

Лекции / 2
.pdfКлассификация языков программирования
Рисунок 1 — Классификация языков программирования Процедурные языки программирования.
Программа (решение задачи) на процедурном языке программирования состоит из строго упорядоченной последовательности инструкций (шагов).
Ключевым показателем процедурного языка является его уровень близости к машинному коду. Все процедурные языки разделяются на языки низкого и высокого уровней:
1. Низкий уровень.
Процессор характеризуется набором поддерживаемых ему команд. Если язык программирования ориентирован на конкретный тип процессора (на конкретные его команды), то он называется языком программирования низкого уровня.
Самый низкий (нулевой) уровень имеет машинный код, который представляет собой набор кодов операций конкретной вычислительной машины.
Языки низкого уровня (машинно-ориентированные / машинно-зависимые языки) позволяют создавать программу из машинных кодов, обычно представляемых для удобства в виде шестнадцатеричной формы. При правильном (но трудоемком) программировании на языках низкого уровня получаются очень эффективные (по скорости и по размеру, занимаемому в
оперативной памяти) и компактные (по размеру на диске) программы, так как разработчик получает доступ ко всем возможностям процессора.
С помощью этих языков разрабатывают системные программы и драйверы (программы для управления устройствами компьютера).
Ассемблер — язык низкого уровня. Команды машинного кода записываются в виде условных обозначений, называемых мнемониками.
2. Высокий уровень.
Человеческий язык не относится к процедурным языкам программирования, хотя некоторые считают, что он имеет самый высокий уровень в иерархии языков программирования.
Код на языке программирования высокого уровня в общем случае не имеет командной привязки к аппаратным ресурсам, поэтому легко переносим на другие платформы, для которых поддерживается транслятор этого языка.
Работа всех трансляторов строится либо по принципу интерпретации, либо по принципу компиляции.
Интерпретатор — системная программа, которая транслирует каждую инструкцию исходной программы в промежуточный код, интерпретирует его посредством одной или нескольких команд и выполняет эти команды.
В отличии от компилятора, интерпретатор не генерирует объектный код, а выдает результат работы выполняемых инструкций исходной программы.
Существуют следующие основные недостатки метода интерпретации:
1.Интерпретирующая программа должна находиться в памяти ЭВМ в течение всего процесса осуществления исходной программы. То есть она должна занимать некоторый объем памяти;
2.Процесс трансляции одного и того же оператора повторяется столько раз, сколько должна исполняться эта команда в программе. Это является причиной резкого снижения производительности работы программы.
Компилятор — системная программа, которая переводит текст программы на языке высокого уровня (исходный модуль) в машинный код (объектный модуль). Для такого перевода нужен неоднократный «просмотр» текста
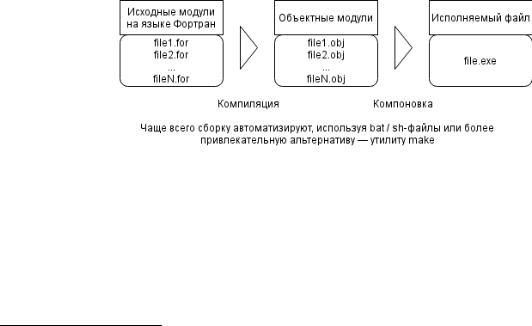
программы: сначала лексический анализ, затем синтаксический, потом семантический, и только после этого выполняется генерация кода.
Объектные модули содержат блоки машинного кода и данных с неопределенными адресами ссылок на процедуры и данные в других объектных модулях, а также список своих процедур и данных. Эти блоки могут быть объединены при помощи редактора связей (компоновщика) для получения готового исполнимого модуля (например, com или exe) либо библиотеки (например, динамической dll, но не статической lib1), которые представляют собой машинные инструкции для конкретного процессора. Компоновщик собирает код и данные каждого объектного модуля в итоговую программу, вычисляет и заполняет адреса перекрестных ссылок между модулями. Связывание со статическими библиотеками выполняется компоновщиком, а с операционной системой и динамическими библиотеками связывание выполняется при исполнении программы, после её загрузки в память.
Объектный модуль состоит из двух частей:
1.Заголовок, содержащий внешние имена (имена переменных, используемых в данном модуле, но определенных в других модулях).
2.Тело модуля, которое представляет собой программу в кодах команд конкретной ЭВМ.
Рисунок 2 — Компиляция и компоновка Наряду с рассмотренными выше интерпретаторами и компиляторами на
практике также используются смешанные трансляторы («интерпретаторыкомпиляторы»), которые сочетают в себе достоинства обоих механизмов: на этапе разработки и отладки программы транслятор работает в режиме
1Так как статическая библиотека может представлять собой либо файл с исходным кодом, либо объектный модуль, но не исполняемый модуль.
интерпретатора, а после завершения процесса отладки исходная программа повторно транслируется в объектный модуль методом компиляции. Это позволяет значительно упростить процесс разработки и отладки программ. А за счет последующего получения объектного модуля позволяет обеспечить более эффективное выполнение программы.
Классическое процедурное программирование требует от программиста детального описания того, как решать задачу, т. е. формулировки алгоритма и его запись.
В отличие от процедурного, объектно-ориентированный язык создает окружение в виде множества объектов. Объектно-ориентированный язык не описывает пошаговую последовательность инструкций для выполнения поставленной задачи, хотя и содержит элементы процедурного программирования. Программа записывается в процедурах обработки событий, которые привязаны к объектам. Обладающие указанными свойствами и определенным поведением объекты обмениваются сообщениями. (Под сообщением подразумевается пакет данных.)
При использовании декларативного языка программист указывает исходные информационные структуры, взаимосвязи между ними и то, какими свойствами должен обладать результат.
Процедура получения результата в явном виде не формируется. Понятие оператора отсутствует.
Декларативные языки:
—Логические языки (Prolog, Planner);
—Функциональные языки (Haskell, Lisp, Erlang).
Программа на функциональном языке описывает вычисления некоторой функции как композиции (сочетания) других (более простых) функций.
Одним из основных элементов функционального языка является рекурсия, т. е. вычисление значения функции через значение этой функции по другим элементам.
Программа на логическом языке не описывает действий, а создает данные и соотношения между ними. После этого системе можно задавать вопросы / подавать запросы.
Программа перебирает известные, заданные в программе, данные и находит ответ на поставленный запрос. Порядок перебора не описывается в программе, а неявно создается самим языком.
Построение логической программы не требует алгоритмического мышления. Программа описывает статические соотношения объектов, а динамика заключается в механизме перебора и скрыта от программиста.
Логические и функциональные языки называются декларативными (непроцедурными), поскольку программа представляет собой не набор команд, а описание проблемы и ожидаемого результата.
Фактически программист оперирует не набором инструкций, а абстрактными понятиями, которые могут быть достаточно обобщенными.
На начальном этапе развития декларативные языки были слабо конкурентоспособными при сравнении с императивными в силу объективных проблем с реализацией трансляторов. Программы работали медленнее, но при этом могли решать более абстрактные задачи с меньшими затратами.
Код на процедурном языке программирования последовательно меняет значения набора переменных, который называется состоянием. Если в начале работы программы имеет место начальное состояние X0, то в конце работы формируется конечное состояние Xm и множество состояний образуют конечную последовательность значений. Состояния меняются с помощью команд присваивания новых значений, записываемых в виде y=f или y:=f, где y — переменная, а f — выражение. Команды выполняются одна за другой в определенном порядке. Операторы сравнения (if, switch) и циклические конструкции (for, while, do-while, repeat-until) позволяют изменить порядок выполнения этих команд в зависимости от текущего значения состояния. Такая концепция называется процедурной или императивной.
В отличии от императивной концепции программа на функциональном языке представляет собой выражение, а выполнение программы означает вычисление значения (редукцию) этого выражения.
Таким образом, конечное состояние как и любое промежуточное состояние представляет собой определенную функцию от начального состояния.
У функциональных программ есть следующие особенности:
1.Нет состояний, поэтому нет изменяемых переменных.
2.Нет присваивания.
3.Нет циклов.
4.Последовательность команд не имеет значения, так как выражения независимы друг от друга.
5.Одни функции можно передавать в другие функции в качестве аргументов и возвращать в качестве результата, а также можно выполнять вычисления, результатом которых будет функция.
6.Вместо циклов используются рекурсивные функции.
Пример вычисления факториала на языке Haskell:
factorial n = if n == 0 then 1 else n * factorial(n - 1)
Функции в императивных языках чаще всего не являются функциями в математическом смысле, так как:
1.Их значения могут зависеть не только от аргументов, но и от внешних (возможно, глобальных) переменных.
2.Их выполнение может привести к различным побочным результатам. Например, к изменению значения глобальной переменной. Или, например, два вызова одной и той же функции с одними и теми же аргументами могут привести к различным результатам.
Функция в функциональных программах действительно является функцией в математическом смысле. Вычисления любого выражения не имеют побочных эффектов, а порядок вычислений его подвыражений не влияет на результат.
Так как отдельные компоненты одного выражения могут вычисляться одновременно, функциональные программы удобны для кластеризации и последующего распараллеливания.
Типы алгоритмов
Типы алгоритмов:
1.Жадные алгоритмы. Идеальным вариантом можно считать алгоритм, который способен выбрать из нескольких решений единственно правильное. В основе этого подхода лежит принцип разделения, но в каждой точке алгоритм имеет основание для выбора одной из подзадач. Обычно это делается с учетом особенности организации обрабатываемых данных или их избыточности.
Пример жадного алгоритма: бинарный поиск в упорядоченных данных. Основой жадных алгоритмов является не всегда эффективный принцип
движения по линии наименьшего сопротивления к желаемому результату.
2.Полный перебор (исчерпывающий / комбинаторный перебор).
3.Динамическое программирование. В процессе порождения дерева рекурсивных вызовов возможно повторение подзадач с одними и теми же данными.
Если запоминать результат их выполнения, то эффективность алгоритма может значительно увеличиться.
Основная идея (концепция) динамического программирования — запоминание результатов решения повторяющихся подзадач, возникающих при поиске методом полного рекурсивного перебора с получением задач меньшей размерности.
В частности, при динамическом программировании вычисляется решение для всех подзадач. Вычисление идет от малых подзадач к большим, и ответы запоминаются в таблице. Преимущество этого метода состоит в том, что раз уж задача решена, ее ответ где-то хранится и никогда не вычисляется заново.
Далее следует лекция №3.