

Лекции / 5
.pdf§. Структуры и формирование баз данных.
База данных (БД) – это хранилище данных в виде записей. Записи представляют собой экземпляры структур, аналогичных структуре типа struct в С++.
Структура на языке С++:
struct STUDY_RESULTS
{ |
|
char name[20]; |
/* Имя */ |
char surname[20]; /* Фамилия */ |
|
char group [20]; |
/* Номер группы */ |
int score; |
/* Оценка за экзамен */ |
}; |
|
Экземпляр структуры вводится так:
STUDY_RESULTS Leonid_Kovalenko;
Leonid_Kovalenko.name = ...;
Leonid_Kovalenko.surname = ...;
Leonid_Kovalenko.group = ...;
Leonid_Kovalenko.score = ...;
На языке ПРОЛОГ структура вводится как сложный (составной) терм с помощью указания её
функтора и компонентов в следующем виде: функтор(компонента-1, ...., компонента-N)
где в качестве функтора должен выступать атом, а компонентой может быть любой терм (в том числе и структура). Число компонент в структуре называется арностью структуры.
В качестве компонента структуры также может выступать структура.
Пример 1 формирования записи:
DOMAINS name,surname,group = string score = integer PREDICATES
record(name,surname,group,score) CLAUSES record("Leonid","Kovalenko","IKPI-85",5).
Пример 2 формирования записи:
DOMAINS
pres_descr = pres(name,party,state,birth_year) name,party,state = symbol birth_year,year_in,year_out = integer PREDICATES president(pres_descr,year_in,year_out) CLAUSES
president(pres(kennedy,democrat,massachussetts,1917),1961,1963).
Сформированные записи составляют базу данных. Как было указано в прошлой лекции, существуют три модели БД:
−сетевая;
−иерархическая;
−реляционная.
Вкратце рассмотрим каждую из моделей для понимания ее сути.
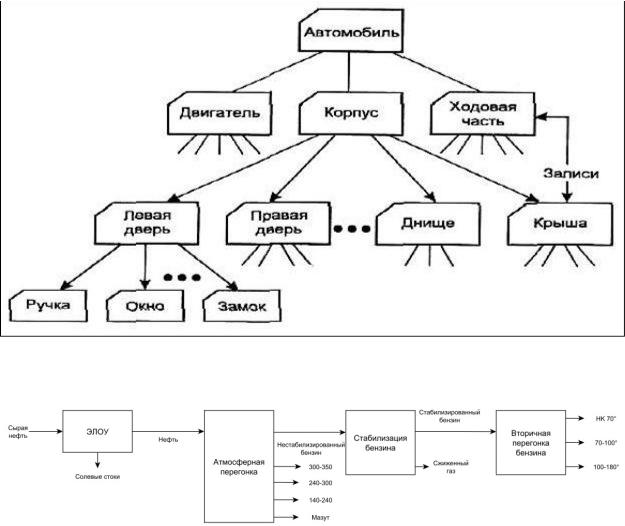
Иерархическая модель заключается в формировании связей между записями в виде дерева с вводом соотношений типа родительский элемент – дочерний элемент. Такой подход вначале казался довольно удобным для представления выпускаемых изделий, например, автомобиля, который в крупноузловом масштабе может быть представлен, в частности, двигателем, корпусом (кузовом) и ходовой частью (подвеской), которые в свою очередь включают в себя более мелкие компоненты.
Такая схема хорошо подходит в том числе для изображения производственного процесса, например, нефтепереработки. В крупноузловом виде система включает в себя четыре блока:
каждый из которых, в свою очередь, содержит целую серию таких компонентов, как фильтры, насосы, теплообменники и другие устройства.
На иерархической модели базируются такие системы, как IBM IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.
Для доступа к конкретным данным записи в иерархической системе необходим последовательный перебор элементов, начиная с корневого узла. Для изменения данных необходимо изменить всю ветвь или само дерево, то есть иерархическая модель локализована под конкретный процесс.
Каждый элемент иерархической модели связан только с одним стоящим выше элементом, но при этом на него могут ссылаться один или несколько стоящих ниже элементов. Такая схема не всегда удобна и часто избыточна. Например, если в различных узлах автомобиля используются 300 болтов одного типа, вместо 1 записи будут созданы 300 дублирующих друг друга записей. Для устранения этого недостатка была введена сетевая модель представления данных.
Всетевой модели:
отсутствует понятие главного и подчиненного объекта;
один объект может выступать как главный и как подчиненный, то есть иметь любое количество взаимосвязей (одна запись может участвовать в нескольких отношениях предок-потомок);
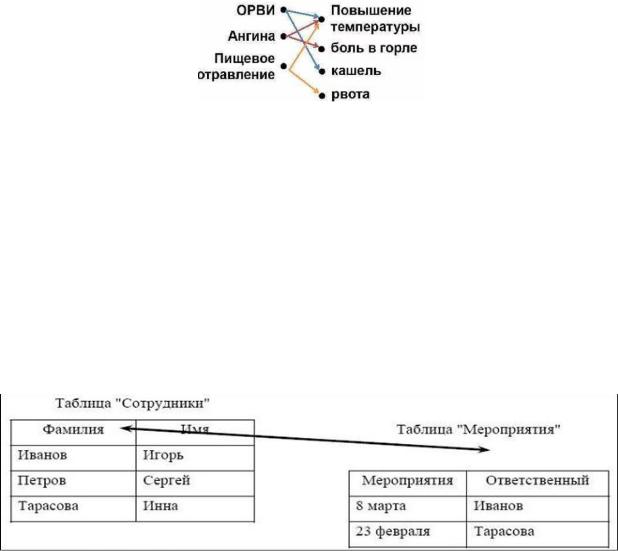
допустимы связи между объектами на одном уровне.
Т.е. фактически, база данных представляет собой не дерево, а граф.
Примеры сетевых СУБД: CODASYL, DBMS, IDMS, TOTAL, VISTA, СЕТЬ, СЕТОР, КОМПАС.
Искать элемент в такой базе данных непросто из-за сложности определения маршрута. Поэтому СУБД с такой моделью представления данных сложны в реализации и ресурсоемки.
В реляционной модели все данные сгруппированы в таблицы, в которых строки – это записи, а столбцы – поля записей. Для однозначного перехода к конкретной записи в каждой строке есть так называемый первичный ключ, который фактически является уникальным идентификационным номером записи. Этот ключ вводится или явным образом в отдельном столбце, или неявно, то есть автоматически самой СУБД (например, в СУБД Oracle у любой таблицы есть скрытый столбец ROWID с уникальным адресом каждой строки).
Отношения родительский элемент – дочерний элемент в реляционных БД реализуются при помощи внешних ключей. Внешний ключ – это столбец таблицы, значения которого совпадают со значениями первичного ключа другой таблицы.
Пример внешнего ключа:
Поле «Ответственный» таблицы «Мероприятия» является внешним ключом для таблицы «Сотрудники» (первичный ключ – столбец «Фамилия»).
В таблицах реляционной базе данных в качестве признака отсутствующего значения используется значение NULL. Вместо NULL нельзя использовать 0 или пробел: отсутствие информации по полю «Возраст» не означает то, что человеку 0 лет. По причине возможного размещения NULL в разных полях разных записей ни одно значение NULL не равно другому значению NULL.
Расширением реляционной модели является объектно-реляционная модель, которая сочетает в себе реляционную модель данных с концепциями объектно-ориентированного программирования (полиморфизмом, инкапсуляцией, наследованием).
Основными понятиями реляционных баз данных являются атрибут, домен, схема отношения, кортеж, отношение.
Атрибут – это наименьший именованный элемент данных, имеющий имя и значение. Фактически речь идет об поле записи и его значении. В Прологе атрибут – это терм.
Домен – это допустимое множество значений заданного типа. Это множество определяется произвольным логическим выражением, применяемым к элементу указанного типа. Если это выражение истинно, то элемент данных является элементом домена. Например, к домену Names на базе типа string могут относиться не все строки, а только те, которые начинаются с буквы (не с точки, запятой и так далее), и этой буквой не должен быть мягкий или твердый знак. Домен вводится тогда, когда нужно ограничить допустимое множество значений в рамках указанного типа данных.
Схема отношения – это именованный набор заголовков полей записи. Степень схемы отношения – то же самое, что и арность. Структурная схема базы данных – это набор схем отношений.
Кортеж – это запись (строка) в таблице, которая определена с точностью до соотношений (имя атрибута, значение) и содержит одно вхождение каждого имени атрибута, принадлежащего конкретной схеме отношения. Значение должно соответствовать типу данных или домену.
По сути своей кортеж – это набор именованных значений заданного типа. В Прологе кортеж – это факт.
Отношение - это множество кортежей, соответствующих одной схеме отношения. В Прологе отношение – это предикат базы данных.
Имеет место следующее соответствие терминов:
База данных |
Набор таблиц |
Атрибут |
Столбец таблицы |
Схема отношения |
Набор заголовков таблиц |
Кортеж |
Строка таблицы |
Отношение |
Таблица |
Арность отношения |
Количество столбцов таблицы |
Мощность отношения Количество строк таблицы
Полезно также понимать ключ как атрибут или набор атрибутов, значение которого однозначно идентифицирует кортеж. Отношение может иметь несколько ключей, но всегда один из ключей объявляется первичным и его значения не могут обновляться. Все остальные ключи называются возможными ключами. Атрибуты, представляющие собой копии ключей других отношений, являются внешними ключами.
База данных в Прологе содержит набор отношений, которые могут быть определены явно (фактами) и неявно (правилами). Механизм формирования базы данных рассмотрен на прошлой лекции. Доменные имена аргументов предиката базы данных должны быть объявлены в секции domains. Сами предикаты базы данных по умолчанию должны быть описаны в разделе database. В этом случае факты, введенные с помощью таких предикатов, помещаются в область оперативной памяти, которая называется внутренней базой данных и имеет имя dbasedom. При необходимости после стандартного раздела database, связанного с базой данных dbasedom, можно добавить разделы типа:
database – myBase
Пример.
DOMAINS
name, role, team = string DATABASE - lineup player(name,role,team) FACTS
candidate(name) CLAUSES
player("Dzuba","Forward","Zenit"). player("Ronaldo","Forward","Juventus"). candidate("Kokorin"). candidate("Kuzyaev").
Факты, объявленные в секции facts, автоматически добавляются во внутреннюю базу данных dbasedom. Поэтому секция database, которая используется в программе вместе с секцией facts, обязательно должна быть именованной.
Все различные утверждения внутренней базы данных составляют динамическую базу данных (ДБД). В статической базе данных утверждения представлены фактами и являются частью кода программы.
Дополним материал предыдущей лекции. Для добавления в базу данных используются следующие предикаты:
asserta(fact) // добавление в начало базы данных dbasedom
asserta(fact, dbaseName) // добавление в начало базы данных dbaseName
assertz(fact) // добавление в конец базы данных dbasedom
assertz(fact, dbaseName) // // добавление в конец базы данных dbaseName
Загрузка фактов из файла:
consult(fileName) // загрузка в базу данных dbasedom consult(fileName, dbaseName) // загрузка в базу данных dbaseName
Удаление факта
retract(fact) // удаление из базы данных dbasedom
retract(fact, dbaseName) // удаление из базы данных dbaseName
Сохранение базы данных в файле
save(fileName) // сохранение базы данных dbasedom в файле fileName save(fileName, dbaseName) // сохранение базы данных dbaseName в файле fileName