

2064
.pdfЕсли число образов больше двух (H1, H2, …, Hn) и каждый образ описывается вектором признаков (x1, x2 ,…., xn), а платежная матрица
C11... CN1
C |
, |
C2n... CNn
то риск определяется выражением
R P(Hi )Cki |
Pi (x)dx, |
k 1 i 1 |
Dk |
где P(Hi ) – априорная вероятность |
появления класса Hi ; Dk – |
область в N-мерном пространстве, описывающая k-й класс. Граница в пространстве признаков между областями Dk и Di, используя которую при принятии решений обеспечиваем минимум среднего риска
P(Hk ) Pk (x/ Hk )(Cki Ckk ) P(Hi ) Pi (x/ Hi )(Cik |
Cii ) 0. |
Пусть Pi (x/ Hi )– функция плотности |
многомерного |
нормального закона распределения со средним вектором
математического |
ожидания mi и корреляционной матрицей |
Ki |
. |
|||||||||||||||||||
Тогда граница областей может быть найдена из уравнения |
||||||||||||||||||||||
ln |
P(Hk ) |
|
1 |
ln |
|
|
Kk |
|
|
|
1 |
(x mk )T |
|
Kk |
|
1(x mi )T |
|
Ki |
|
1(x ml ) 0. |
||
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
||||||||||||||||||
|
P(Hi ) 2 |
|
|
Ki |
2 |
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
(2.1) |
|
|
|
|
|
|
|
|
||||||
Известно много процедур принятия решений, являющихся частными случаями рассмотренного алгоритма: правило минимакса, стратегия Неймана-Пирсона и др.
Интерес представляют также так называемые геометрические методы распознавания, основанные на вычислении меры близости описания неизвестного объекта к хранящимся в памяти эталонам. Они также являются частными случаями байесовой стратегии и
31

используются в тех случаях, когда корреляционная матрица в (2.1) содержит только диагональные элементы. В результате решающее правило вырождается в оценку расстояний между признаками предъявленного образа и эталонов. Пусть, например, требуется провести распознавание n объектов в пространстве N признаков. Эталоны строятся в виде таблицы размером n×N, причем на пересечении i-й строки и j-го столбца записывается среднее значение j-го признака i-го образа mij. На этапе распознавания вычисляются текущие значения признаков предъявленного образа. Затем находятся расстояния между этими параметрами и эталонами. По минимуму этих расстояний выносится решение о принадлежности входного образа к определенному классу. Достаточность выбранных признаков оценивается по критерию Фишера
(mkj mlj )2 ,
k2 j l2j
где mkj – средние значения i-го признака; и l2j – дисперсии значения i-го признака.
Ясно, что по сравнению с базовой байесовой стратегией распознавания геометрические методы пригодны в случае слабопересекающихся собственных областей образов.
В читающих автоматах получил распространение метод «масок». Метод состоит в наложении эталонов подписи («маски») на исследуемое изображение и сопоставлении эталонных изображений с исследуемым. Различают неподвижные «маски», «маски» с переменным положением относительно координатных осей, вращающиеся относительно неподвижного или смещающегося центра. При смещениях и поворотах входных образов требуется двигать «маску», поворачивая ее при каждом новом положении на дискретные углы в пределах от 0 до 360º. При размерах изображения n×n эталона m×m, числе дискретов р угла поворота число элементарных логических операций сравнения
элементов составит (n m)2 m2 p. При n=100; m=100; р=100 число сравнений составит 256·106. Это достаточно обременительная операция для вычислительного устройства.
32

Если изображения объектов могут только смещаться (но не вращаться), используется технология с применением булевых операторов.
Пусть задано произвольное изображение Bi j , имеющее конфигурации Q1, Q2 ,...,Qn . Они сопоставляются с эталонной конфигурацией Qэ . Для точек эталонной конфигурации задаются координаты относительно произвольной фиксированной точки (i0 , j0 ). Обозначим их ,t э . Другой набор точек характеризует фон
,t ф . Применим к каждому элементу входного изображения операцию вида
B(i, j) & |
a(i ), j t) & a(i ), j t) . |
( ,t)э |
( ,t)Ф |
(2.2) |
|
Если ( ,t) соответствует всем точкам изображения образа, а
,t ф – всем точкам его фона, выражение (2.2) задает одну из разновидностей «масок», требующую точного совпадения эталона с входной конфигурацией. Другие варианты получаются при применении положительных весов совпадающим элементам и отрицательных – несовпадающим и определении суммарного веса путем сложения при каждом сдвиге эталона относительно исследуемого изображения.
На практике используется неполное множество элементов ,t э и ,t ф . Достигаемая цель – упрощение процедуры распознавания. Среди множества подходов, предложенных для решения такой задачи, наиболее простым представляется следующий.
Вводятся понятия внутреннего и внешнего контуров изображения анализируемой конфигурации. Под внутренним контуром понимается множество таких элементов конфигурации
a(i, j), |
что хотя |
бы для |
одного |
из соседних элементов |
a(i 1, |
j 1) 0. Для |
внешнего |
контура |
a(i, j) Q выполняется |
условие a(i 1, j 1) 1 хотя бы для одного из соседних элементов. Если принять ,t э за точки внутреннего контура, а ,t ф – за точки внешнего контура, тогда в соответствии с (2.2) выделяются конфигурации, у которых внешний и внутренний контуры
совпадают |
с |
эталонными. |
Следовательно, |
применение |
|
|
|
33 |
|
рассмотренного алгоритма возможно только для нормированных пространств, и в рассматриваемом приложении необходимо вводить операцию геометрического нормирования пространства признаков.
Какому из рассмотренных алгоритмов отдать предпочтение при решении поставленной задачи?
Сточки зрения «здравого смысла» выбор должен быть сделан
впользу байесовой стратегии выбора гипотез. Другие алгоритмы работают не с полной информацией, поступающей на вход решающего устройства. При получении неудовлетворительных результатов идентификации сохраняется неопределенность: либо исходная информация недостаточна, чтобы распознать требуемое множество образов; либо все дело в использовании неэффективного алгоритма.
Однако использование байесовой идеологии принятия решений требует построения многомерных условных плотностей вероятностей для описания идентифицируемых классов. Теоретически решение такой задачи возможно, практически исследователь втягивается в трудоемкий по постановке эксперимент, требующий наличия огромных вычислительных ресурсов и времени. Представляется целесообразным ввести системные ограничения на этапе построения эталонов идентифицируемых образов, естественно позаботившись об обоснованности введения таких ограничений.
Врамках таких ограничений получили распространение три варианта алгоритмов распознавания (идентификации) образов, основанных на использовании «принципа накопления вероятностей», формулы гипотез Байеса, общей теоремы о повторении опытов.
Для пояснения сущности этих алгоритмов обратимся к рис.2.3, на котором изображена структурная схема системы распознавания (идентификации) образов.
На начальном этапе ее функционирования идет процесс обучения. Учитель последовательно генерирует образы класса i. По совокупности m реализаций каждого i-го класса для всех его признаков j строится описание в виде плотностей распределения
вероятностей P(Hi / xj ). Необходимое количество реализаций m
оценивается по известным формулам теории вероятностей и математической статистики исходя из принятого уровня
34
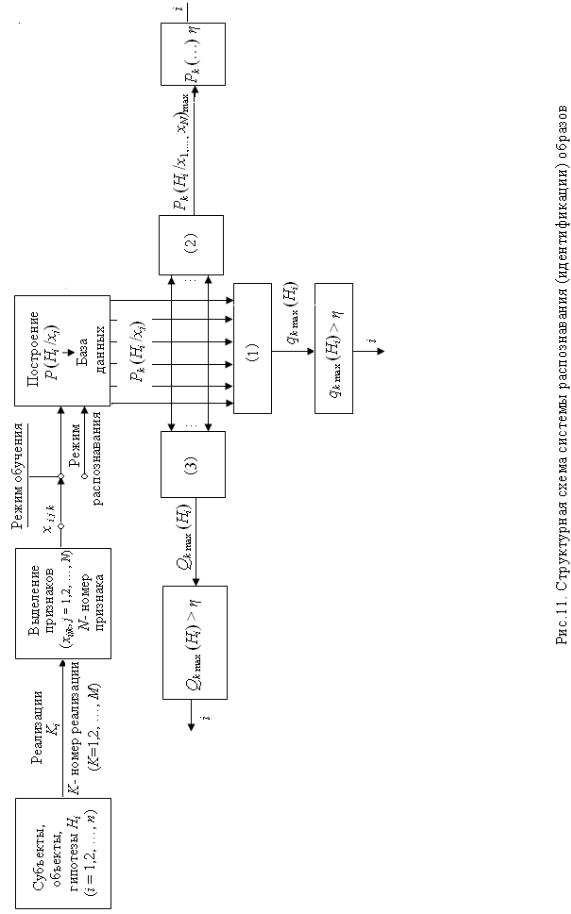
достоверности оценок моментов распределения P(Hi / xj ). После формирования базы данных P(Hi / xj ) для всех классов i и признаков j (n×N описаний) система переводится

в режим идентификации, реализующий один из следующих алгоритмов. 2.3
Алгоритм основан на принципе накопления вероятностей.
Согласно ему идентифицируемый объект |
(гипотеза Hi ) |
|
описывается признаками xi j |
и соответствующими апостеорными |
|
плотностями распределения |
вероятностей |
P(xj / Hi ) . При |
поступлении k-й реализации на вход системы формируется набор
вероятностей |
Pk (xj / Hi ) . |
Первой |
гипотезе |
соответствуют |
||
вероятности |
Pk (x1 / H1), |
… |
, Pk (xj |
/ H1) , … |
,Pk (xN / H1) , i-й: |
|
Pk (x1 / Hi ) , … , Pk (xj / Hi ) , … |
и т.д. Имеем матрицу вероятностей: |
|||||
|
|
Pk (x1 /H1) Pk (xj /H1) Pk (xN /H1) |
|
|||
|
|
|
||||
|
|
. . . . . . . . . . . . . . . . . . . . . . . . . |
|
|||
|
|
Pk (x1 /Hi )...Pk (xj /Hi )... |
Pk (xN /Hi ) |
|
||
|
|
. . . . . . . . |
. . |
. . . . . . . |
. . . . . . . . |
|
|
|
Pk (x1 /Hn)...Pk (xj /Hn) Pk (xN /Hn)... |
|
|||
По данным матрицы формируется обобщенная оценка вероятности гипотез после обработки k-й реализации:
N
Pk (xj / Hi )
qk (Hi ) |
1 |
|
N n |
Pk (xj / Hi )
j 1 i 1
(2.3)
Решение о номере идентифицируемого образа, т.е. i, принимается по максимальному значению qk max (Hi ) по его превышению установленного уровня η.
Другой алгоритм принятия решений базируется на использовании модифицированной формулы гипотез Байеса
36
Pk (Hi / xj ) |
P( i j ) P(xj |
/ Hi) |
|
|
|
, |
|
n |
|
||
|
P( i j ) P(xj / Hi) |
||
(2.4) |
i 1 |
|
|
|
|
|
|
где P(xj / Hi ) – апостериорные вероятности |
гипотез Нi при |
||
величине признака xj;P( i j ) – априорная вероятность i-й гипотезы при поступлении j-го признака. Если она неизвестна, принимается
P( i1 ) n 1 при j=1;
|
P( i2 ) 0,5 P( i1) P(Hi / x1) при j=2; |
|
|
P( i j ) P(Hi / xj 1) P(Hi / xj 2 ) ... P(Hi / xj m ) |
m 1 |
P(Hi / x ). |
|
|
|
|
i m |
|
m |
|
j 1 |
При поступлении первого признака х1 в систему распознавания априорные вероятности гипотез принимаются одинаковыми, т.е. п-1. На следующем шаге эти вероятности формируются с учетом начальных данных (п-1) и вероятностей гипотез на предыдущем шаге. Учет предыстории определяется параметром т, значение которого в конкретной задаче подбирается экспериментально по дисперсии колебаний вероятности правильной гипотезы.
Третий алгоритм основан на использовании общей теоремы о повторении опытов. Согласно этой теореме вероятность того, что событие Нi в N независимых опытах появится d раз, равна коэффициенту при zd в выражении функции
N
N i (z) (qi j Pi j z), j 1
где qi j 1 Pi j ; Pi j – вероятность i-й гипотезы поступлении j-го признака. Коэффициент при z0 есть вероятность P0N того, что
37
рассматриваемая гипотеза не верна. Тогда с вероятностью Q0N 1 P0N она принимается соответствующей действительности.
Для оценки эффективности рассмотренных алгоритмов проще всего использовать технологию вычислительного эксперимента. С учетом того, что характер зависимостей P(xj / Hi ) для конкретных задач отличается, получаемые оценки эффективности будут различными для разных приложений.
В заключение рассмотрим две частные задачи. Первая из них характерна для области робототехники и в упрощенном виде сводится к комбинации «обнаружение-распознавание» двух классов изображений объектов на фоне помех. В качестве объектов первого класса примем пятна с круговой симметрией разных размеров, во второй класс отнесем протяженные или «нитевидные» объекты. Трудность решения данной задачи резко возрастает при соизмеримости дисперсии помех с контрастом объектов на изображении. При отношении сигнал/помеха меньше двух характеристики распознающей системы становятся неудовлетворительными.
Некоторый прогресс в решении рассматриваемой задачи достигается за счет преобразования изображения с объектом путем суммирования яркостей по снимку в определенном направлении (получение одномерной проекции). Если по изображению установить границы малоконтрастного пятна проблематично, то при анализе «проекции» таких затруднений не возникает.
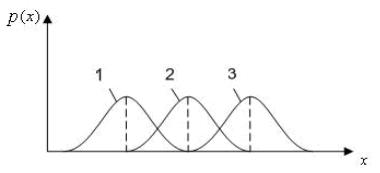
Используемый подход к распознаванию образов поясняет рис.2.4.
Рис. 2.4. Плотности распределения вероятностей признака x для шумов (1), первого класса (2)
и второго (3) класса объектов
38
Плотности распределений вероятностей pi (x) для шумов (1) и объектов разных классов (1), (2) получают обработкой данных, поступающих с датчиков данных. Они отражают особенности изучаемого объекта, характеристики используемой для получения информации аппаратуры, погрешности, неизбежные при
построении графиков |
pi (x). Информация на рис. 2.4 принимается |
||||||
за эталонную. |
|
|
|
|
|
|
|
При работе в автоматическом режиме измеренное значение xj |
|||||||
определяет |
три вероятности |
p1(xj ), |
p2(xj ), p3(xj ). |
Далее |
|||
вычисляются вероятности гипотез p(Hi / xj ): |
|
||||||
|
p(Hi |
/ xj ) |
|
p(Hi ) p(xj |
/ Hi ) |
|
|
|
|
|
|
. |
(2.5) |
||
|
3 |
|
|
||||
|
|
|
p(Hi ) p(xj / Hi ) |
|
|||
|
|
|
i 1 |
|
|
|
|
Формула (2.5) известна как формула гипотез Байеса. |
|||||||
Вероятности |
p(Hi ) |
есть |
априорные |
вероятности |
гипотез |
||
(относительная частота появления i-го класса объектов на конкретном технологическом участке).
Если ни одна из перечисленных гипотез не набрала должного «количества очков», например, 0,9, измеряют значение второго
признака xj 1 и находят оценки p(xj 1 / Hi) (по другим эталонным кривым pi(xj 1)), и вновь рассчитывают вероятности гипотез
p(Hi / xj 1). Однако на этом этапе вместо априорных вероятностей
p(Hi ) используют оценки p(Hi / xj ), полученные на
предшествующем этапе. Процесс продолжается до тех пор, пока не будут исчерпаны выбранные признаки. Гипотеза, вероятность которой оказалась максимальной, принимается за истинную.
Вкачестве примера рассмотрим задачу распознавания образов
ввиде пятен. Изображение пятна полностью находится в поле
зрения автомата. Это изображение с прилегающей областью снимка (микрокадр) обрабатывается путем суммирования яркостей по снимку в определенном направлении (получение одномерной
39

проекции). Если по изображению на снимке установить границы малоконтрастного пятна проблематично, то при анализе «проекции» затруднения не возникают.
На рис. 2.5 показано модельное изображение участка снимка с пятном (а), видеосигнал на строке x (б), проекция сигнала в указанном выше смысле (в). Если по видеосигналу установить границы пятна невозможно, то по «проекции» данная задача решается без затруднений.
Экспериментальные данные, характеризующие эффективность данного подхода, представлены в табл. 2.1.
Рис. 2.5. Иллюстрация эффективности использования метода «проекций» для измерения размеров пятна: а – модельное изображение участка снимка с изображением пятна; б – видеосигнал строчной развертки; в – проекция изображения на ось x
40