||
Задача |
кластерного |
анализа |
может |
быть |
||||
сформулирована следующим образом: необходимо разбить множество объектов Х на s n кластеров K1,K2,...,Ksтаким образом, чтобы каждый объект Xi принадлежал только одному кластеру Kj, т.е.
K1 K2 ... Ks X,
Ki Kj , i j, i,j 1,...,m.
и чтобы объекты, принадлежащие одному и тому же кластеру, были схожими, а объекты, принадлежащие разным кластерам, несходными.
Различие и схожесть объектов определяется на основе
расстояния (метрики) d(Xi,Xj) между объектами Xi и Xj, i, j 1,...,n .
В кластерном анализе используются следующие расстояния d(Xi,Xj) между объектами:
- евклидово расстояние: 77
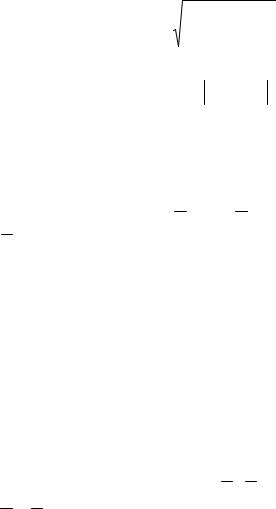
d(Xi,Xj) |
m |
xik xjk ; |
k1
-сумма абсолютных отклонений (городская метрика):
m
d(Xi,Xj) xik xjk ;
k1
-обобщенное евклидово расстояние (расстояние
Махаланобиса):
d(Xi,Xj) (Xi Xj) S 1 (Xi Xj) ,
где S –матрица рассеяния, вычисляемая следующим образом:
S (X X)T(X X),
где X - матрица, столбцы которой равны средним значениям соответствующих переменных.
В качестве меры близости между кластерами могут использоваться следующие расстояния:
- расстояние, изменяемое по принципу ближайшего соседа:
Dmin(Kg,Kh) |
min |
Xi,Xj ; |
Xi Kg ,Xj Kh
-расстояние, изменяемое по принципу дальнего соседа:
Dmax(Kg,Kh) |
max |
Xi,Xj ; |
Xi Kg,Xj Kh
-расстояние, изменяемое по центрам тяжести кластеров:
Dср(Kg,Kh) d(Xi,Xj),
где Xi , Xj - арифметические средние наблюдений, входящих
в кластеры Kg и Kh , соответственно.
Можно выделить два класса задач иерархического анализа:
- раздельный кластерный анализ – разбиение множества из n элементов на m кластеров;
78
- иерархический кластерный анализ – получение всей иерархии разбиений, более точно характеризующей структуру связей в наблюдениях.
2.2. Основные понятия дискриминантного анализа
Дискриминантный анализ – это статистический метод, позволяющий изучить различия между двумя и более группами объектов по нескольким характеризующим их признакам.
Дискриминантный анализ используется для классификации наблюдений в тех случаях, когда есть набор объектов, для которых известно, к каким группам они принадлежат, т. е. есть обучающая выборка, классификация которой была проведена, например, с помощью кластерного анализа. В дальнейшем обучающая выборка используется для определения параметров процедуры анализа.
Данный метод анализа позволяет выяснить, действительно ли группы наблюдений различаются между собой, и если да, то какие переменные вносят наибольший вклад в имеющиеся различия.
Для классификации объектов для каждой группы наблюдений строятся дискриминантные функции вида
Fi a1ix1 a2ix2 ... amixm bi ,
где aji - коэффициент j-го признака для i-й группы, i 1,...,s,
j 1,...,m, x j - значение j-го признака объекта, bi - свободный
коэффициент для i-й группы.
Каждая группа объектов имеет свой набор коэффициентов aji , вычисляемых по обучающей выборке. Для
определения принадлежности к какой-либо группе нового объекта по значениям его признаков x j находятся значения
всех функций Fi и объект относится к той группе, для которой функция Fi максимальна.
79

2.3. Пример выполнения кластерного анализа в системе STATISTICA
Проведем кластерный анализ группы выпускников вуза, для каждого из которых заданы четыре признака – средний балл за весь период обучения, средний балл ЕГЭ при поступлении, посещаемость занятий и средний размер стипендии за все время обучения. Таблица с исходными данными приведена на рис. 49.
Рис. 49. Фрагмент листа с исходными данными
Поскольку признаки исследуемых объектов имеют разные единицы измерения и диапазоны изменения значений, то для анализа их необходимо привести к одной шкале измерения, т.е. стандартизировать (нормализовать) таким образом, чтобы все переменные имели среднее значение 1 и стандартное отклонение 0.
Перед выполнением стандартизации необходимо сохранить файл с исходными данными под другим именем и все изменения производить уже в нем, т. к. данная процедура
80