

Быстрое появление этих систем можно отнести к числу настоящих и будущих факторов развития вычислительной техники.
Ключевым преимуществом FPGA при использовании OpenCL для ускорения работы алгоритмов является то, что при имплементации в FPGA легко применять структуры, которые опираются на широкую гетерогенную уникальную конвейерную реализацию. Эти реализации характеризуются тем, что в них параллелизм достигается тиражированием аппаратуры целиком. В FPGA, однако, можно достичь параллелизма тиражированием только той логики, которая характерна для данного алгоритма. ПЛИС, которые содержат в кристалле до 7 процессоров различного назначения, неэквивалентны типовой гетерогенной структуре. Множественный доступ к разнообразной периферии – узкое место в плане производительности.
В общем случае архитектура современных систем влечет за собой сочетание разнородных программных сред, таких как ОС Linux, фрагменты, работающие в режиме реального времени под RTOS, или «голое железо». Все это должно сосуществовать на гомогенных или гетерогенных ядрах.
Все эти предпосылки были необходимы для появления языка OpenCL. Также неизбежно в дальнейшем и расширение языка для проектирования динамических систем, изменяющих свою платформу в процессе работы. Требуется сохранение с некоторыми расширениями языка С со сходным синтаксисом, использующим как подмножество старую программную модель в качестве основной САПР типа CUDE, SD Accell и т. д. Необходимо сохранение и расширение механизмов ссылок из С++ и SystemVerilog.
2. ДИЗАЙН OPENCL
ПринципыдизайнаOpenCLбазируютсяна4-х моделях, на которых идержится стандарт: модель платформы, модель исполнения, модель памяти и модельпрограммирования[6], [7].СозданныенаOpenCLпрограммыиспользуют имеющиеся ресурсы вычислительной системы следующим образом:
−определить ресурсы гетерогенной системы и выбрать подходящие;
−создать последовательность инструкций (очередь), которые будут выполняться на ресурсах;
−подготовить начальные данные для вычислений;
−заставить ресурсы выполнить OpenCL-инструкции, обрабатывающие подготовленные данные;
−собрать результаты вычислений.
5

2.1. Модель платформы
Модель платформы дает высокоуровневое описание гетерогенной системы [4], [6]. Центральным элементом данной модели выступает понятие хоста – первичного устройства,которое управляетOpenCL-вычислениями иосуществляет все взаимодействия с пользователем. Хост всегда представлен в единственном экземпляре, в то время как OpenCL-устройства могут быть представлены во множественном числе. OpenCL-устройством может быть любой процессор в системе, поддерживающийсяустановленными в ней OpenCLдрайверами. OpenCL-устройства логически делятся моделью на вычислительные модули, которые, в свою очередь, делятся на обрабатывающие элементы.
Рис. 2.1. Схематическое представление OpenCL-платформы
Вычисления на OpenCL-устройствах в действительности происходят на обрабатывающих элементах. На рис. 2.1 схематически изображена OpenCLплатформа из трех устройств.
2.2. Модель вычислений
Модель вычислений описывает абстрактное представление того, как потоки инструкций выполняются в гетерогенной системе [4], [6].
С хостом неразрывно связано понятие хостовой программы – программного кода, выполняющегося только на хосте. OpenCL не указывает, как именно должна работать хостовая программа, а лишь определяет интерфейс взаимодействия с OpenCL-объектами. С точки зрения модели вычислений OpenCL-приложение состоит из хостовой программы и набора ядер. OpenCLядро в общем виде представляет собой функцию, написанную на языке OpenCL C и скомпилированную OpenCL-компилятором.
6
Ядра создаются в хостовой программе и затем с помощью специальной командыставятсявочередьнавыполнение.Вовремявыполненияупомянутой команды OpenCL Runtime System создает целочисленное пространство индексов, каждый элемент которого носит название глобального идентификатора. Каждый экземпляр ядра выполняется отдельно для каждого значения глобального идентификатора. Экземпляр ядра носит название work-item. Множество всех work-item разбивается на группы. Такая группа носит название workgroup. Все work-item в одной work-group идентифицируются уникальным в пределах своей группы номером – local ID и выполняются параллельно на обрабатывающих элементах одного вычислительного модуля OpenCL-устрой- ства. Это гарантируется стандартом, в то время как совершенно не гарантируется, что несколько work-item из разных групп будут выполнены параллельно.
Другим важным понятием модели вычислений является контекст, определение которого является первой задачей OpenCL-приложения. Контекст определяет среду выполнения ядер, в которую входят следующие компоненты: устройства, сами ядра, программные объекты, объекты памяти. Взаимодействие между хостом и OpenCL-устройством происходит посредством команд, помещенных в командную очередь. Данные команды ожидают в командной очереди своего выполнения на OpenCL-устройстве. Командная очередь создается хостом и сопоставляется одному OpenCL-устройству после того, как будет определен контекст. Команды делятся на те, что отвечают за выполнение ядер, управление памятью и синхронизацию выполнения команд в очереди. Команды могут выполняться последовательно или внеочередно (поддерживается не всеми платформами).
2.3. Модель памяти
Модель памяти описывает набор регионов памяти и манипулирование ими во время проведения вычислений [4], [6].
OpenCL-объекты, инкапсулирующие регионы памяти, имеют название объектовпамяти. Объектыпамятиделятся на 2 типа: буферные объекты иобъекты изображения. Буферные объекты памяти инкапсулируют непрерывные участки памяти, доступные ядрам во время выполнения. Объекты изображений ограничены хранением изображений.
Ядрам в OpenCL доступно 5 видовпамяти:памятьхоста, глобальная, константная, локальная и приватная [4]. На рис. 2.2 показаны отношения между перечисленными регионами памяти согласно стандарту OpenCL.
7
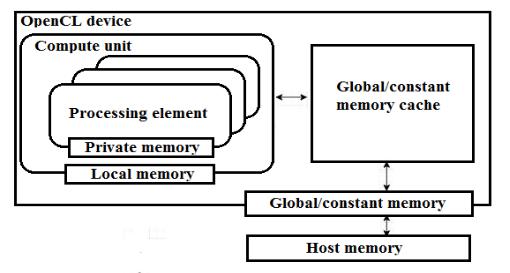
Рис. 2.2. Схематическое представление нескольких уровней памяти в OpenCL
Все рабочие единицы имеют доступ к глобальной памяти на чтение и на запись. Входная информация переносится в глобальную память с хоста, а результаты вычислений из глобальной памяти возвращаются обратно на хост. Константная память доступна всем рабочим единицам, но только для чтения. Выделяется и инициализируется этот вид памяти на хосте. Локальная память – это область памяти, общая для всех рабочих единиц в рамках одной рабочей группы. Посредством нее рабочие единицы группы могут обмениваться информацией друг с другом. Приватная память – область памяти для локальных переменных экземпляров ядра.
2.4. Модель программирования
Модель программирования описывает варианты переноса абстрактного алгоритма на гетерогенные вычислительные ресурсы [4], [6].
OpenCL определяет два типа модели программирования: параллелизм по данным и параллелизм по заданиям.
Параллелизм по данным. Данный тип модели программирования организован вокруг структур данных: каждый элемент определенной хостом структуры данных обновляется одновременно (параллельно) копиями одного и того же OpenCL-ядра. Дизайн такой структуры должен поддерживать возможность одновременного изменения различных ее частей. Модель параллелизма по данным наиболее естественная модель программирования для OpenCL.
Параллелизм по заданиям. В стандарте OpenCL под заданием понимается ядро, выполняемое как единственный work-item. При этом вместе с таким заданием в устройстве могут одновременно выполняться и другие work-item.
8